 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aria-NeRF: Multimodal Egocentric View Synthesis
Nov 11, 2023
We seek to accelerate research in developing rich, multimodal scene models trained from egocentric data, based on differentiable volumetric ray-tracing inspired by Neural Radiance Fields (NeRFs). The construction of a NeRF-like model from an egocentric image sequence plays a pivotal role in understanding human behavior and holds diverse applications within the realms of VR/AR. Such egocentric NeRF-like models may be used as realistic simulations, contributing significantly to the advancement of intelligent agents capable of executing tasks in the real-world. The future of egocentric view synthesis may lead to novel environment representations going beyond today's NeRFs by augmenting visual data with multimodal sensors such as IMU for egomotion tracking, audio sensors to capture surface texture and human language context, and eye-gaze trackers to infer human attention patterns in the scene. To support and facilitate the development and evaluation of egocentric multimodal scene modeling, we present a comprehensive multimodal egocentric video dataset. This dataset offers a comprehensive collection of sensory data, featuring RGB images, eye-tracking camera footage, audio recordings from a microphone, atmospheric pressure readings from a barometer, positional coordinates from GPS, connectivity details from Wi-Fi and Bluetooth, and information from dual-frequency IMU datasets (1kHz and 800Hz) paired with a magnetometer. The dataset was collected with the Meta Aria Glasses wearable device platform. The diverse data modalities and the real-world context captured within this dataset serve as a robust foundation for furthering our understanding of human behavior and enabling more immersive and intelligent experiences in the realms of VR, AR, and robotics.
SAppKG: Mobile App Recommendation Using Knowledge Graph and Side Information-A Secure Framework
Sep 29, 2023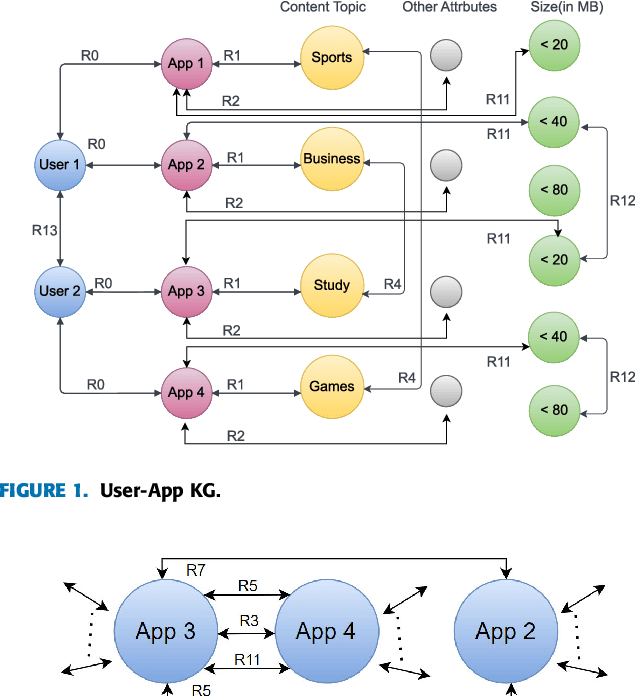
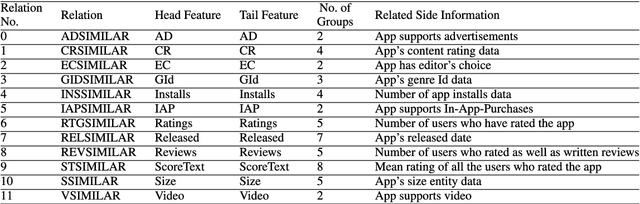

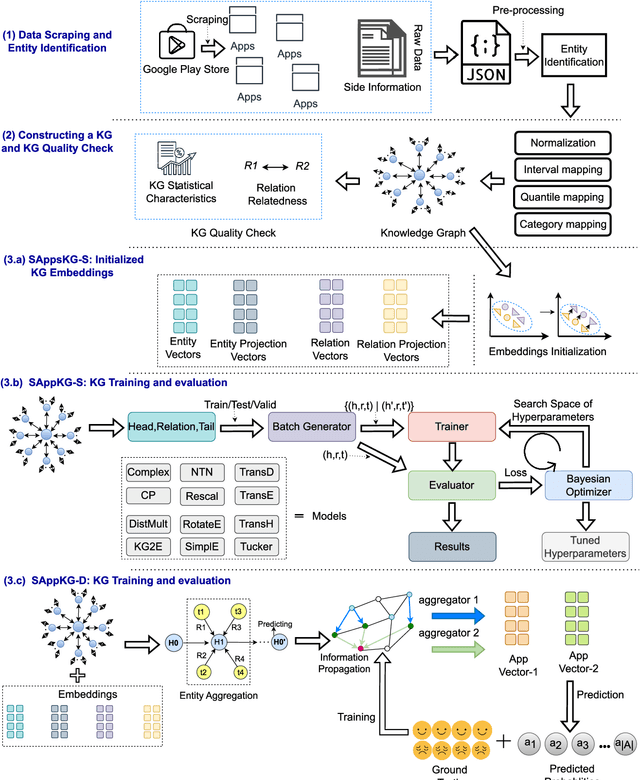
