 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Large Language Models for Automated Proof Synthesis in Rust
Nov 07, 2023
Formal verification can provably guarantee the correctness of critical system software, but the high proof burden has long hindered its wide adoption. Recently, Large Language Models (LLMs) have shown success in code analysis and synthesis. In this paper, we present a combination of LLMs and static analysis to synthesize invariants, assertions, and other proof structures for a Rust-based formal verification framework called Verus. In a few-shot setting, LLMs demonstrate impressive logical ability in generating postconditions and loop invariants, especially when analyzing short code snippets. However, LLMs lack the ability to retain and propagate context information, a strength of traditional static analysis. Based on these observations, we developed a prototype based on OpenAI's GPT-4 model. Our prototype decomposes the verification task into multiple smaller ones, iteratively queries GPT-4, and combines its output with lightweight static analysis. We evaluated the prototype with a developer in the automation loop on 20 vector-manipulating programs. The results demonstrate that it significantly reduces human effort in writing entry-level proof code.
Learning to Learn for Few-shot Continual Active Learning
Nov 07, 2023Continual learning strives to ensure stability in solving previously seen tasks while demonstrating plasticity in a novel domain. Recent advances in CL are mostly confined to a supervised learning setting, especially in NLP domain. In this work, we consider a few-shot continual active learning (CAL) setting where labeled data is inadequate, and unlabeled data is abundant but with a limited annotation budget. We propose a simple but efficient method, called Meta-Continual Active Learning. Specifically, we employ meta-learning and experience replay to address the trade-off between stability and plasticity. As a result, it finds an optimal initialization that efficiently utilizes annotated information for fast adaptation while preventing catastrophic forgetting of past tasks. We conduct extensive experiments to validate the effectiveness of the proposed method and analyze the effect of various active learning strategies and memory sample selection methods in a few-shot CAL setup. Our experiment results demonstrate that random sampling is the best default strategy for both active learning and memory sample selection to solve few-shot CAL problems.
Leveraging Transformers to Improve Breast Cancer Classification and Risk Assessment with Multi-modal and Longitudinal Data
Nov 06, 2023Breast cancer screening, primarily conducted through mammography, is often supplemented with ultrasound for women with dense breast tissue. However, existing deep learning models analyze each modality independently, missing opportunities to integrate information across imaging modalities and time. In this study, we present Multi-modal Transformer (MMT), a neural network that utilizes mammography and ultrasound synergistically, to identify patients who currently have cancer and estimate the risk of future cancer for patients who are currently cancer-free. MMT aggregates multi-modal data through self-attention and tracks temporal tissue changes by comparing current exams to prior imaging. Trained on 1.3 million exams, MMT achieves an AUROC of 0.943 in detecting existing cancers, surpassing strong uni-modal baselines. For 5-year risk prediction, MMT attains an AUROC of 0.826, outperforming prior mammography-based risk models. Our research highlights the value of multi-modal and longitudinal imaging in cancer diagnosis and risk stratification.
LLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 04, 2023
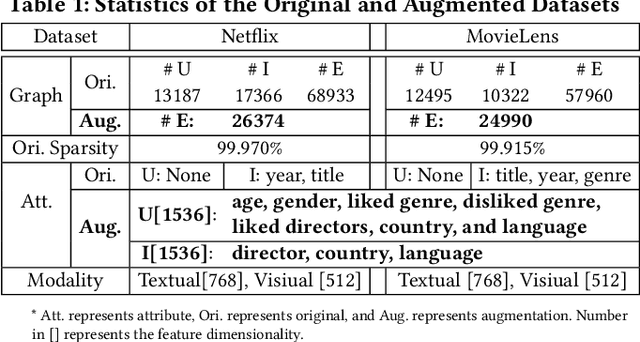
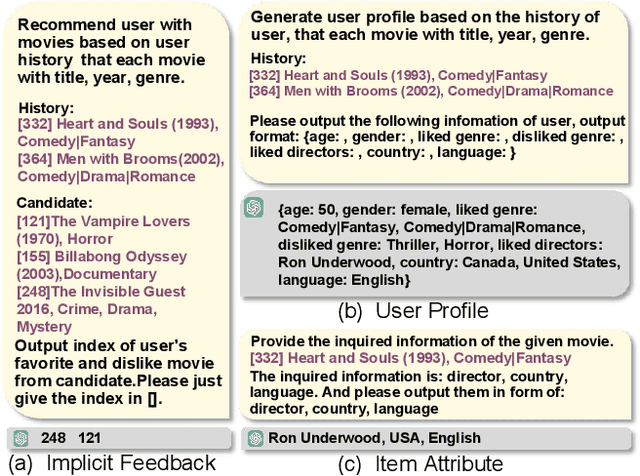
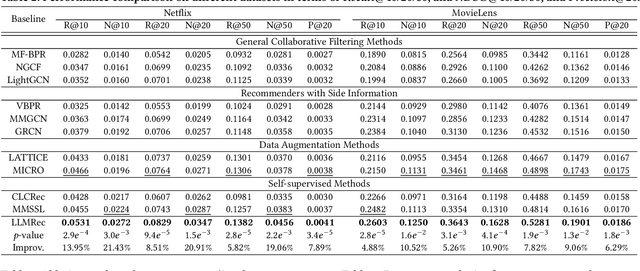
The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git
Improving Hand Recognition in Uncontrolled and Uncooperative Environments using Multiple Spatial Transformers and Loss Functions
Nov 09, 2023The prevalence of smartphone and consumer camera has led to more evidence in the form of digital images, which are mostly taken in uncontrolled and uncooperative environments. In these images, criminals likely hide or cover their faces while their hands are observable in some cases, creating a challenging use case for forensic investigation. Many existing hand-based recognition methods perform well for hand images collected in controlled environments with user cooperation. However, their performance deteriorates significantly in uncontrolled and uncooperative environments. A recent work has exposed the potential of hand recognition in these environments. However, only the palmar regions were considered, and the recognition performance is still far from satisfactory. To improve the recognition accuracy, an algorithm integrating a multi-spatial transformer network (MSTN) and multiple loss functions is proposed to fully utilize information in full hand images. MSTN is firstly employed to localize the palms and fingers and estimate the alignment parameters. Then, the aligned images are further fed into pretrained convolutional neural networks, where features are extracted. Finally, a training scheme with multiple loss functions is used to train the network end-to-end. To demonstrate the effectiveness of the proposed algorithm, the trained model is evaluated on NTU-PI-v1 database and six benchmark databases from different domains. Experimental results show that the proposed algorithm performs significantly better than the existing methods in these uncontrolled and uncooperative environments and has good generalization capabilities to samples from different domains.
Efficient Object Detection in Optical Remote Sensing Imagery via Attention-based Feature Distillation
Oct 28, 2023Efficient object detection methods have recently received great attention in remote sensing. Although deep convolutional networks often have excellent detection accuracy, their deployment on resource-limited edge devices is difficult. Knowledge distillation (KD) is a strategy for addressing this issue since it makes models lightweight while maintaining accuracy. However, existing KD methods for object detection have encountered two constraints. First, they discard potentially important background information and only distill nearby foreground regions. Second, they only rely on the global context, which limits the student detector's ability to acquire local information from the teacher detector. To address the aforementioned challenges, we propose Attention-based Feature Distillation (AFD), a new KD approach that distills both local and global information from the teacher detector. To enhance local distillation, we introduce a multi-instance attention mechanism that effectively distinguishes between background and foreground elements. This approach prompts the student detector to focus on the pertinent channels and pixels, as identified by the teacher detector. Local distillation lacks global information, thus attention global distillation is proposed to reconstruct the relationship between various pixels and pass it from teacher to student detector. The performance of AFD is evaluated on two public aerial image benchmarks, and the evaluation results demonstrate that AFD in object detection can attain the performance of other state-of-the-art models while being efficient.
