 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IPT-V2: Efficient Image Processing Transformer using Hierarchical Attentions
Mar 31, 2024
Recent advances have demonstrated the powerful capability of transformer architecture in image restoration. However, our analysis indicates that existing transformerbased methods can not establish both exact global and local dependencies simultaneously, which are much critical to restore the details and missing content of degraded images. To this end, we present an efficient image processing transformer architecture with hierarchical attentions, called IPTV2, adopting a focal context self-attention (FCSA) and a global grid self-attention (GGSA) to obtain adequate token interactions in local and global receptive fields. Specifically, FCSA applies the shifted window mechanism into the channel self-attention, helps capture the local context and mutual interaction across channels. And GGSA constructs long-range dependencies in the cross-window grid, aggregates global information in spatial dimension. Moreover, we introduce structural re-parameterization technique to feed-forward network to further improve the model capability. Extensive experiments demonstrate that our proposed IPT-V2 achieves state-of-the-art results on various image processing tasks, covering denoising, deblurring, deraining and obtains much better trade-off for performance and computational complexity than previous methods. Besides, we extend our method to image generation as latent diffusion backbone, and significantly outperforms DiTs.
From "um" to "yeah": Producing, predicting, and regulating information flow in human conversation
Mar 13, 2024
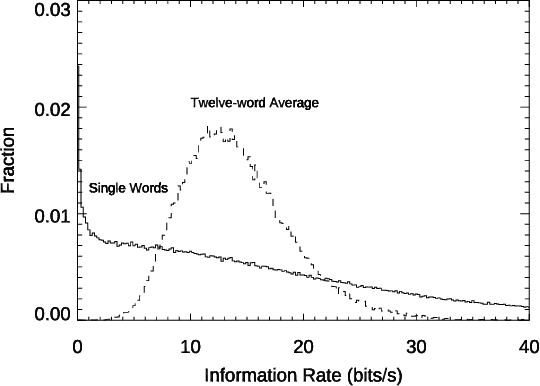
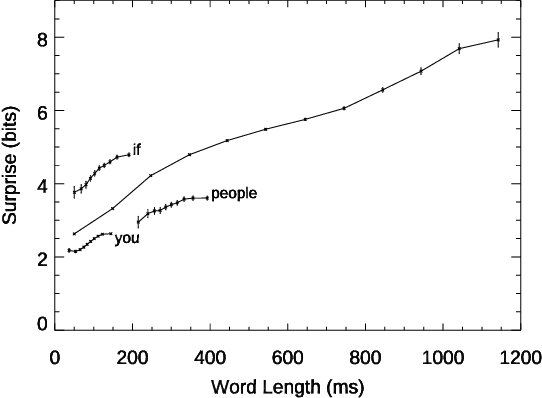
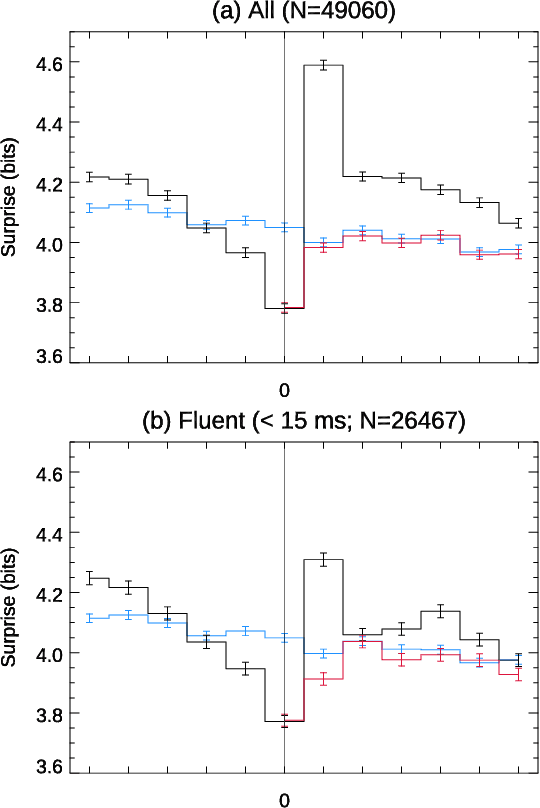
Conversation demands attention. Speakers must call words to mind, listeners must make sense of them, and both together must negotiate this flow of information, all in fractions of a second. We used large language models to study how this works in a large-scale dataset of English-language conversation, the CANDOR