 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bridging the Gap between Multi-focus and Multi-modal: A Focused Integration Framework for Multi-modal Image Fusion
Nov 03, 2023
Multi-modal image fusion (MMIF) integrates valuable information from different modality images into a fused one. However, the fusion of multiple visible images with different focal regions and infrared images is a unprecedented challenge in real MMIF applications. This is because of the limited depth of the focus of visible optical lenses, which impedes the simultaneous capture of the focal information within the same scene. To address this issue, in this paper, we propose a MMIF framework for joint focused integration and modalities information extraction. Specifically, a semi-sparsity-based smoothing filter is introduced to decompose the images into structure and texture components. Subsequently, a novel multi-scale operator is proposed to fuse the texture components, capable of detecting significant information by considering the pixel focus attributes and relevant data from various modal images. Additionally, to achieve an effective capture of scene luminance and reasonable contrast maintenance, we consider the distribution of energy information in the structural components in terms of multi-directional frequency variance and information entropy. Extensive experiments on existing MMIF datasets, as well as the object detection and depth estimation tasks, consistently demonstrate that the proposed algorithm can surpass the state-of-the-art methods in visual perception and quantitative evaluation. The code is available at https://github.com/ixilai/MFIF-MMIF.
Learning Decentralized Traffic Signal Controllers with Multi-Agent Graph Reinforcement Learning
Nov 07, 2023
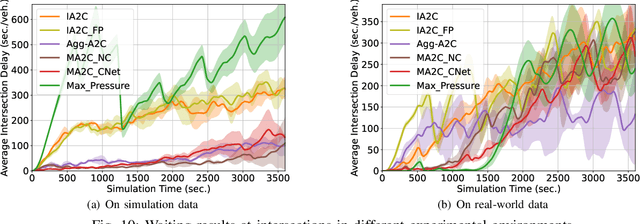
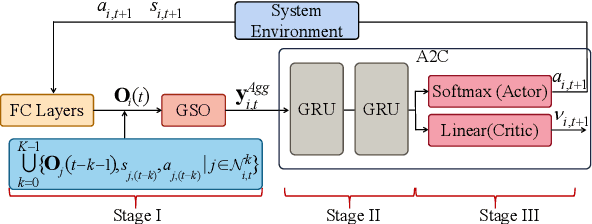

This paper considers optimal traffic signal control in smart cities, which has been taken as a complex networked system control problem. Given the interacting dynamics among traffic lights and road networks, attaining controller adaptivity and scalability stands out as a primary challenge. Capturing the spatial-temporal correlation among traffic lights under the framework of Multi-Agent Reinforcement Learning (MARL) is a promising solution. Nevertheless, existing MARL algorithms ignore effective information aggregation which is fundamental for improving the learning capacity of decentralized agents. In this paper, we design a new decentralized control architecture with improved environmental observability to capture the spatial-temporal correlation. Specifically, we first develop a topology-aware information aggregation strategy to extract correlation-related information from unstructured data gathered in the road network. Particularly, we transfer the road network topology into a graph shift operator by forming a diffusion process on the topology, which subsequently facilitates the construction of graph signals. A diffusion convolution module is developed, forming a new MARL algorithm, which endows agents with the capabilities of graph learning. Extensive experiments based on both synthetic and real-world datasets verify that our proposal outperforms existing decentralized algorithms.
Image-Pointcloud Fusion based Anomaly Detection using PD-REAL Dataset
Nov 07, 2023We present PD-REAL, a novel large-scale dataset for unsupervised anomaly detection (AD) in the 3D domain. It is motivated by the fact that 2D-only representations in the AD task may fail to capture the geometric structures of anomalies due to uncertainty in lighting conditions or shooting angles. PD-REAL consists entirely of Play-Doh models for 15 object categories and focuses on the analysis of potential benefits from 3D information in a controlled environment. Specifically, objects are first created with six types of anomalies, such as dent, crack, or perforation, and then photographed under different lighting conditions to mimic real-world inspection scenarios. To demonstrate the usefulness of 3D information, we use a commercially available RealSense camera to capture RGB and depth images. Compared to the existing 3D dataset for AD tasks, the data acquisition of PD-REAL is significantly cheaper, easily scalable and easier to control variables. Extensive evaluations with state-of-the-art AD algorithms on our dataset demonstrate the benefits as well as challenges of using 3D information. Our dataset can be downloaded from https://github.com/Andy-cs008/PD-REAL