Due to the rapid development of technology and the widespread usage of smartphones, the number of mobile applications is exponentially growing. Finding a suitable collection of apps that aligns with users needs and preferences can be challenging. However, mobile app recommender systems have emerged as a helpful tool in simplifying this process. But there is a drawback to employing app recommender systems. These systems need access to user data, which is a serious security violation. While users seek accurate opinions, they do not want to compromise their privacy in the process. We address this issue by developing SAppKG, an end-to-end user privacy-preserving knowledge graph architecture for mobile app recommendation based on knowledge graph models such as SAppKG-S and SAppKG-D, that utilized the interaction data and side information of app attributes. We tested the proposed model on real-world data from the Google Play app store, using precision, recall, mean absolute precision, and mean reciprocal rank. We found that the proposed model improved results on all four metrics. We also compared the proposed model to baseline models and found that it outperformed them on all four metrics.
Mixture of Weak & Strong Experts on Graphs
Nov 09, 2023Realistic graphs contain both rich self-features of nodes and informative structures of neighborhoods, jointly handled by a GNN in the typical setup. We propose to decouple the two modalities by mixture of weak and strong experts (Mowst), where the weak expert is a light-weight Multi-layer Perceptron (MLP), and the strong expert is an off-the-shelf Graph Neural Network (GNN). To adapt the experts' collaboration to different target nodes, we propose a "confidence" mechanism based on the dispersion of the weak expert's prediction logits. The strong expert is conditionally activated when either the node's classification relies on neighborhood information, or the weak expert has low model quality. We reveal interesting training dynamics by analyzing the influence of the confidence function on loss: our training algorithm encourages the specialization of each expert by effectively generating soft splitting of the graph. In addition, our "confidence" design imposes a desirable bias toward the strong expert to benefit from GNN's better generalization capability. Mowst is easy to optimize and achieves strong expressive power, with a computation cost comparable to a single GNN. Empirically, Mowst shows significant accuracy improvement on 6 standard node classification benchmarks (including both homophilous and heterophilous graphs).