corpus. We provide a new estimate of the information density of unstructured conversation, of approximately 13 bits/second, and find significant effects associated with the cognitive load of both retrieving, and presenting, that information. We also reveal a role for backchannels -- the brief yeahs, uh-huhs, and mhmms that listeners provide -- in regulating the production of novelty: the lead-up to a backchannel is associated with declining information rate, while speech downstream rebounds to previous rates. Our results provide new insights into long-standing theories of how we respond to fluctuating demands on cognitive resources, and how we negotiate those demands in partnership with others.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024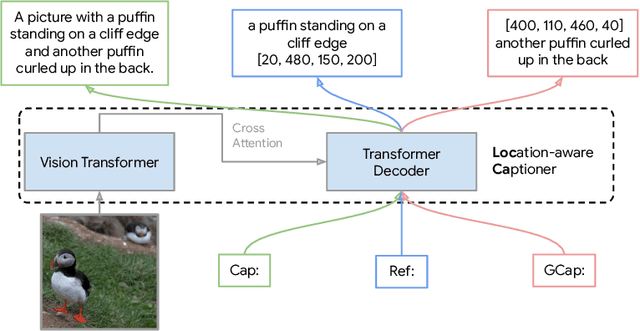
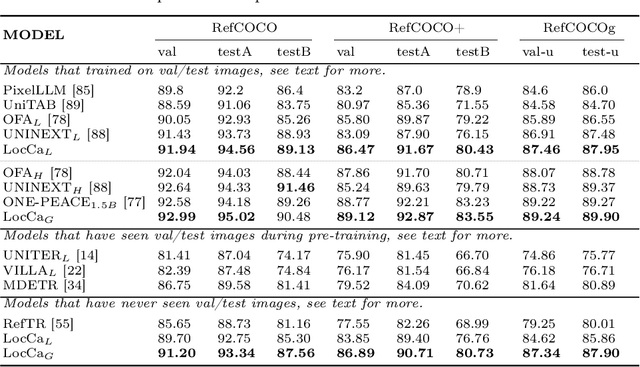
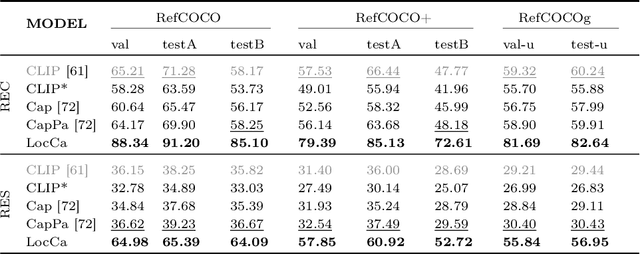
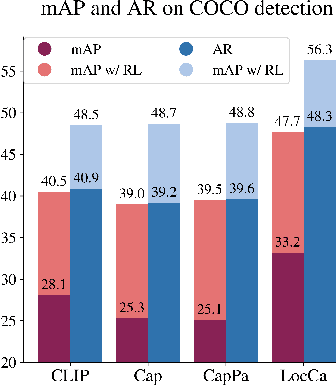
Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
MRNaB: Mixed Reality-based Robot Navigation Interface using Optical-see-through MR-beacon
Mar 28, 2024Recent advancements in robotics have led to the development of numerous interfaces to enhance the intuitiveness of robot navigation. However, the reliance on traditional 2D displays imposes limitations on the simultaneous visualization of information. Mixed Reality (MR) technology addresses this issue by enhancing the dimensionality of information visualization, allowing users to perceive multiple pieces of information concurrently. This paper proposes Mixed reality-based robot navigation interface using an optical-see-through MR-beacon (MRNaB), a novel approach that incorporates an MR-beacon, situated atop the real-world environment, to function as a signal transmitter for robot navigation. This MR-beacon is designed to be persistent, eliminating the need for repeated navigation inputs for the same location. Our system is mainly constructed into four primary functions: "Add", "Move", "Delete", and "Select". These allow for the addition of a MR-beacon, location movement, its deletion, and the selection of MR-beacon for navigation