Morphology-Enhanced CAM-Guided SAM for weakly supervised Breast Lesion Segmentation
Nov 18, 2023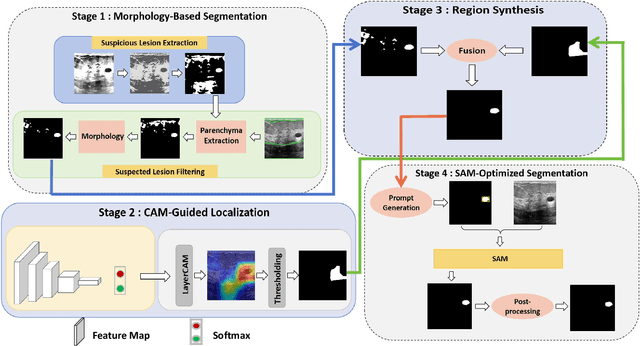
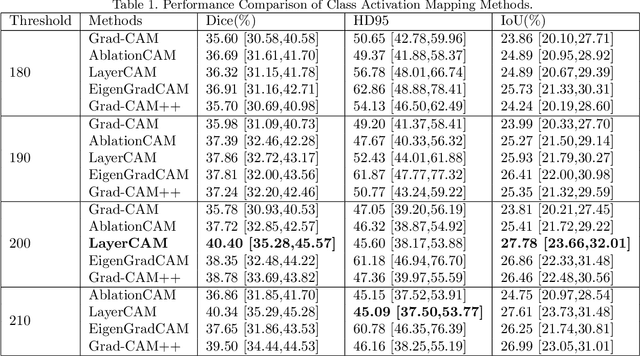
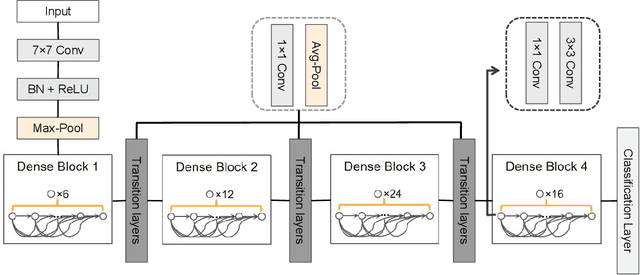
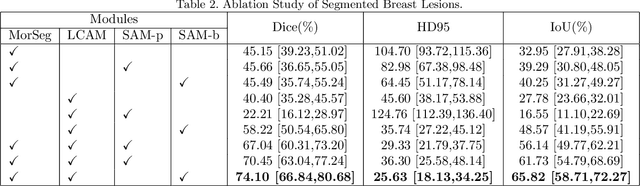
Breast cancer diagnosis challenges both patients and clinicians, with early detection being crucial for effective treatment. Ultrasound imaging plays a key role in this, but its utility is hampered by the need for precise lesion segmentation-a task that is both time-consuming and labor-intensive. To address these challenges, we propose a new framework: a morphology-enhanced, Class Activation Map (CAM)-guided model, which is optimized using a computer vision foundation model known as SAM. This innovative framework is specifically designed for weakly supervised lesion segmentation in early-stage breast ultrasound images. Our approach uniquely leverages image-level annotations, which removes the requirement for detailed pixel-level annotation. Initially, we perform a preliminary segmentation using breast lesion morphology knowledge. Following this, we accurately localize lesions by extracting semantic information through a CAM-based heatmap. These two elements are then fused together, serving as a prompt to guide the SAM in performing refined segmentation. Subsequently, post-processing techniques are employed to rectify topological errors made by the SAM. Our method not only simplifies the segmentation process but also attains accuracy comparable to supervised learning methods that rely on pixel-level annotation. Our framework achieves a Dice score of 74.39% on the test set, demonstrating compareable performance with supervised learning methods. Additionally, it outperforms a supervised learning model, in terms of the Hausdorff distance, scoring 24.27 compared to Deeplabv3+'s 32.22. These experimental results showcase its feasibility and superior performance in integrating weakly supervised learning with SAM. The code is made available at: https://github.com/YueXin18/MorSeg-CAM-SAM.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Nov 09, 2023Recent advances such as LLaVA and Mini-GPT4 have successfully integrated visual information into LLMs, yielding inspiring outcomes and giving rise to a new generation of multi-modal LLMs, or MLLMs. Nevertheless, these methods struggle with hallucinations and the mutual interference between tasks. To tackle these problems, we propose an efficient and accurate approach to adapt to downstream tasks by utilizing LLM as a bridge to connect multiple expert models, namely u-LLaVA. Firstly, we incorporate the modality alignment module and multi-task modules into LLM. Then, we reorganize or rebuild multi-type public datasets to enable efficient modality alignment and instruction following. Finally, task-specific information is extracted from the trained LLM and provided to different modules for solving downstream tasks. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also release our model, the generated data, and the code base publicly available.
Finite Mixtures of Multivariate Poisson-Log Normal Factor Analyzers for Clustering Count Data
Nov 13, 2023
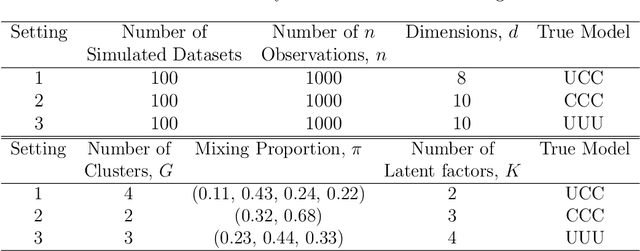
A mixture of multivariate Poisson-log normal factor analyzers is introduced by imposing constraints on the covariance matrix, which resulted in flexible models for clustering purposes. In particular, a class of eight parsimonious mixture models based on the mixtures of factor analyzers model are introduced. Variational Gaussian approximation is used for parameter estimation, and information criteria are used for model selection. The proposed models are explored in the context of clustering discrete data arising from RNA sequencing studies. Using real and simulated data, the models are shown to give favourable clustering performance. The GitHub R package for this work is available at https://github.com/anjalisilva/mixMPLNFA and is released under the open-source MIT license.