A Lightweight Architecture for Real-Time Neuronal-Spike Classification
Nov 08, 2023Electrophysiological recordings of neural activity in a mouse's brain are very popular among neuroscientists for understanding brain function. One particular area of interest is acquiring recordings from the Purkinje cells in the cerebellum in order to understand brain injuries and the loss of motor functions. However, current setups for such experiments do not allow the mouse to move freely and, thus, do not capture its natural behaviour since they have a wired connection between the animal's head stage and an acquisition device. In this work, we propose a lightweight neuronal-spike detection and classification architecture that leverages on the unique characteristics of the Purkinje cells to discard unneeded information from the sparse neural data in real time. This allows the (condensed) data to be easily stored on a removable storage device on the head stage, alleviating the need for wires. Our proposed implementation shows a >95% overall classification accuracy while still resulting in a small-form-factor design, which allows for the free movement of mice during experiments. Moreover, the power-efficient nature of the design and the usage of STT-RAM (Spin Transfer Torque Magnetic Random Access Memory) as the removable storage allows the head stage to easily operate on a tiny battery for up to approximately 4 days.
SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification
Nov 08, 2023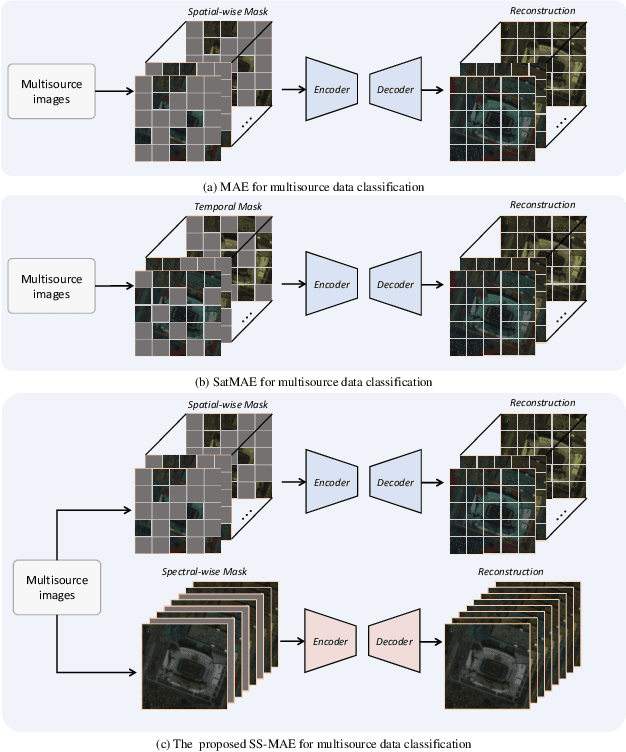

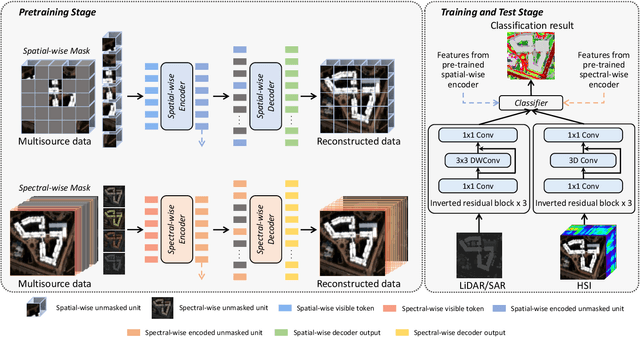
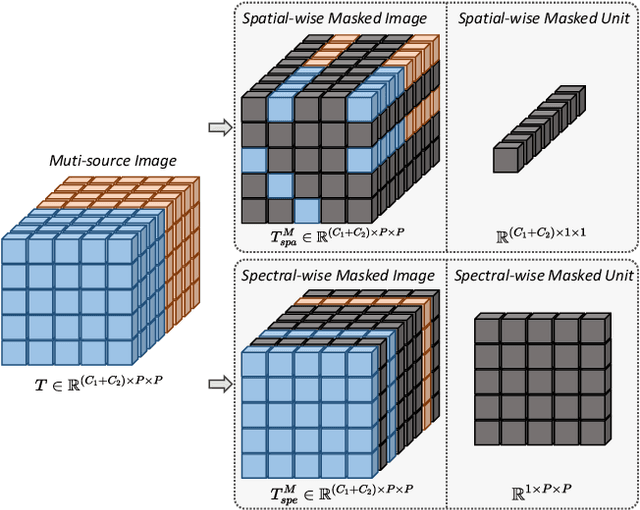
Masked image modeling (MIM) is a highly popular and effective self-supervised learning method for image understanding. Existing MIM-based methods mostly focus on spatial feature modeling, neglecting spectral feature modeling. Meanwhile, existing MIM-based methods use Transformer for feature extraction, some local or high-frequency information may get lost. To this end, we propose a spatial-spectral masked auto-encoder (SS-MAE) for HSI and LiDAR/SAR data joint classification. Specifically, SS-MAE consists of a spatial-wise branch and a spectral-wise branch. The spatial-wise branch masks random patches and reconstructs missing pixels, while the spectral-wise branch masks random spectral channels and reconstructs missing channels. Our SS-MAE fully exploits the spatial and spectral representations of the input data. Furthermore, to complement local features in the training stage, we add two lightweight CNNs for feature extraction. Both global and local features are taken into account for feature modeling. To demonstrate the effectiveness of the proposed SS-MAE, we conduct extensive experiments on three publicly available datasets. Extensive experiments on three multi-source datasets verify the superiority of our SS-MAE compared with several state-of-the-art baselines. The source codes are available at \url{https://github.com/summitgao/SS-MAE}.
Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction
Nov 08, 2023Click Through Rate (CTR) prediction plays an essential role in recommender systems and online advertising. It is crucial to effectively model feature interactions to improve the prediction performance of CTR models. However, existing methods face three significant challenges. First, while most methods can automatically capture high-order feature interactions, their performance tends to diminish as the order of feature interactions increases. Second, existing methods lack the ability to provide convincing interpretations of the prediction results, especially for high-order feature interactions, which limits the trustworthiness of their predictions. Third, many methods suffer from the presence of redundant parameters, particularly in the embedding layer. This paper proposes a novel method called Gated Deep Cross Network (GDCN) and a Field-level Dimension Optimization (FDO) approach to address these challenges. As the core structure of GDCN, Gated Cross Network (GCN) captures explicit high-order feature interactions and dynamically filters important interactions with an information gate in each order. Additionally, we use the FDO approach to learn condensed dimensions for each field based on their importance. Comprehensive experiments on five datasets demonstrate the effectiveness, superiority and interpretability of GDCN. Moreover, we verify the effectiveness of FDO in learning various dimensions and reducing model parameters. The code is available on \url{https://github.com/anonctr/GDCN}.
FFINet: Future Feedback Interaction Network for Motion Forecasting
Nov 08, 2023Motion forecasting plays a crucial role in autonomous driving, with the aim of predicting the future reasonable motions of traffic agents. Most existing methods mainly model the historical interactions between agents and the environment, and predict multi-modal trajectories in a feedforward process, ignoring potential trajectory changes caused by future interactions between agents. In this paper, we propose a novel Future Feedback Interaction Network (FFINet) to aggregate features the current observations and potential future interactions for trajectory prediction. Firstly, we employ different spatial-temporal encoders to embed the decomposed position vectors and the current position of each scene, providing rich features for the subsequent cross-temporal aggregation. Secondly, the relative interaction and cross-temporal aggregation strategies are sequentially adopted to integrate features in the current fusion module, observation interaction module, future feedback module and global fusion module, in which the future feedback module can enable the understanding of pre-action by feeding the influence of preview information to feedforward prediction. Thirdly, the comprehensive interaction features are further fed into final predictor to generate the joint predicted trajectories of multiple agents. Extensive experimental results show that our FFINet achieves the state-of-the-art performance on Argoverse 1 and Argoverse 2 motion forecasting benchmarks.