 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Augmenting Unsupervised Reinforcement Learning with Self-Reference
Nov 16, 2023
Humans possess the ability to draw on past experiences explicitly when learning new tasks and applying them accordingly. We believe this capacity for self-referencing is especially advantageous for reinforcement learning agents in the unsupervised pretrain-then-finetune setting. During pretraining, an agent's past experiences can be explicitly utilized to mitigate the nonstationarity of intrinsic rewards. In the finetuning phase, referencing historical trajectories prevents the unlearning of valuable exploratory behaviors. Motivated by these benefits, we propose the Self-Reference (SR) approach, an add-on module explicitly designed to leverage historical information and enhance agent performance within the pretrain-finetune paradigm. Our approach achieves state-of-the-art results in terms of Interquartile Mean (IQM) performance and Optimality Gap reduction on the Unsupervised Reinforcement Learning Benchmark for model-free methods, recording an 86% IQM and a 16% Optimality Gap. Additionally, it improves current algorithms by up to 17% IQM and reduces the Optimality Gap by 31%. Beyond performance enhancement, the Self-Reference add-on also increases sample efficiency, a crucial attribute for real-world applications.
Leveraging Transformers to Improve Breast Cancer Classification and Risk Assessment with Multi-modal and Longitudinal Data
Nov 15, 2023Breast cancer screening, primarily conducted through mammography, is often supplemented with ultrasound for women with dense breast tissue. However, existing deep learning models analyze each modality independently, missing opportunities to integrate information across imaging modalities and time. In this study, we present Multi-modal Transformer (MMT), a neural network that utilizes mammography and ultrasound synergistically, to identify patients who currently have cancer and estimate the risk of future cancer for patients who are currently cancer-free. MMT aggregates multi-modal data through self-attention and tracks temporal tissue changes by comparing current exams to prior imaging. Trained on 1.3 million exams, MMT achieves an AUROC of 0.943 in detecting existing cancers, surpassing strong uni-modal baselines. For 5-year risk prediction, MMT attains an AUROC of 0.826, outperforming prior mammography-based risk models. Our research highlights the value of multi-modal and longitudinal imaging in cancer diagnosis and risk stratification.
Towards Publicly Accountable Frontier LLMs: Building an External Scrutiny Ecosystem under the ASPIRE Framework
Nov 15, 2023With the increasing integration of frontier large language models (LLMs) into society and the economy, decisions related to their training, deployment, and use have far-reaching implications. These decisions should not be left solely in the hands of frontier LLM developers. LLM users, civil society and policymakers need trustworthy sources of information to steer such decisions for the better. Involving outside actors in the evaluation of these systems - what we term 'external scrutiny' - via red-teaming, auditing, and external researcher access, offers a solution. Though there are encouraging signs of increasing external scrutiny of frontier LLMs, its success is not assured. In this paper, we survey six requirements for effective external scrutiny of frontier AI systems and organize them under the ASPIRE framework: Access, Searching attitude, Proportionality to the risks, Independence, Resources, and Expertise. We then illustrate how external scrutiny might function throughout the AI lifecycle and offer recommendations to policymakers.
Bit Cipher -- A Simple yet Powerful Word Representation System that Integrates Efficiently with Language Models
Nov 18, 2023While Large Language Models (LLMs) become ever more dominant, classic pre-trained word embeddings sustain their relevance through computational efficiency and nuanced linguistic interpretation. Drawing from recent studies demonstrating that the convergence of GloVe and word2vec optimizations all tend towards log-co-occurrence matrix variants, we construct a novel word representation system called Bit-cipher that eliminates the need of backpropagation while leveraging contextual information and hyper-efficient dimensionality reduction techniques based on unigram frequency, providing strong interpretability, alongside efficiency. We use the bit-cipher algorithm to train word vectors via a two-step process that critically relies on a hyperparameter -- bits -- that controls the vector dimension. While the first step trains the bit-cipher, the second utilizes it under two different aggregation modes -- summation or concatenation -- to produce contextually rich representations from word co-occurrences. We extend our investigation into bit-cipher's efficacy, performing probing experiments on part-of-speech (POS) tagging and named entity recognition (NER) to assess its competitiveness with classic embeddings like word2vec and GloVe. Additionally, we explore its applicability in LM training and fine-tuning. By replacing embedding layers with cipher embeddings, our experiments illustrate the notable efficiency of cipher in accelerating the training process and attaining better optima compared to conventional training paradigms. Experiments on the integration of bit-cipher embedding layers with Roberta, T5, and OPT, prior to or as a substitute for fine-tuning, showcase a promising enhancement to transfer learning, allowing rapid model convergence while preserving competitive performance.
