 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MuST: Multimodal Spatiotemporal Graph-Transformer for Hospital Readmission Prediction
Nov 11, 2023
Hospital readmission prediction is considered an essential approach to decreasing readmission rates, which is a key factor in assessing the quality and efficacy of a healthcare system. Previous studies have extensively utilized three primary modalities, namely electronic health records (EHR), medical images, and clinical notes, to predict hospital readmissions. However, the majority of these studies did not integrate information from all three modalities or utilize the spatiotemporal relationships present in the dataset. This study introduces a novel model called the Multimodal Spatiotemporal Graph-Transformer (MuST) for predicting hospital readmissions. By employing Graph Convolution Networks and temporal transformers, we can effectively capture spatial and temporal dependencies in EHR and chest radiographs. We then propose a fusion transformer to combine the spatiotemporal features from the two modalities mentioned above with the features from clinical notes extracted by a pre-trained, domain-specific transformer. We assess the effectiveness of our methods using the latest publicly available dataset, MIMIC-IV. The experimental results indicate that the inclusion of multimodal features in MuST improves its performance in comparison to unimodal methods. Furthermore, our proposed pipeline outperforms the current leading methods in the prediction of hospital readmissions.
From Charts to Atlas: Merging Latent Spaces into One
Nov 11, 2023Models trained on semantically related datasets and tasks exhibit comparable inter-sample relations within their latent spaces. We investigate in this study the aggregation of such latent spaces to create a unified space encompassing the combined information. To this end, we introduce Relative Latent Space Aggregation, a two-step approach that first renders the spaces comparable using relative representations, and then aggregates them via a simple mean. We carefully divide a classification problem into a series of learning tasks under three different settings: sharing samples, classes, or neither. We then train a model on each task and aggregate the resulting latent spaces. We compare the aggregated space with that derived from an end-to-end model trained over all tasks and show that the two spaces are similar. We then observe that the aggregated space is better suited for classification, and empirically demonstrate that it is due to the unique imprints left by task-specific embedders within the representations. We finally test our framework in scenarios where no shared region exists and show that it can still be used to merge the spaces, albeit with diminished benefits over naive merging.
M&M3D: Multi-Dataset Training and Efficient Network for Multi-view 3D Object Detection
Nov 02, 2023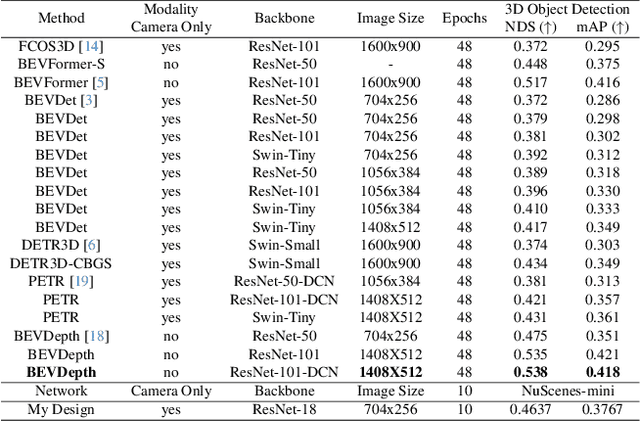
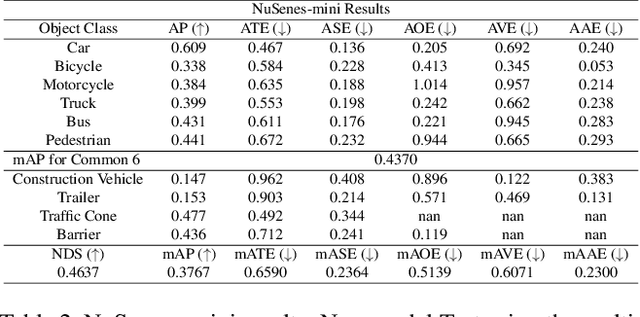
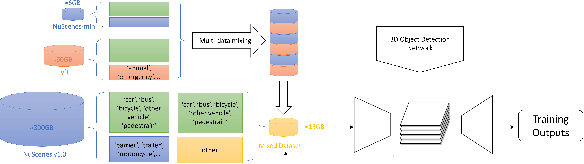
In this research, I proposed a network structure for multi-view 3D object detection using camera-only data and a Bird's-Eye-View map. My work is based on a current key challenge domain adaptation and visual data transfer. Although many excellent camera-only 3D object detection has been continuously proposed, many research work risk dramatic performance drop when the networks are trained on the source domain but tested on a different target domain. Then I found it is very surprising that predictions on bounding boxes and classes are still replied to on 2D networks. Based on the domain gap assumption on various 3D datasets, I found they still shared a similar data extraction on the same BEV map size and camera data transfer. Therefore, to analyze the domain gap influence on the current method and to make good use of 3D space information among the dataset and the real world, I proposed a transfer learning method and Transformer construction to study the 3D object detection on NuScenes-mini and Lyft. Through multi-dataset training and a detection head from the Transformer, the network demonstrated good data migration performance and efficient detection performance by using 3D anchor query and 3D positional information. Relying on only a small amount of source data and the existing large model pre-training weights, the efficient network manages to achieve competitive results on the new target domain. Moreover, my study utilizes 3D information as available semantic information and 2D multi-view image features blending into the visual-language transfer design. In the final 3D anchor box prediction and object classification, my network achieved good results on standard metrics of 3D object detection, which differs from dataset-specific models on each training domain without any fine-tuning.