A Single 2D Pose with Context is Worth Hundreds for 3D Human Pose Estimation
Nov 09, 2023The dominant paradigm in 3D human pose estimation that lifts a 2D pose sequence to 3D heavily relies on long-term temporal clues (i.e., using a daunting number of video frames) for improved accuracy, which incurs performance saturation, intractable computation and the non-causal problem. This can be attributed to their inherent inability to perceive spatial context as plain 2D joint coordinates carry no visual cues. To address this issue, we propose a straightforward yet powerful solution: leveraging the readily available intermediate visual representations produced by off-the-shelf (pre-trained) 2D pose detectors -- no finetuning on the 3D task is even needed. The key observation is that, while the pose detector learns to localize 2D joints, such representations (e.g., feature maps) implicitly encode the joint-centric spatial context thanks to the regional operations in backbone networks. We design a simple baseline named Context-Aware PoseFormer to showcase its effectiveness. Without access to any temporal information, the proposed method significantly outperforms its context-agnostic counterpart, PoseFormer, and other state-of-the-art methods using up to hundreds of video frames regarding both speed and precision. Project page: https://qitaozhao.github.io/ContextAware-PoseFormer
Enhancing Instance-Level Image Classification with Set-Level Labels
Nov 09, 2023Instance-level image classification tasks have traditionally relied on single-instance labels to train models, e.g., few-shot learning and transfer learning. However, set-level coarse-grained labels that capture relationships among instances can provide richer information in real-world scenarios. In this paper, we present a novel approach to enhance instance-level image classification by leveraging set-level labels. We provide a theoretical analysis of the proposed method, including recognition conditions for fast excess risk rate, shedding light on the theoretical foundations of our approach. We conducted experiments on two distinct categories of datasets: natural image datasets and histopathology image datasets. Our experimental results demonstrate the effectiveness of our approach, showcasing improved classification performance compared to traditional single-instance label-based methods. Notably, our algorithm achieves 13% improvement in classification accuracy compared to the strongest baseline on the histopathology image classification benchmarks. Importantly, our experimental findings align with the theoretical analysis, reinforcing the robustness and reliability of our proposed method. This work bridges the gap between instance-level and set-level image classification, offering a promising avenue for advancing the capabilities of image classification models with set-level coarse-grained labels.
Detecting Suspicious Commenter Mob Behaviors on YouTube Using Graph2Vec
Nov 09, 2023YouTube, a widely popular online platform, has transformed the dynamics of con-tent consumption and interaction for users worldwide. With its extensive range of content crea-tors and viewers, YouTube serves as a hub for video sharing, entertainment, and information dissemination. However, the exponential growth of users and their active engagement on the platform has raised concerns regarding suspicious commenter behaviors, particularly in the com-ment section. This paper presents a social network analysis-based methodology for detecting suspicious commenter mob-like behaviors among YouTube channels and the similarities therein. The method aims to characterize channels based on the level of such behavior and identify com-mon patterns across them. To evaluate the effectiveness of the proposed model, we conducted an analysis of 20 YouTube channels, consisting of 7,782 videos, 294,199 commenters, and 596,982 comments. These channels were specifically selected for propagating false views about the U.S. Military. The analysis revealed significant similarities among the channels, shedding light on the prevalence of suspicious commenter behavior. By understanding these similarities, we contribute to a better understanding of the dynamics of suspicious behavior on YouTube channels, which can inform strategies for addressing and mitigating such behavior.
Unveiling the Potential of Probabilistic Embeddings in Self-Supervised Learning
Oct 27, 2023In recent years, self-supervised learning has played a pivotal role in advancing machine learning by allowing models to acquire meaningful representations from unlabeled data. An intriguing research avenue involves developing self-supervised models within an information-theoretic framework, but many studies often deviate from the stochasticity assumptions made when deriving their objectives. To gain deeper insights into this issue, we propose to explicitly model the representation with stochastic embeddings and assess their effects on performance, information compression and potential for out-of-distribution detection. From an information-theoretic perspective, we seek to investigate the impact of probabilistic modeling on the information bottleneck, shedding light on a trade-off between compression and preservation of information in both representation and loss space. Emphasizing the importance of distinguishing between these two spaces, we demonstrate how constraining one can affect the other, potentially leading to performance degradation. Moreover, our findings suggest that introducing an additional bottleneck in the loss space can significantly enhance the ability to detect out-of-distribution examples, only leveraging either representation features or the variance of their underlying distribution.