Low-Precision Floating-Point for Efficient On-Board Deep Neural Network Processing
Nov 18, 2023One of the major bottlenecks in high-resolution Earth Observation (EO) space systems is the downlink between the satellite and the ground. Due to hardware limitations, on-board power limitations or ground-station operation costs, there is a strong need to reduce the amount of data transmitted. Various processing methods can be used to compress the data. One of them is the use of on-board deep learning to extract relevant information in the data. However, most ground-based deep neural network parameters and computations are performed using single-precision floating-point arithmetic, which is not adapted to the context of on-board processing. We propose to rely on quantized neural networks and study how to combine low precision (mini) floating-point arithmetic with a Quantization-Aware Training methodology. We evaluate our approach with a semantic segmentation task for ship detection using satellite images from the Airbus Ship dataset. Our results show that 6-bit floating-point quantization for both weights and activations can compete with single-precision without significant accuracy degradation. Using a Thin U-Net 32 model, only a 0.3% accuracy degradation is observed with 6-bit minifloat quantization (a 6-bit equivalent integer-based approach leads to a 0.5% degradation). An initial hardware study also confirms the potential impact of such low-precision floating-point designs, but further investigation at the scale of a full inference accelerator is needed before concluding whether they are relevant in a practical on-board scenario.
Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
Sep 21, 2023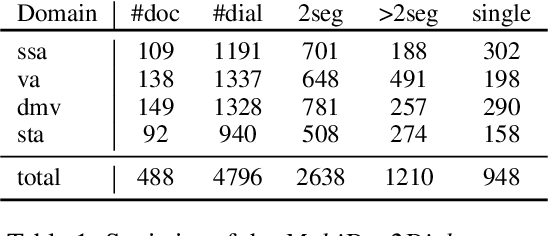
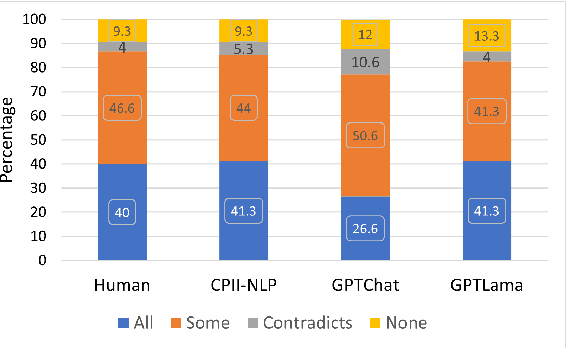
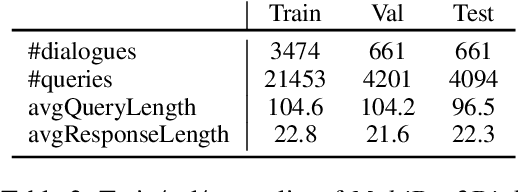

In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
Enhancing data efficiency in reinforcement learning: a novel imagination mechanism based on mesh information propagation
Sep 27, 2023Reinforcement learning(RL) algorithms face the challenge of limited data efficiency, particularly when dealing with high-dimensional state spaces and large-scale problems. Most of RL methods often rely solely on state transition information within the same episode when updating the agent's Critic, which can lead to low data efficiency and sub-optimal training time consumption. Inspired by human-like analogical reasoning abilities, we introduce a novel mesh information propagation mechanism, termed the 'Imagination Mechanism (IM)', designed to significantly enhance the data efficiency of RL algorithms. Specifically, IM enables information generated by a single sample to be effectively broadcasted to different states across episodes, instead of simply transmitting in the same episode. This capability enhances the model's comprehension of state interdependencies and facilitates more efficient learning of limited sample information. To promote versatility, we extend the IM to function as a plug-and-play module that can be seamlessly and fluidly integrated into other widely adopted RL algorithms. Our experiments demonstrate that IM consistently boosts four mainstream SOTA RL algorithms, such as SAC, PPO, DDPG, and DQN, by a considerable margin, ultimately leading to superior performance than before across various tasks. For access to our code and data, please visit https://github.com/OuAzusaKou/imagination_mechanism
EvoFed: Leveraging Evolutionary Strategies for Communication-Efficient Federated Learning
Nov 13, 2023Federated Learning (FL) is a decentralized machine learning paradigm that enables collaborative model training across dispersed nodes without having to force individual nodes to share data. However, its broad adoption is hindered by the high communication costs of transmitting a large number of model parameters. This paper presents EvoFed, a novel approach that integrates Evolutionary Strategies (ES) with FL to address these challenges. EvoFed employs a concept of 'fitness-based information sharing', deviating significantly from the conventional model-based FL. Rather than exchanging the actual updated model parameters, each