Improving Korean NLP Tasks with Linguistically Informed Subword Tokenization and Sub-character Decomposition
Nov 07, 2023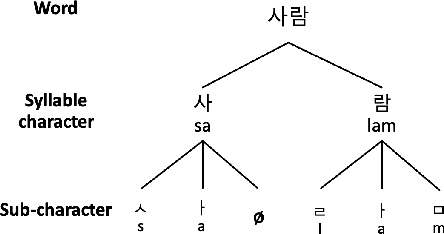

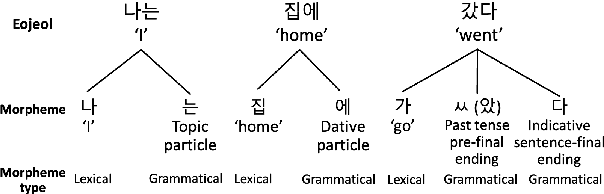
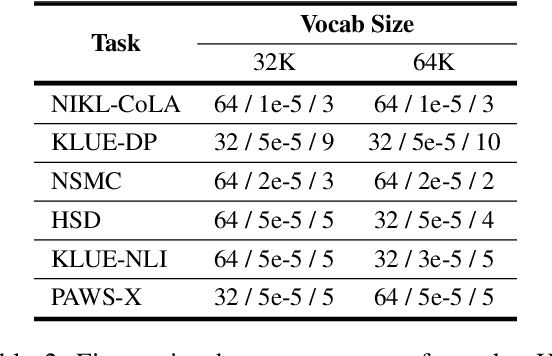
We introduce a morpheme-aware subword tokenization method that utilizes sub-character decomposition to address the challenges of applying Byte Pair Encoding (BPE) to Korean, a language characterized by its rich morphology and unique writing system. Our approach balances linguistic accuracy with computational efficiency in Pre-trained Language Models (PLMs). Our evaluations show that this technique achieves good performances overall, notably improving results in the syntactic task of NIKL-CoLA. This suggests that integrating morpheme type information can enhance language models' syntactic and semantic capabilities, indicating that adopting more linguistic insights can further improve performance beyond standard morphological analysis.
CD-COCO: A Versatile Complex Distorted COCO Database for Scene-Context-Aware Computer Vision
Nov 12, 2023

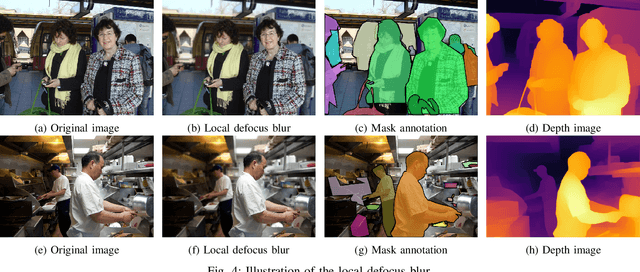
The recent development of deep learning methods applied to vision has enabled their increasing integration into real-world applications to perform complex Computer Vision (CV) tasks. However, image acquisition conditions have a major impact on the performance of high-level image processing. A possible solution to overcome these limitations is to artificially augment the training databases or to design deep learning models that are robust to signal distortions. We opt here for the first solution by enriching the database with complex and realistic distortions which were ignored until now in the existing databases. To this end, we built a new versatile database derived from the well-known MS-COCO database to which we applied local and global photo-realistic distortions. These new local distortions are generated by considering the scene context of the images that guarantees a high level of photo-realism. Distortions are generated by exploiting the depth information of the objects in the scene as well as their semantics. This guarantees a high level of photo-realism and allows to explore real scenarios ignored in conventional databases dedicated to various CV applications. Our versatile database offers an efficient solution to improve the robustness of various CV tasks such as Object Detection (OD), scene segmentation, and distortion-type classification methods. The image database, scene classification index, and distortion generation codes are publicly available \footnote{\url{https://github.com/Aymanbegh/CD-COCO}}
CL-Flow:Strengthening the Normalizing Flows by Contrastive Learning for Better Anomaly Detection
Nov 12, 2023In the anomaly detection field, the scarcity of anomalous samples has directed the current research emphasis towards unsupervised anomaly detection. While these unsupervised anomaly detection methods offer convenience, they also overlook the crucial prior information embedded within anomalous samples. Moreover, among numerous deep learning methods, supervised methods generally exhibit superior performance compared to unsupervised methods. Considering the reasons mentioned above, we propose a self-supervised anomaly detection approach that combines contrastive learning with 2D-Flow to achieve more precise detection outcomes and expedited inference processes. On one hand, we introduce a novel approach to anomaly synthesis, yielding anomalous samples in accordance with authentic industrial scenarios, alongside their surrogate annotations. On the other hand, having obtained a substantial number of anomalous samples, we enhance the 2D-Flow framework by incorporating contrastive learning, leveraging diverse proxy tasks to fine-tune the network. Our approach enables the network to learn more precise mapping relationships from self-generated labels while retaining the lightweight characteristics of the 2D-Flow. Compared to mainstream unsupervised approaches, our self-supervised method demonstrates superior detection accuracy, fewer additional model parameters, and faster inference speed. Furthermore, the entire training and inference process is end-to-end. Our approach showcases new state-of-the-art results, achieving a performance of 99.6\% in image-level AUROC on the MVTecAD dataset and 96.8\% in image-level AUROC on the BTAD dataset.