purposes, respectively. The effectiveness of the proposed method was then validated through experiments by comparing it with the traditional 2D system. As the result, MRNaB was proven to increase the performance of the user when doing navigation to a certain place subjectively and objectively. For additional material, please check: https://mertcookimg.github.io/mrnab
Embracing Unknown Step by Step: Towards Reliable Sparse Training in Real World
Mar 29, 2024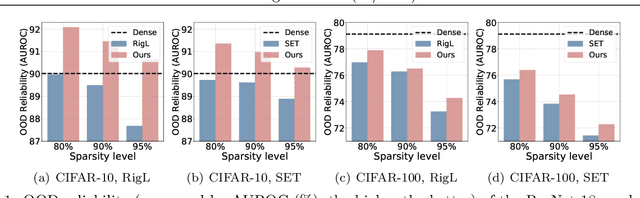
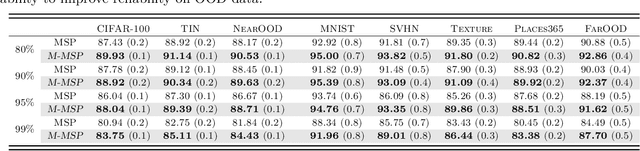
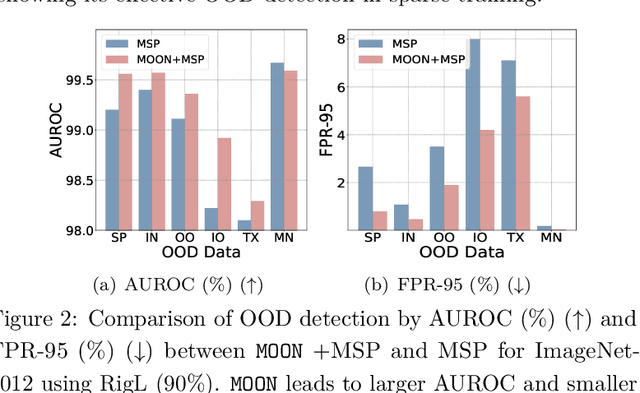
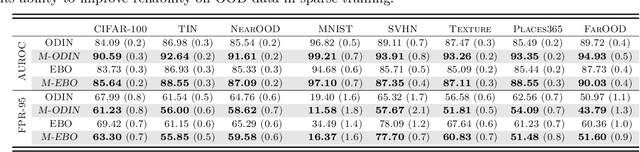
Sparse training has emerged as a promising method for resource-efficient deep neural networks (DNNs) in real-world applications. However, the reliability of sparse models remains a crucial concern, particularly in detecting unknown out-of-distribution (OOD) data. This study addresses the knowledge gap by investigating the reliability of sparse training from an OOD perspective and reveals that sparse training exacerbates OOD unreliability. The lack of unknown information and the sparse constraints hinder the effective exploration of weight space and accurate differentiation between known and unknown knowledge. To tackle these challenges, we propose a new unknown-aware sparse training method, which incorporates a loss modification, auto-tuning strategy, and a voting scheme to guide weight space exploration and mitigate confusion between known and unknown information without incurring significant additional costs or requiring access to additional OOD data. Theoretical insights demonstrate how our method reduces model confidence when faced with OOD samples. Empirical experiments across multiple datasets, model architectures, and sparsity levels validate the effectiveness of our method, with improvements of up to \textbf{8.4\%} in AUROC while maintaining comparable or higher accuracy and calibration. This research enhances the understanding and readiness of sparse DNNs for deployment in resource-limited applications. Our code is available on: \url{https://github.com/StevenBoys/MOON}.
