 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scaling Limits of the Wasserstein information matrix on Gaussian Mixture Models
Sep 22, 2023
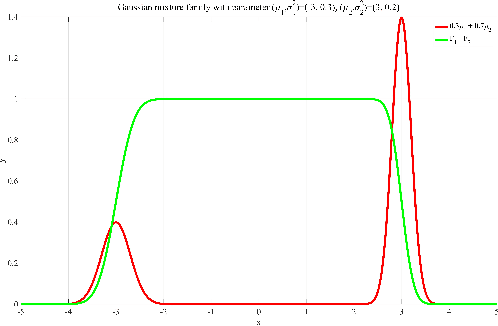
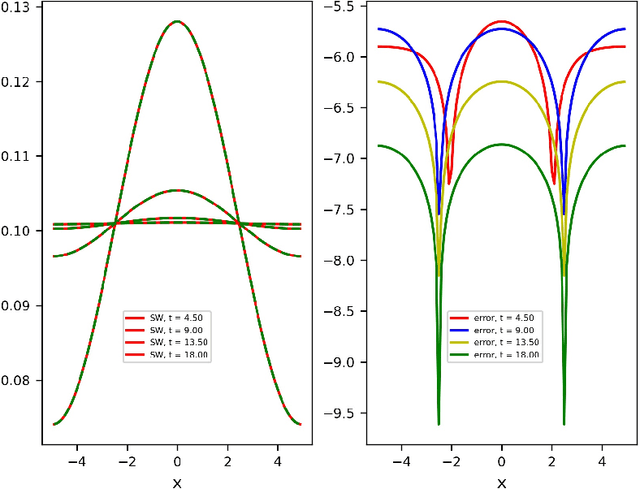
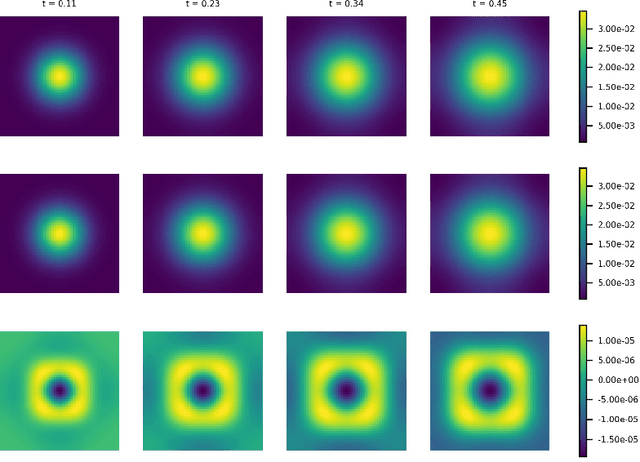
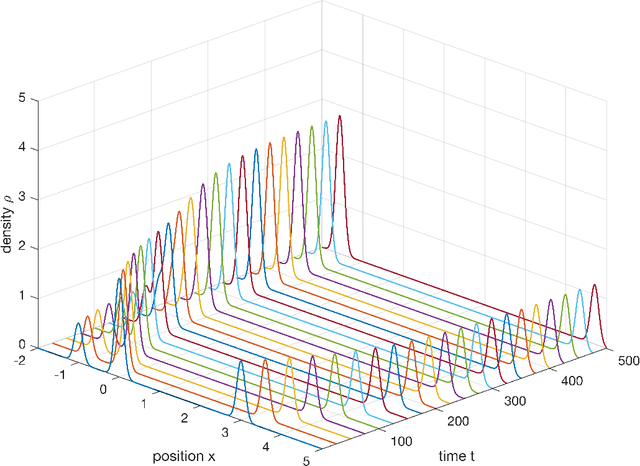
We consider the Wasserstein metric on the Gaussian mixture models (GMMs), which is defined as the pullback of the full Wasserstein metric on the space of smooth probability distributions with finite second moment. It derives a class of Wasserstein metrics on probability simplices over one-dimensional bounded homogeneous lattices via a scaling limit of the Wasserstein metric on GMMs. Specifically, for a sequence of GMMs whose variances tend to zero, we prove that the limit of the Wasserstein metric exists after certain renormalization. Generalizations of this metric in general GMMs are established, including inhomogeneous lattice models whose lattice gaps are not the same, extended GMMs whose mean parameters of Gaussian components can also change, and the second-order metric containing high-order information of the scaling limit. We further study the Wasserstein gradient flows on GMMs for three typical functionals: potential, internal, and interaction energies. Numerical examples demonstrate the effectiveness of the proposed GMM models for approximating Wasserstein gradient flows.