Improving Whispered Speech Recognition Performance using Pseudo-whispered based Data Augmentation
Nov 09, 2023Whispering is a distinct form of speech known for its soft, breathy, and hushed characteristics, often used for private communication. The acoustic characteristics of whispered speech differ substantially from normally phonated speech and the scarcity of adequate training data leads to low automatic speech recognition (ASR) performance. To address the data scarcity issue, we use a signal processing-based technique that transforms the spectral characteristics of normal speech to those of pseudo-whispered speech. We augment an End-to-End ASR with pseudo-whispered speech and achieve an 18.2% relative reduction in word error rate for whispered speech compared to the baseline. Results for the individual speaker groups in the wTIMIT database show the best results for US English. Further investigation showed that the lack of glottal information in whispered speech has the largest impact on whispered speech ASR performance.
Variational Weighting for Kernel Density Ratios
Nov 06, 2023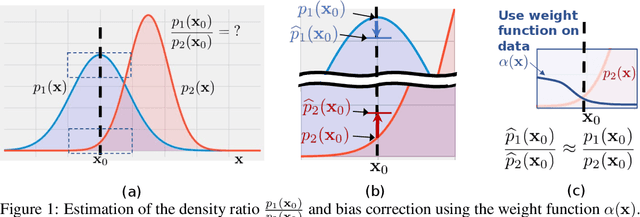
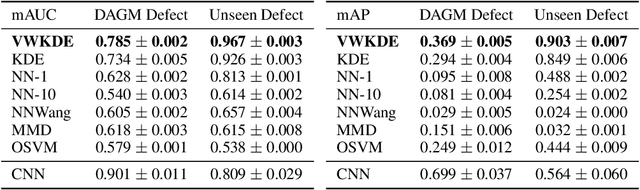
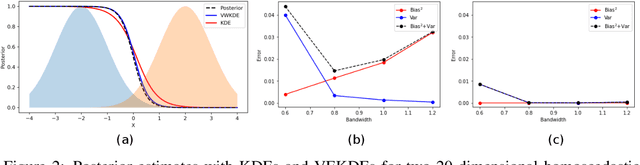
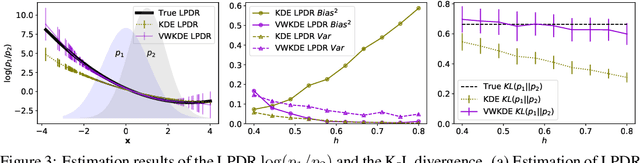
Kernel density estimation (KDE) is integral to a range of generative and discriminative tasks in machine learning. Drawing upon tools from the multidimensional calculus of variations, we derive an optimal weight function that reduces bias in standard kernel density estimates for density ratios, leading to improved estimates of prediction posteriors and information-theoretic measures. In the process, we shed light on some fundamental aspects of density estimation, particularly from the perspective of algorithms that employ KDEs as their main building blocks.