Blockchain-Enabled Federated Learning Approach for Vehicular Networks
Nov 10, 2023Data from interconnected vehicles may contain sensitive information such as location, driving behavior, personal identifiers, etc. Without adequate safeguards, sharing this data jeopardizes data privacy and system security. The current centralized data-sharing paradigm in these systems raises particular concerns about data privacy. Recognizing these challenges, the shift towards decentralized interactions in technology, as echoed by the principles of Industry 5.0, becomes paramount. This work is closely aligned with these principles, emphasizing decentralized, human-centric, and secure technological interactions in an interconnected vehicular ecosystem. To embody this, we propose a practical approach that merges two emerging technologies: Federated Learning (FL) and Blockchain. The integration of these technologies enables the creation of a decentralized vehicular network. In this setting, vehicles can learn from each other without compromising privacy while also ensuring data integrity and accountability. Initial experiments show that compared to conventional decentralized federated learning techniques, our proposed approach significantly enhances the performance and security of vehicular networks. The system's accuracy stands at 91.92\%. While this may appear to be low in comparison to state-of-the-art federated learning models, our work is noteworthy because, unlike others, it was achieved in a malicious vehicle setting. Despite the challenging environment, our method maintains high accuracy, making it a competent solution for preserving data privacy in vehicular networks.
Resolving uncertainty on the fly: Modeling adaptive driving behavior as active inference
Nov 10, 2023Understanding adaptive human driving behavior, in particular how drivers manage uncertainty, is of key importance for developing simulated human driver models that can be used in the evaluation and development of autonomous vehicles. However, existing traffic psychology models of adaptive driving behavior either lack computational rigor or only address specific scenarios and/or behavioral phenomena. While models developed in the fields of machine learning and robotics can effectively learn adaptive driving behavior from data, due to their black box nature, they offer little or no explanation of the mechanisms underlying the adaptive behavior. Thus, a generalizable, interpretable, computational model of adaptive human driving behavior is still lacking. This paper proposes such a model based on active inference, a behavioral modeling framework originating in computational neuroscience. The model offers a principled solution to how humans trade progress against caution through policy selection based on the single mandate to minimize expected free energy. This casts goal-seeking and information-seeking (uncertainty-resolving) behavior under a single objective function, allowing the model to seamlessly resolve uncertainty as a means to obtain its goals. We apply the model in two apparently disparate driving scenarios that require managing uncertainty, (1) driving past an occluding object and (2) visual time sharing between driving and a secondary task, and show how human-like adaptive driving behavior emerges from the single principle of expected free energy minimization.
Polar-Net: A Clinical-Friendly Model for Alzheimer's Disease Detection in OCTA Images
Nov 10, 2023Optical Coherence Tomography Angiography (OCTA) is a promising tool for detecting Alzheimer's disease (AD) by imaging the retinal microvasculature. Ophthalmologists commonly use region-based analysis, such as the ETDRS grid, to study OCTA image biomarkers and understand the correlation with AD. However, existing studies have used general deep computer vision methods, which present challenges in providing interpretable results and leveraging clinical prior knowledge. To address these challenges, we propose a novel deep-learning framework called Polar-Net. Our approach involves mapping OCTA images from Cartesian coordinates to polar coordinates, which allows for the use of approximate sector convolution and enables the implementation of the ETDRS grid-based regional analysis method commonly used in clinical practice. Furthermore, Polar-Net incorporates clinical prior information of each sector region into the training process, which further enhances its performance. Additionally, our framework adapts to acquire the importance of the corresponding retinal region, which helps researchers and clinicians understand the model's decision-making process in detecting AD and assess its conformity to clinical observations. Through evaluations on private and public datasets, we have demonstrated that Polar-Net outperforms existing state-of-the-art methods and provides more valuable pathological evidence for the association between retinal vascular changes and AD. In addition, we also show that the two innovative modules introduced in our framework have a significant impact on improving overall performance.