node transmits a distance-based similarity measure between the locally updated model and each member of the noise-perturbed model population. Each node, as well as the server, generates an identical population set of perturbed models in a completely synchronized fashion using the same random seeds. With properly chosen noise variance and population size, perturbed models can be combined to closely reflect the actual model updated using the local dataset, allowing the transmitted similarity measures (or fitness values) to carry nearly the complete information about the model parameters. As the population size is typically much smaller than the number of model parameters, the savings in communication load is large. The server aggregates these fitness values and is able to update the global model. This global fitness vector is then disseminated back to the nodes, each of which applies the same update to be synchronized to the global model. Our analysis shows that EvoFed converges, and our experimental results validate that at the cost of increased local processing loads, EvoFed achieves performance comparable to FedAvg while reducing overall communication requirements drastically in various practical settings.
Accelerating L-shaped Two-stage Stochastic SCUC with Learning Integrated Benders Decomposition
Nov 17, 2023Benders decomposition is widely used to solve large mixed-integer problems. This paper takes advantage of machine learning and proposes enhanced variants of Benders decomposition for solving two-stage stochastic security-constrained unit commitment (SCUC). The problem is decomposed into a master problem and subproblems corresponding to a load scenario. The goal is to reduce the computational costs and memory usage of Benders decomposition by creating tighter cuts and reducing the size of the master problem. Three approaches are proposed, namely regression Benders, classification Benders, and regression-classification Benders. A regressor reads load profile scenarios and predicts subproblem objective function proxy variables to form tighter cuts for the master problem. A criterion is defined to measure the level of usefulness of cuts with respect to their contribution to lower bound improvement. Useful cuts that contain the necessary information to form the feasible region are identified with and without a classification learner. Useful cuts are iteratively added to the master problem, and non-useful cuts are discarded to reduce the computational burden of each Benders iteration. Simulation studies on multiple test systems show the effectiveness of the proposed learning-aided Benders decomposition for solving two-stage SCUC as compared to conventional multi-cut Benders decomposition.
Breaking Temporal Consistency: Generating Video Universal Adversarial Perturbations Using Image Models
Nov 17, 2023As video analysis using deep learning models becomes more widespread, the vulnerability of such models to adversarial attacks is becoming a pressing concern. In particular, Universal Adversarial Perturbation (UAP) poses a significant threat, as a single perturbation can mislead deep learning models on entire datasets. We propose a novel video UAP using image data and image model. This enables us to take advantage of the rich image data and image model-based studies available for video applications. However, there is a challenge that image models are limited in their ability to analyze the temporal aspects of videos, which is crucial for a successful video attack. To address this challenge, we introduce the Breaking Temporal Consistency (BTC) method, which is the first attempt to incorporate temporal information into video attacks using image models. We aim to generate adversarial videos that have opposite patterns to the original. Specifically, BTC-UAP minimizes the feature similarity between neighboring frames in videos. Our approach is simple but effective at attacking unseen video models. Additionally, it is applicable to videos of varying lengths and invariant to temporal shifts. Our approach surpasses existing methods in terms of effectiveness on various datasets, including ImageNet, UCF-101, and Kinetics-400.