Generalised Mutual Information: a Framework for Discriminative Clustering
Sep 06, 2023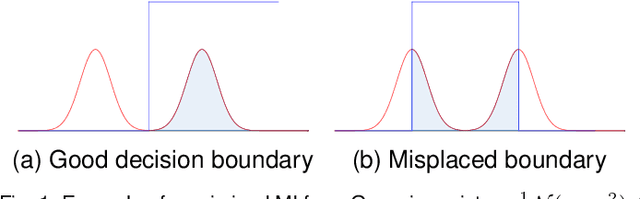

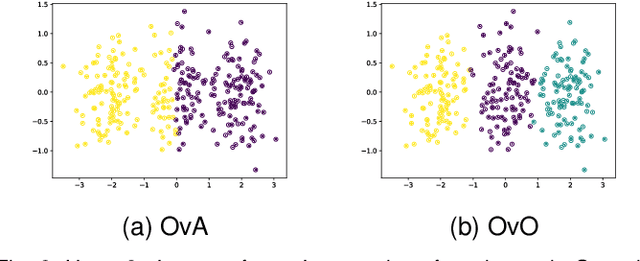
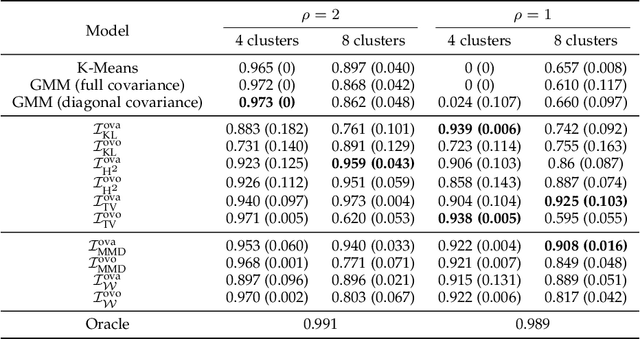
In the last decade, recent successes in deep clustering majorly involved the Mutual Information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the Generalised Mutual Information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training as they are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep discriminative clustering context where the number of clusters is a priori unknown.
FOLLOWUPQG: Towards Information-Seeking Follow-up Question Generation
Sep 10, 2023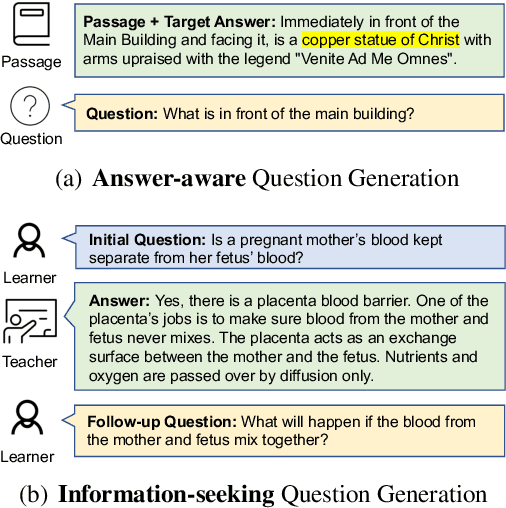

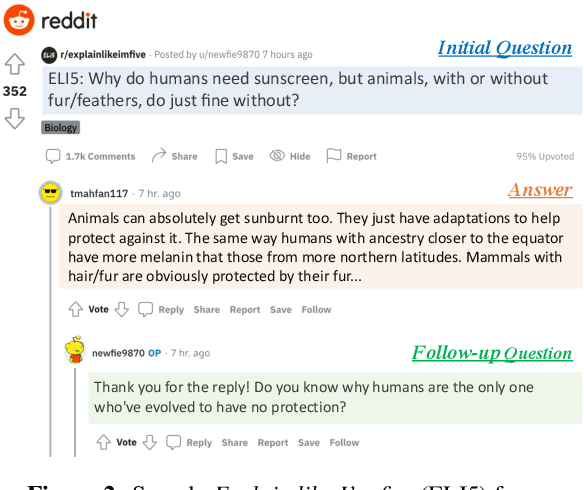
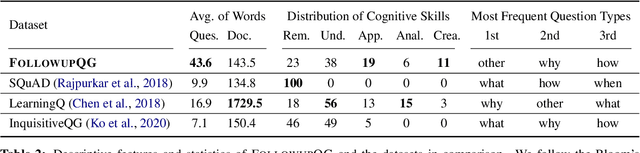
Humans ask follow-up questions driven by curiosity, which reflects a creative human cognitive process. We introduce the task of real-world information-seeking follow-up question generation (FQG), which aims to generate follow-up questions seeking a more in-depth understanding of an initial question and answer. We construct FOLLOWUPQG, a dataset of over 3K real-world (initial question, answer, follow-up question) tuples collected from a Reddit forum providing layman-friendly explanations for open-ended questions. In contrast to existing datasets, questions in FOLLOWUPQG use more diverse pragmatic strategies to seek information, and they also show higher-order cognitive skills (such as applying and relating). We evaluate current question generation models on their efficacy for generating follow-up questions, exploring how to generate specific types of follow-up questions based on step-by-step demonstrations. Our results validate FOLLOWUPQG as a challenging benchmark, as model-generated questions are adequate but far from human-raised questions in terms of informativeness and complexity.