 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LLMs cannot find reasoning errors, but can correct them!
Nov 14, 2023
While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we break down the self-correction process into two core components: mistake finding and output correction. For mistake finding, we release BIG-Bench Mistake, a dataset of logical mistakes in Chain-of-Thought reasoning traces. We provide benchmark numbers for several state-of-the-art LLMs, and demonstrate that LLMs generally struggle with finding logical mistakes. For output correction, we propose a backtracking method which provides large improvements when given information on mistake location. We construe backtracking as a lightweight alternative to reinforcement learning methods, and show that it remains effective with a reward model at 60-70% accuracy.
Learning to Filter Context for Retrieval-Augmented Generation
Nov 14, 2023On-the-fly retrieval of relevant knowledge has proven an essential element of reliable systems for tasks such as open-domain question answering and fact verification. However, because retrieval systems are not perfect, generation models are required to generate outputs given partially or entirely irrelevant passages. This can cause over- or under-reliance on context, and result in problems in the generated output such as hallucinations. To alleviate these problems, we propose FILCO, a method that improves the quality of the context provided to the generator by (1) identifying useful context based on lexical and information-theoretic approaches, and (2) training context filtering models that can filter retrieved contexts at test time. We experiment on six knowledge-intensive tasks with FLAN-T5 and LLaMa2, and demonstrate that our method outperforms existing approaches on extractive question answering (QA), complex multi-hop and long-form QA, fact verification, and dialog generation tasks. FILCO effectively improves the quality of context, whether or not it supports the canonical output.
Passive Human Sensing Enhanced by Reconfigurable Intelligent Surface: Opportunities and Challenges
Nov 14, 2023Reconfigurable intelligent surfaces (RISs) have flexible and exceptional performance in manipulating electromagnetic waves and customizing wireless channels. These capabilities enable them to provide a plethora of valuable activity-related information for promoting wireless human sensing. In this article, we present a comprehensive review of passive human sensing using radio frequency signals with the assistance of RISs. Specifically, we first introduce fundamental principles and physical platform of RISs. Subsequently, based on the specific applications, we categorize the state-of-the-art human sensing techniques into three types, including human imaging,localization, and activity recognition. Meanwhile, we would also investigate the benefits that RISs bring to these applications. Furthermore, we explore the application of RISs in human micro-motion sensing, and propose a vital signs monitoring system enhanced by RISs. Experimental results are presented to demonstrate the promising potential of RISs in sensing vital signs for manipulating individuals. Finally, we discuss the technical challenges and opportunities in this field.
A Comparative Analysis of the COVID-19 Infodemic in English and Chinese: Insights from Social Media Textual Data
Nov 14, 2023The COVID-19 infodemic, characterized by the rapid spread of misinformation and unverified claims related to the pandemic, presents a significant challenge. This paper presents a comparative analysis of the COVID-19 infodemic in the English and Chinese languages, utilizing textual data extracted from social media platforms. To ensure a balanced representation, two infodemic datasets were created by augmenting previously collected social media textual data. Through word frequency analysis, the thirty-five most frequently occurring infodemic words are identified, shedding light on prevalent discussions surrounding the infodemic. Moreover, topic clustering analysis uncovers thematic structures and provides a deeper understanding of primary topics within each language context. Additionally, sentiment analysis enables comprehension of the emotional tone associated with COVID-19 information on social media platforms in English and Chinese. This research contributes to a better understanding of the COVID-19 infodemic phenomenon and can guide the development of strategies to combat misinformation during public health crises across different languages.