Improving Information Extraction on Business Documents with Specific Pre-Training Tasks
Sep 11, 2023Transformer-based Language Models are widely used in Natural Language Processing related tasks. Thanks to their pre-training, they have been successfully adapted to Information Extraction in business documents. However, most pre-training tasks proposed in the literature for business documents are too generic and not sufficient to learn more complex structures. In this paper, we use LayoutLM, a language model pre-trained on a collection of business documents, and introduce two new pre-training tasks that further improve its capacity to extract relevant information. The first is aimed at better understanding the complex layout of documents, and the second focuses on numeric values and their order of magnitude. These tasks force the model to learn better-contextualized representations of the scanned documents. We further introduce a new post-processing algorithm to decode BIESO tags in Information Extraction that performs better with complex entities. Our method significantly improves extraction performance on both public (from 93.88 to 95.50 F1 score) and private (from 84.35 to 84.84 F1 score) datasets composed of expense receipts, invoices, and purchase orders.
* Conference: Document Analysis Systems. DAS 2022
Astrocytes as a mechanism for meta-plasticity and contextually-guided network function
Nov 10, 2023Astrocytes are a ubiquitous and enigmatic type of non-neuronal cell and are found in the brain of all vertebrates. While traditionally viewed as being supportive of neurons, it is increasingly recognized that astrocytes may play a more direct and active role in brain function and neural computation. On account of their sensitivity to a host of physiological covariates and ability to modulate neuronal activity and connectivity on slower time scales, astrocytes may be particularly well poised to modulate the dynamics of neural circuits in functionally salient ways. In the current paper, we seek to capture these features via actionable abstractions within computational models of neuron-astrocyte interaction. Specifically, we engage how nested feedback loops of neuron-astrocyte interaction, acting over separated time-scales may endow astrocytes with the capability to enable learning in context-dependent settings, where fluctuations in task parameters may occur much more slowly than within-task requirements. We pose a general model of neuron-synapse-astrocyte interaction and use formal analysis to characterize how astrocytic modulation may constitute a form of meta-plasticity, altering the ways in which synapses and neurons adapt as a function of time. We then embed this model in a bandit-based reinforcement learning task environment, and show how the presence of time-scale separated astrocytic modulation enables learning over multiple fluctuating contexts. Indeed, these networks learn far more reliably versus dynamically homogeneous networks and conventional non-network-based bandit algorithms. Our results indicate how the presence of neuron-astrocyte interaction in the brain may benefit learning over different time-scales and the conveyance of task-relevant contextual information onto circuit dynamics.
Joint Problems in Learning Multiple Dynamical Systems
Nov 03, 2023Clustering of time series is a well-studied problem, with applications ranging from quantitative, personalized models of metabolism obtained from metabolite concentrations to state discrimination in quantum information theory. We consider a variant, where given a set of trajectories and a number of parts, we jointly partition the set of trajectories and learn linear dynamical system (LDS) models for each part, so as to minimize the maximum error across all the models. We present globally convergent methods and EM heuristics, accompanied by promising computational results.
A Survey on Recent Named Entity Recognition and Relation Classification Methods with Focus on Few-Shot Learning Approaches
Oct 29, 2023Named entity recognition and relation classification are key stages for extracting information from unstructured text. Several natural language processing applications utilize the two tasks, such as information retrieval, knowledge graph construction and completion, question answering and other domain-specific applications, such as biomedical data mining. We present a survey of recent approaches in the two tasks with focus on few-shot learning approaches. Our work compares the main approaches followed in the two paradigms. Additionally, we report the latest metric scores in the two tasks with a structured analysis that considers the results in the few-shot learning scope.
OmniVec: Learning robust representations with cross modal sharing
Nov 07, 2023Majority of research in learning based methods has been towards designing and training networks for specific tasks. However, many of the learning based tasks, across modalities, share commonalities and could be potentially tackled in a joint framework. We present an approach in such direction, to learn multiple tasks, in multiple modalities, with a unified architecture. The proposed network is composed of task specific encoders, a common trunk in the middle, followed by task specific prediction heads. We first pre-train it by self-supervised masked training, followed by sequential training for the different tasks. We train the network on all major modalities, e.g.\ visual, audio, text and 3D, and report results on $22$ diverse and challenging public benchmarks. We demonstrate empirically that, using a joint network to train across modalities leads to meaningful information sharing and this allows us to achieve state-of-the-art results on most of the benchmarks. We also show generalization of the trained network on cross-modal tasks as well as unseen datasets and tasks.