TDANet: A Novel Temporal Denoise Convolutional Neural Network With Attention for Fault Diagnosis
Mar 29, 2024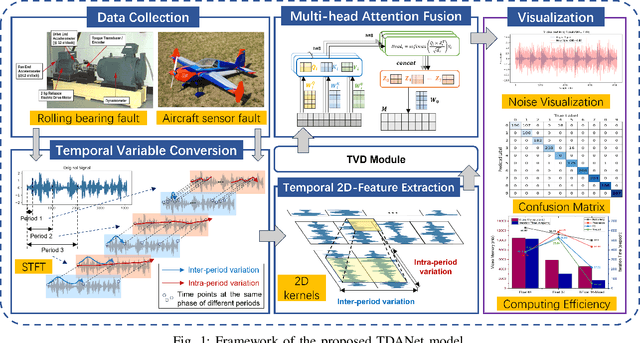
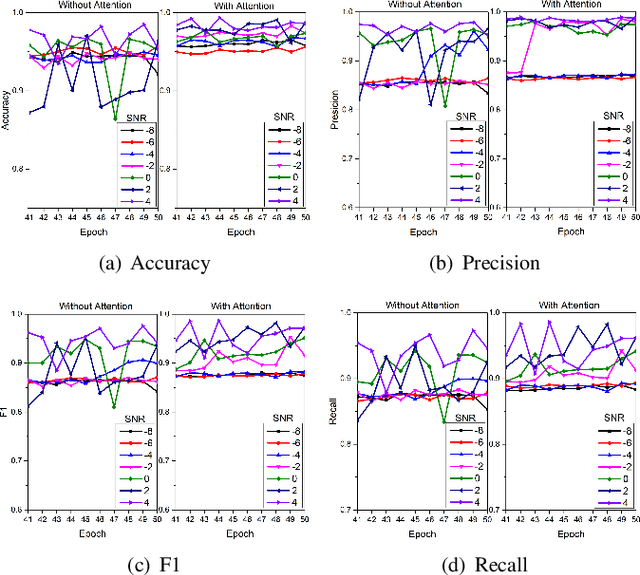
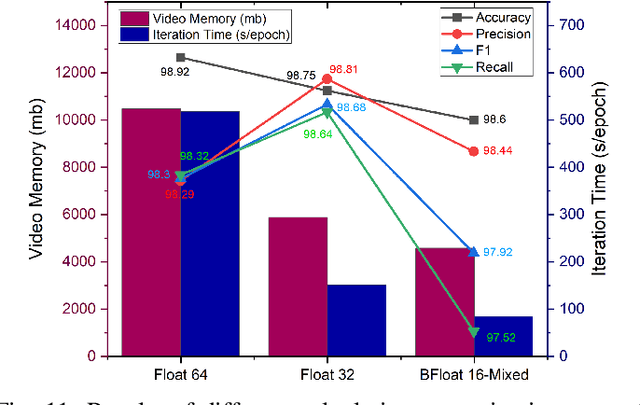
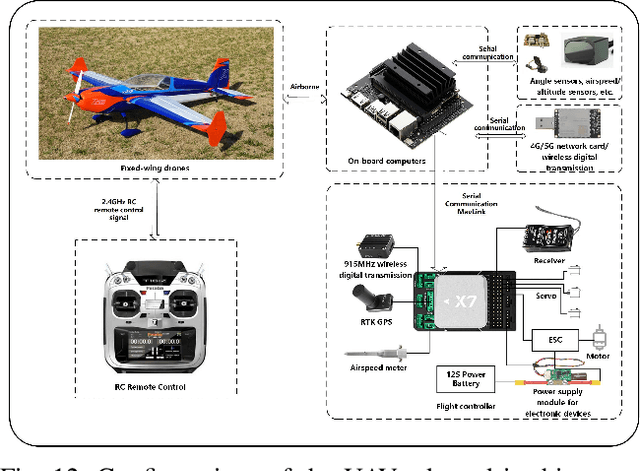
Fault diagnosis plays a crucial role in maintaining the operational integrity of mechanical systems, preventing significant losses due to unexpected failures. As intelligent manufacturing and data-driven approaches evolve, Deep Learning (DL) has emerged as a pivotal technique in fault diagnosis research, recognized for its ability to autonomously extract complex features. However, the practical application of current fault diagnosis methods is challenged by the complexity of industrial environments. This paper proposed the Temporal Denoise Convolutional Neural Network With Attention (TDANet), designed to improve fault diagnosis performance in noise environments. This model transforms one-dimensional signals into two-dimensional tensors based on their periodic properties, employing multi-scale 2D convolution kernels to extract signal information both within and across periods. This method enables effective identification of signal characteristics that vary over multiple time scales. The TDANet incorporates a Temporal Variable Denoise (TVD) module with residual connections and a Multi-head Attention Fusion (MAF) module, enhancing the saliency of information within noisy data and maintaining effective fault diagnosis performance. Evaluation on two datasets, CWRU (single sensor) and Real aircraft sensor fault (multiple sensors), demonstrates that the TDANet model significantly outperforms existing deep learning approaches in terms of diagnostic accuracy under noisy environments.