Learning Mutually Informed Representations for Characters and Subwords
Nov 14, 2023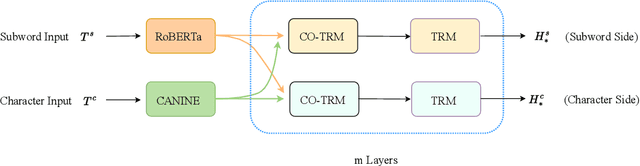
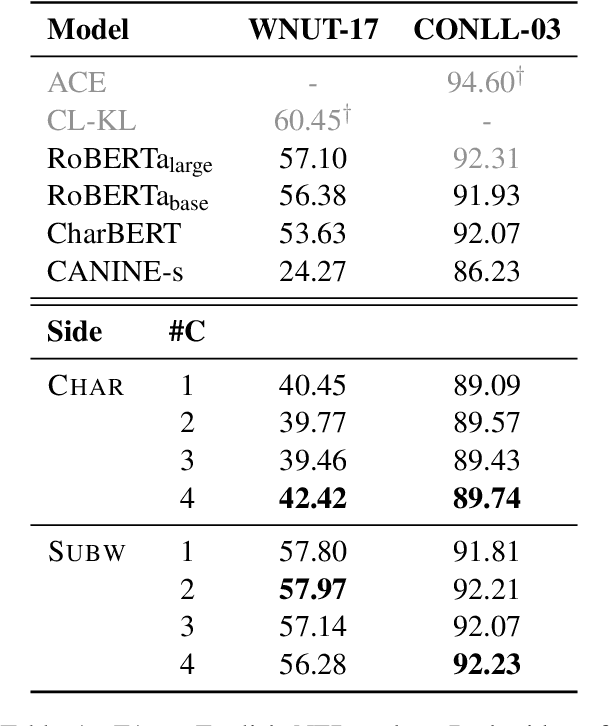
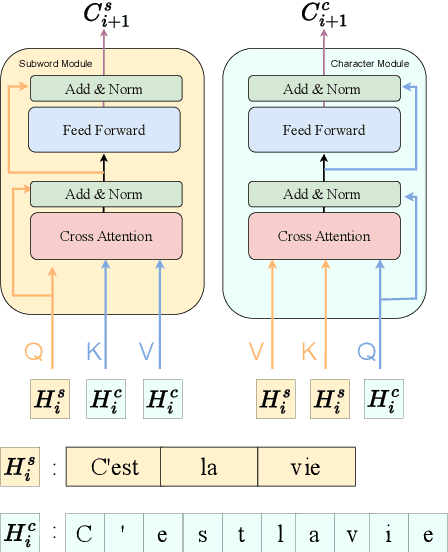
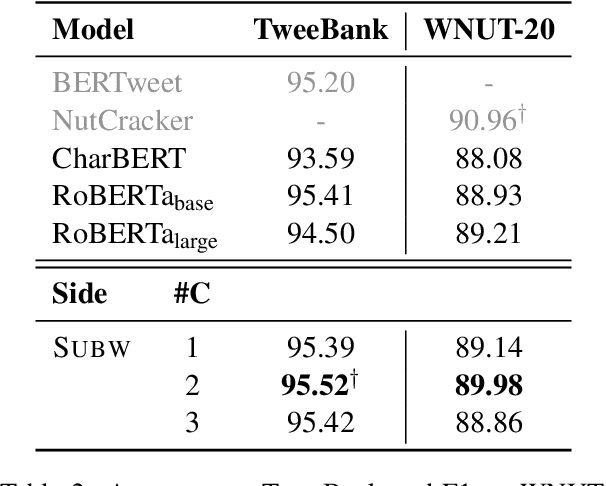
Most pretrained language models rely on subword tokenization, which processes text as a sequence of subword tokens. However, different granularities of text, such as characters, subwords, and words, can contain different kinds of information. Previous studies have shown that incorporating multiple input granularities improves model generalization, yet very few of them outputs useful representations for each granularity. In this paper, we introduce the entanglement model, aiming to combine character and subword language models. Inspired by vision-language models, our model treats characters and subwords as separate modalities, and it generates mutually informed representations for both granularities as output. We evaluate our model on text classification, named entity recognition, and POS-tagging tasks. Notably, the entanglement model outperforms its backbone language models, particularly in the presence of noisy texts and low-resource languages. Furthermore, the entanglement model even outperforms larger pre-trained models on all English sequence labeling tasks and classification tasks. Our anonymized code is available at https://anonymous.4open.science/r/noisy-IE-A673
Spoken Dialogue System for Medical Prescription Acquisition on Smartphone: Development, Corpus and Evaluation
Nov 06, 2023Hospital information systems (HIS) have become an essential part of healthcare institutions and now incorporate prescribing support software. Prescription support software allows for structured information capture, which improves the safety, appropriateness and efficiency of prescriptions and reduces the number of adverse drug events (ADEs). However, such a system increases the amount of time physicians spend at a computer entering information instead of providing medical care. In addition, any new visiting clinician must learn to manage complex interfaces since each HIS has its own interfaces. In this paper, we present a natural language interface for e-prescribing software in the form of a spoken dialogue system accessible on a smartphone. This system allows prescribers to record their prescriptions verbally, a form of interaction closer to their usual practice. The system extracts the formal representation of the prescription ready to be checked by the prescribing software and uses the dialogue to request mandatory information, correct errors or warn of particular situations. Since, to the best of our knowledge, there is no existing voice-based prescription dialogue system, we present the system developed in a low-resource environment, focusing on dialogue modeling, semantic extraction and data augmentation. The system was evaluated in the wild with 55 participants. This evaluation showed that our system has an average prescription time of 66.15 seconds for physicians and 35.64 seconds for other experts, and a task success rate of 76\% for physicians and 72\% for other experts. All evaluation data were recorded and annotated to form PxCorpus, the first spoken drug prescription corpus that has been made fully available to the community (\url{https://doi.org/10.5281/zenodo.6524162}).