OtterHD: A High-Resolution Multi-modality Model
Nov 07, 2023
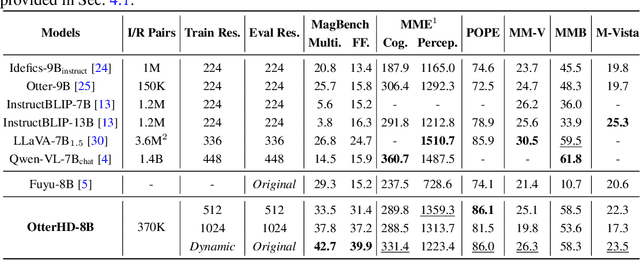
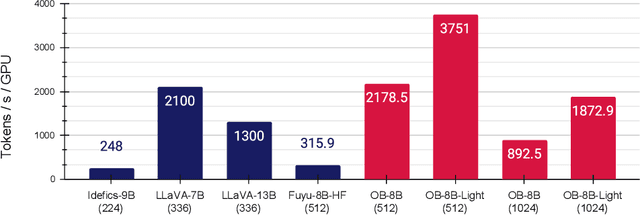

In this paper, we present OtterHD-8B, an innovative multimodal model evolved from Fuyu-8B, specifically engineered to interpret high-resolution visual inputs with granular precision. Unlike conventional models that are constrained by fixed-size vision encoders, OtterHD-8B boasts the ability to handle flexible input dimensions, ensuring its versatility across various inference requirements. Alongside this model, we introduce MagnifierBench, an evaluation framework designed to scrutinize models' ability to discern minute details and spatial relationships of small objects. Our comparative analysis reveals that while current leading models falter on this benchmark, OtterHD-8B, particularly when directly processing high-resolution inputs, outperforms its counterparts by a substantial margin. The findings illuminate the structural variances in visual information processing among different models and the influence that the vision encoders' pre-training resolution disparities have on model effectiveness within such benchmarks. Our study highlights the critical role of flexibility and high-resolution input capabilities in large multimodal models and also exemplifies the potential inherent in the Fuyu architecture's simplicity for handling complex visual data.
A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis
Nov 07, 2023We present a novel usage of Transformers to make image classification interpretable. Unlike mainstream classifiers that wait until the last fully-connected layer to incorporate class information to make predictions, we investigate a proactive approach, asking each class to search for itself in an image. We realize this idea via a Transformer encoder-decoder inspired by DEtection TRansformer (DETR). We learn ``class-specific'' queries (one for each class) as input to the decoder, enabling each class to localize its patterns in an image via cross-attention. We name our approach INterpretable TRansformer (INTR), which is fairly easy to implement and exhibits several compelling properties. We show that INTR intrinsically encourages each class to attend distinctively; the cross-attention weights thus provide a faithful interpretation of the prediction. Interestingly, via ``multi-head'' cross-attention, INTR could identify different ``attributes'' of a class, making it particularly suitable for fine-grained classification and analysis, which we demonstrate on eight datasets. Our code and pre-trained model are publicly accessible at https://github.com/Imageomics/INTR.
CNN-Based Structural Damage Detection using Time-Series Sensor Data
Nov 07, 2023Structural Health Monitoring (SHM) is vital for evaluating structural condition, aiming to detect damage through sensor data analysis. It aligns with predictive maintenance in modern industry, minimizing downtime and costs by addressing potential structural issues. Various machine learning techniques have been used to extract valuable information from vibration data, often relying on prior structural knowledge. This research introduces an innovative approach to structural damage detection, utilizing a new Convolutional Neural Network (CNN) algorithm. In order to extract deep spatial features from time series data, CNNs are taught to recognize long-term temporal connections. This methodology combines spatial and temporal features, enhancing discrimination capabilities when compared to methods solely reliant on deep spatial features. Time series data are divided into two categories using the proposed neural network: undamaged and damaged. To validate its efficacy, the method's accuracy was tested using a benchmark dataset derived from a three-floor structure at Los Alamos National Laboratory (LANL). The outcomes show that the new CNN algorithm is very accurate in spotting structural degradation in the examined structure.