PLoc: A New Evaluation Criterion Based on Physical Location for Autonomous Driving Datasets
Mar 29, 2024


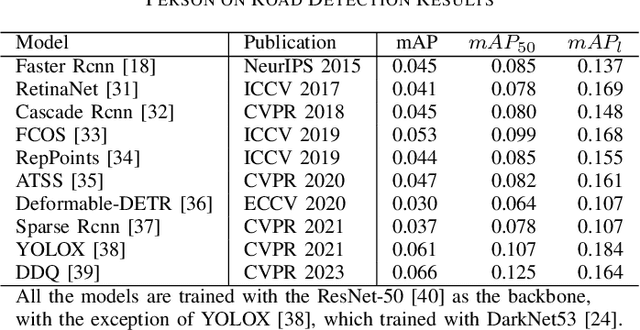
Autonomous driving has garnered significant attention as a key research area within artificial intelligence. In the context of autonomous driving scenarios, the varying physical locations of objects correspond to different levels of danger. However, conventional evaluation criteria for automatic driving object detection often overlook the crucial aspect of an object's physical location, leading to evaluation results that may not accurately reflect the genuine threat posed by the object to the autonomous driving vehicle. To enhance the safety of autonomous driving, this paper introduces a novel evaluation criterion based on physical location information, termed PLoc. This criterion transcends the limitations of traditional criteria by acknowledging that the physical location of pedestrians in autonomous driving scenarios can provide valuable safety-related information. Furthermore, this paper presents a newly re-annotated dataset (ApolloScape-R) derived from ApolloScape. ApolloScape-R involves the relabeling of pedestrians based on the significance of their physical location. The dataset is utilized to assess the performance of various object detection models under the proposed PLoc criterion. Experimental results demonstrate that the average accuracy of all object detection models in identifying a person situated in the travel lane of an autonomous vehicle is lower than that for a person on a sidewalk. The dataset is publicly available at https://github.com/lnyrlyed/ApolloScape-R.git