Multi-User Multi-IoT-Device Symbiotic Radio: A Novel Massive Access Scheme for Cellular IoT
Nov 06, 2023Symbiotic radio (SR) is a promising technique to support cellular Internet-of-Things (IoT) by forming a mutualistic relationship between IoT and cellular transmissions. In this paper, we propose a novel multi-user multi-IoT-device SR system to enable massive access in cellular IoT. In the considered system, the base station (BS) transmits information to multiple cellular users, and a number of IoT devices simultaneously backscatter their information to these users via the cellular signal. The cellular users jointly decode the information from the BS and IoT devices. Noting that the reflective links from the IoT devices can be regarded as the channel uncertainty of the direct links, we apply the robust design method to design the beamforming vectors at the BS. Specifically, the transmit power is minimized under the cellular transmission outage probability constraints and IoT transmission sum rate constraints. The algorithm based on semi-definite programming and difference-of-convex programming is proposed to solve the power minimization problem. Moreover, we consider a special case where each cellular user is associated with several adjacent IoT devices and propose a direction of arrival (DoA)-based transmit beamforming design approach. The DoA-based approach requires only the DoA and angular spread (AS) of the direct links instead of the instantaneous channel state information (CSI) of the reflective link channels, leading to a significant reduction in the channel feedback overhead. Simulation results have substantiated the multi-user multi-IoT-device SR system and the effectiveness of the proposed beamforming approaches. It is shown that the DoA-based beamforming approach achieves comparable performance as the CSI-based approach in the special case when the ASs are small.
LLM-driven Multimodal Target Volume Contouring in Radiation Oncology
Nov 03, 2023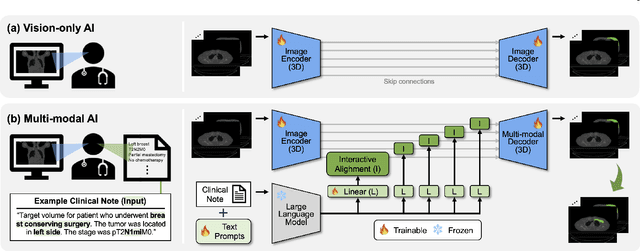

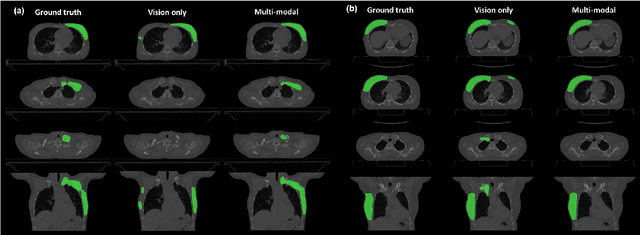

Target volume contouring for radiation therapy is considered significantly more challenging than the normal organ segmentation tasks as it necessitates the utilization of both image and text-based clinical information. Inspired by the recent advancement of large language models (LLMs) that can facilitate the integration of the textural information and images, here we present a novel LLM-driven multi-modal AI that utilizes the clinical text information and is applicable to the challenging task of target volume contouring for radiation therapy, and validate it within the context of breast cancer radiation therapy target volume contouring. Using external validation and data-insufficient environments, which attributes highly conducive to real-world applications, we demonstrate that the proposed model exhibits markedly improved performance compared to conventional vision-only AI models, particularly exhibiting robust generalization performance and data-efficiency. To our best knowledge, this is the first LLM-driven multimodal AI model that integrates the clinical text information into target volume delineation for radiation oncology.
NLQxform: A Language Model-based Question to SPARQL Transformer
Nov 08, 2023In recent years, scholarly data has grown dramatically in terms of both scale and complexity. It becomes increasingly challenging to retrieve information from scholarly knowledge graphs that include large-scale heterogeneous relationships, such as authorship, affiliation, and citation, between various types of entities, e.g., scholars, papers, and organizations. As part of the Scholarly QALD Challenge, this paper presents a question-answering (QA) system called NLQxform, which provides an easy-to-use natural language interface to facilitate accessing scholarly knowledge graphs. NLQxform allows users to express their complex query intentions in natural language questions. A transformer-based language model, i.e., BART, is employed to translate questions into standard SPARQL queries, which can be evaluated to retrieve the required information. According to the public leaderboard of the Scholarly QALD Challenge at ISWC 2023 (Task 1: DBLP-QUAD - Knowledge Graph Question Answering over DBLP), NLQxform achieved an F1 score of 0.85 and ranked first on the QA task, demonstrating the competitiveness of the system.
Deep Image Semantic Communication Model for Artificial Intelligent Internet of Things
Nov 08, 2023With the rapid development of Artificial Intelligent Internet of Things (AIoT), the image data from AIoT devices has been witnessing the explosive increasing. In this paper, a novel deep image semantic communication model is proposed for the efficient image communication in AIoT. Particularly, at the transmitter side, a high-precision image semantic segmentation algorithm is proposed to extract the semantic information of the image to achieve significant compression of the image data. At the receiver side, a semantic image restoration algorithm based on Generative Adversarial Network (GAN) is proposed to convert the semantic image to a real scene image with detailed information. Simulation results demonstrate that the proposed image semantic communication model can improve the image compression ratio and recovery accuracy by 71.93% and 25.07% on average in comparison with WebP and CycleGAN, respectively. More importantly, our demo experiment shows that the proposed model reduces the total delay by 95.26% in the image communication, when comparing with the original image transmission.