Finding and Editing Multi-Modal Neurons in Pre-Trained Transformer
Nov 13, 2023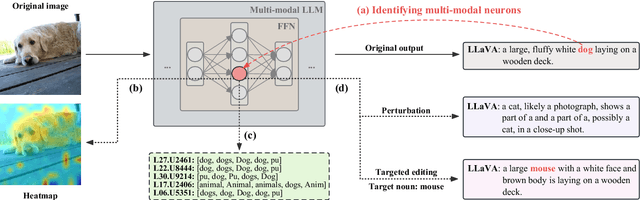

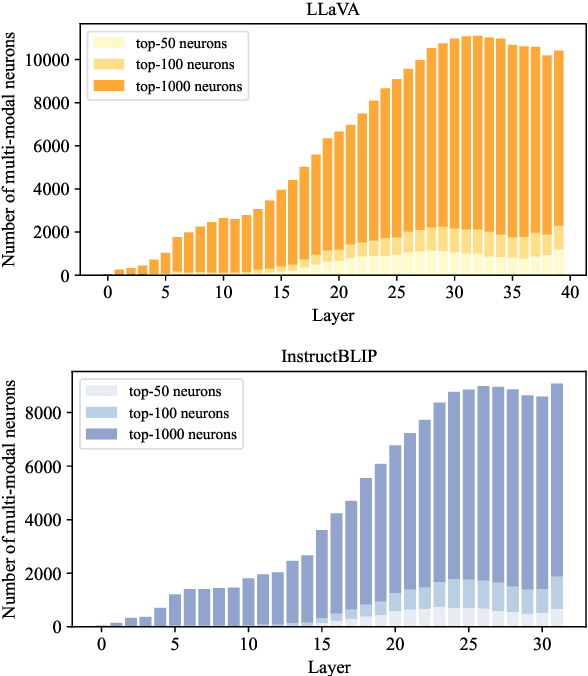
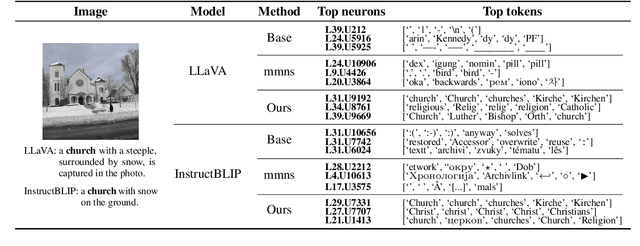
Multi-modal large language models (LLM) have achieved powerful capabilities for visual semantic understanding in recent years. However, little is known about how LLMs comprehend visual information and interpret different modalities of features. In this paper, we propose a new method for identifying multi-modal neurons in transformer-based multi-modal LLMs. Through a series of experiments, We highlight three critical properties of multi-modal neurons by four well-designed quantitative evaluation metrics. Furthermore, we introduce a knowledge editing method based on the identified multi-modal neurons, for modifying a specific token to another designative token. We hope our findings can inspire further explanatory researches on understanding mechanisms of multi-modal LLMs.
TIAGo RL: Simulated Reinforcement Learning Environments with Tactile Data for Mobile Robots
Nov 13, 2023Tactile information is important for robust performance in robotic tasks that involve physical interaction, such as object manipulation. However, with more data included in the reasoning and control process, modeling behavior becomes increasingly difficult. Deep Reinforcement Learning (DRL) produced promising results for learning complex behavior in various domains, including tactile-based manipulation in robotics. In this work, we present our open-source reinforcement learning environments for the TIAGo service robot. They produce tactile sensor measurements that resemble those of a real sensorised gripper for TIAGo, encouraging research in transfer learning of DRL policies. Lastly, we show preliminary training results of a learned force control policy and compare it to a classical PI controller.
A Graphical Model of Hurricane Evacuation Behaviors
Nov 16, 2023Natural disasters such as hurricanes are increasing and causing widespread devastation. People's decisions and actions regarding whether to evacuate or not are critical and have a large impact on emergency planning and response. Our interest lies in computationally modeling complex relationships among various factors influencing evacuation decisions. We conducted a study on the evacuation of Hurricane Irma of the 2017 Atlantic hurricane season. The study was guided by the Protection motivation theory (PMT), a widely-used framework to understand people's responses to potential threats. Graphical models were constructed to represent the complex relationships among the factors involved and the evacuation decision. We evaluated different graphical structures based on conditional independence tests using Irma data. The final model largely aligns with PMT. It shows that both risk perception (threat appraisal) and difficulties in evacuation (coping appraisal) influence evacuation decisions directly and independently. Certain information received from media was found to influence risk perception, and through it influence evacuation behaviors indirectly. In addition, several variables were found to influence both risk perception and evacuation behaviors directly, including family and friends' suggestions, neighbors' evacuation behaviors, and evacuation notices from officials.