CATSNet: a context-aware network for Height Estimation in a Forested Area based on Pol-TomoSAR data
Mar 29, 2024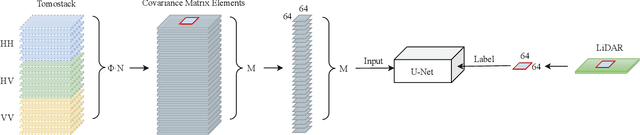
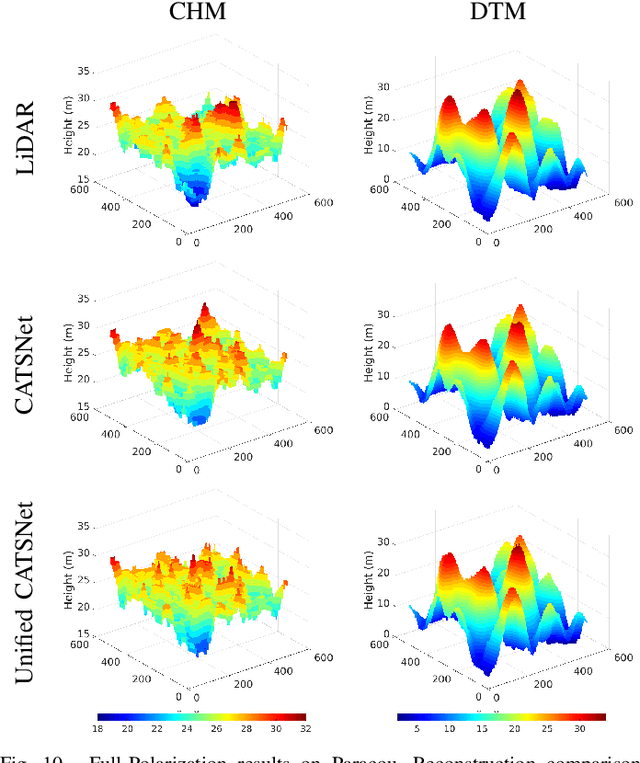
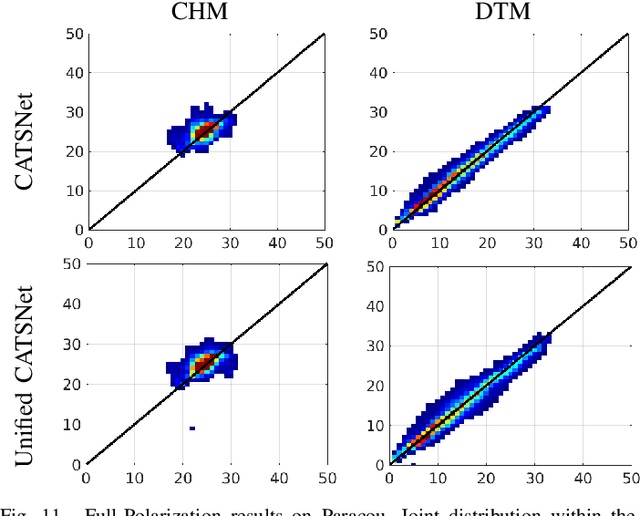
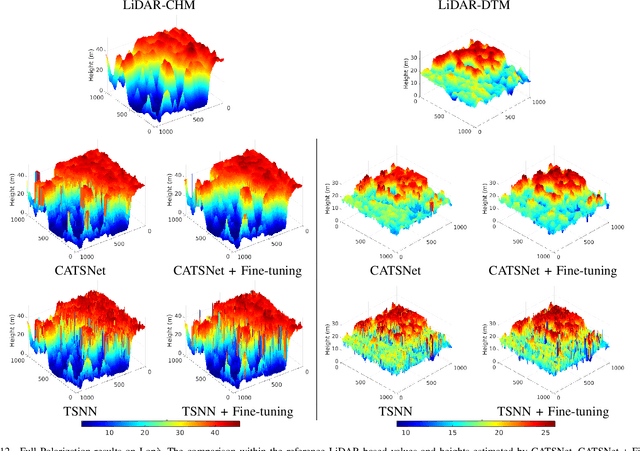
Tropical forests are a key component of the global carbon cycle. With plans for upcoming space-borne missions like BIOMASS to monitor forestry, several airborne missions, including TropiSAR and AfriSAR campaigns, have been successfully launched and experimented. Typical Synthetic Aperture Radar Tomography (TomoSAR) methods involve complex models with low accuracy and high computation costs. In recent years, deep learning methods have also gained attention in the TomoSAR framework, showing interesting performance. Recently, a solution based on a fully connected Tomographic Neural Network (TSNN) has demonstrated its effectiveness in accurately estimating forest and ground heights by exploiting the pixel-wise elements of the covariance matrix derived from TomoSAR data. This work instead goes beyond the pixel-wise approach to define a context-aware deep learning-based solution named CATSNet. A convolutional neural network is considered to leverage patch-based information and extract features from a neighborhood rather than focus on a single pixel. The training is conducted by considering TomoSAR data as the input and Light Detection and Ranging (LiDAR) values as the ground truth. The experimental results show striking advantages in both performance and generalization ability by leveraging context information within Multiple Baselines (MB) TomoSAR data across different polarimetric modalities, surpassing existing techniques.
KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Mar 14, 2024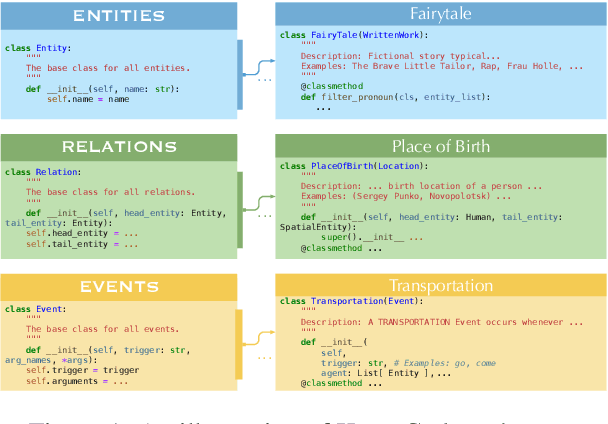
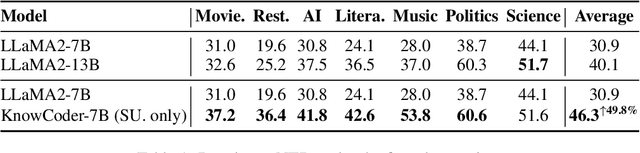
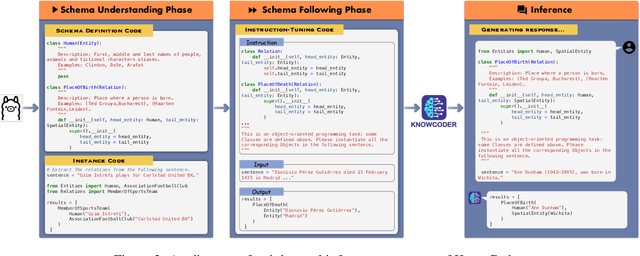
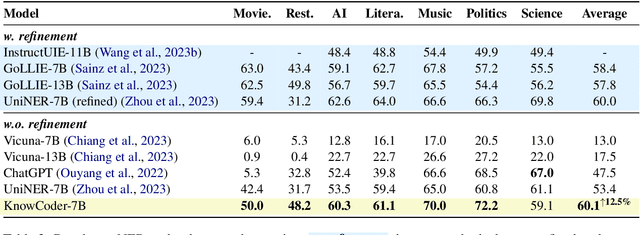
In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over $\textbf{30,000}$ types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a two-phase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around $1.5$B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $\textbf{49.8%}$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $\textbf{12.5%}$ and $\textbf{21.9%}$, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $\textbf{7.5%}$ under the supervised setting.
From Similarity to Superiority: Channel Clustering for Time Series Forecasting
Mar 31, 2024Time series forecasting has attracted significant attention in recent decades. Previous studies have demonstrated that the Channel-Independent (CI) strategy improves forecasting performance by treating different channels individually, while it leads to poor generalization on unseen instances and ignores potentially necessary interactions between channels. Conversely, the Channel-Dependent (CD) strategy mixes all channels with even irrelevant and indiscriminate information, which, however, results in oversmoothing issues and limits forecasting accuracy. There is a lack of channel strategy that effectively balances individual channel treatment for improved forecasting performance without overlooking essential interactions between channels. Motivated by our observation of a correlation between the time series model's performance boost against channel mixing and the intrinsic similarity on a pair of channels, we developed a novel and adaptable Channel Clustering Module (CCM). CCM dynamically groups channels characterized by intrinsic similarities and leverages cluster identity instead of channel identity, combining the best of CD and CI worlds. Extensive experiments on real-world datasets demonstrate that CCM can (1) boost the performance of CI and CD models by an average margin of 2.4% and 7.2% on long-term and short-term forecasting, respectively; (2) enable zero-shot forecasting with mainstream time series forecasting models; (3) uncover intrinsic time series patterns among channels and improve interpretability of complex time series models.