Gender Inflected or Bias Inflicted: On Using Grammatical Gender Cues for Bias Evaluation in Machine Translation
Nov 07, 2023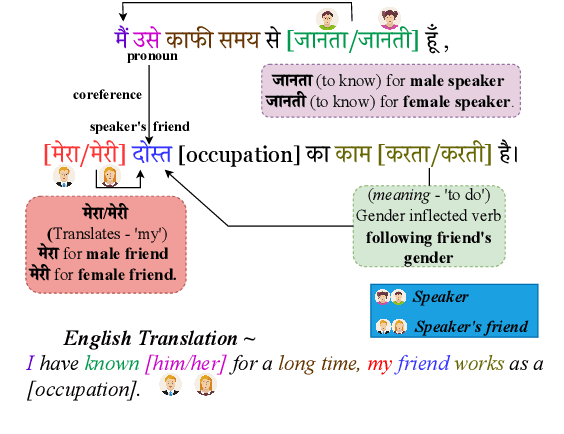
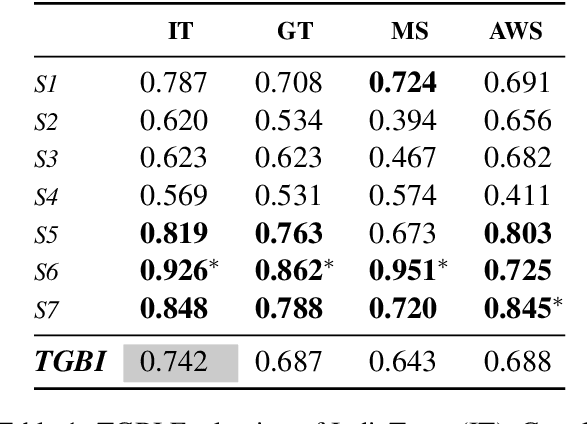
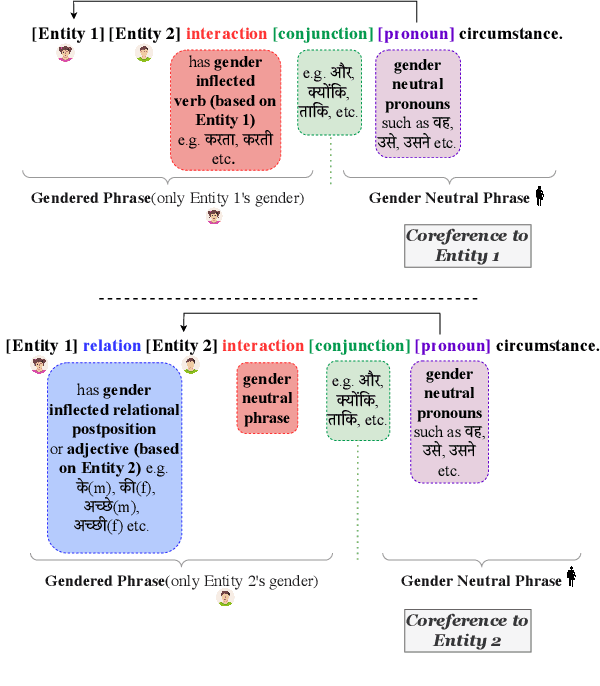
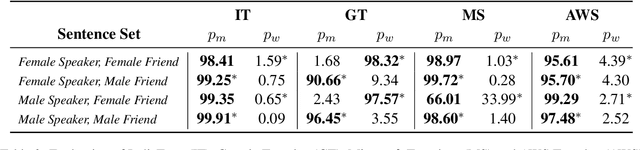
Neural Machine Translation (NMT) models are state-of-the-art for machine translation. However, these models are known to have various social biases, especially gender bias. Most of the work on evaluating gender bias in NMT has focused primarily on English as the source language. For source languages different from English, most of the studies use gender-neutral sentences to evaluate gender bias. However, practically, many sentences that we encounter do have gender information. Therefore, it makes more sense to evaluate for bias using such sentences. This allows us to determine if NMT models can identify the correct gender based on the grammatical gender cues in the source sentence rather than relying on biased correlations with, say, occupation terms. To demonstrate our point, in this work, we use Hindi as the source language and construct two sets of gender-specific sentences: OTSC-Hindi and WinoMT-Hindi that we use to evaluate different Hindi-English (HI-EN) NMT systems automatically for gender bias. Our work highlights the importance of considering the nature of language when designing such extrinsic bias evaluation datasets.