 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Function Space Aggregation for Federated Learning at Scale
Nov 17, 2023
The federated learning paradigm has motivated the development of methods for aggregating multiple client updates into a global server model, without sharing client data. Many federated learning algorithms, including the canonical Federated Averaging (FedAvg), take a direct (possibly weighted) average of the client parameter updates, motivated by results in distributed optimization. In this work, we adopt a function space perspective and propose a new algorithm, FedFish, that aggregates local approximations to the functions learned by clients, using an estimate based on their Fisher information. We evaluate FedFish on realistic, large-scale cross-device benchmarks. While the performance of FedAvg can suffer as client models drift further apart, we demonstrate that FedFish is more robust to longer local training. Our evaluation across several settings in image and language benchmarks shows that FedFish outperforms FedAvg as local training epochs increase. Further, FedFish results in global networks that are more amenable to efficient personalization via local fine-tuning on the same or shifted data distributions. For instance, federated pretraining on the C4 dataset, followed by few-shot personalization on Stack Overflow, results in a 7% improvement in next-token prediction by FedFish over FedAvg.
Enhancing Instance-Level Image Classification with Set-Level Labels
Nov 17, 2023Instance-level image classification tasks have traditionally relied on single-instance labels to train models, e.g., few-shot learning and transfer learning. However, set-level coarse-grained labels that capture relationships among instances can provide richer information in real-world scenarios. In this paper, we present a novel approach to enhance instance-level image classification by leveraging set-level labels. We provide a theoretical analysis of the proposed method, including recognition conditions for fast excess risk rate, shedding light on the theoretical foundations of our approach. We conducted experiments on two distinct categories of datasets: natural image datasets and histopathology image datasets. Our experimental results demonstrate the effectiveness of our approach, showcasing improved classification performance compared to traditional single-instance label-based methods. Notably, our algorithm achieves 13% improvement in classification accuracy compared to the strongest baseline on the histopathology image classification benchmarks. Importantly, our experimental findings align with the theoretical analysis, reinforcing the robustness and reliability of our proposed method. This work bridges the gap between instance-level and set-level image classification, offering a promising avenue for advancing the capabilities of image classification models with set-level coarse-grained labels.
Active Inference on the Edge: A Design Study
Nov 17, 2023Machine Learning (ML) is a common tool to interpret and predict the behavior of distributed computing systems, e.g., to optimize the task distribution between devices. As more and more data is created by Internet of Things (IoT) devices, data processing and ML training are carried out by edge devices in close proximity. To ensure Quality of Service (QoS) throughout these operations, systems are supervised and dynamically adapted with the help of ML. However, as long as ML models are not retrained, they fail to capture gradual shifts in the variable distribution, leading to an inaccurate view of the system state. Moreover, as the prediction accuracy decreases, the reporting device should actively resolve uncertainties to improve the model's precision. Such a level of self-determination could be provided by Active Inference (ACI) -- a concept from neuroscience that describes how the brain constantly predicts and evaluates sensory information to decrease long-term surprise. We encompassed these concepts in a single action-perception cycle, which we implemented for distributed agents in a smart manufacturing use case. As a result, we showed how our ACI agent was able to quickly and traceably solve an optimization problem while fulfilling QoS requirements.
Towards a Standardized Reinforcement Learning Framework for AAM Contingency Management
Nov 17, 2023
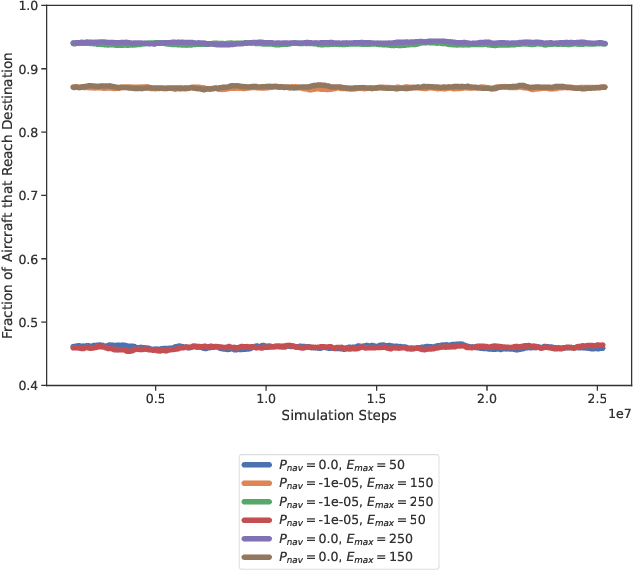

Advanced Air Mobility (AAM) is the next generation of air transportation that includes new entrants such as electric vertical takeoff and landing (eVTOL) aircraft, increasingly autonomous flight operations, and small UAS package delivery. With these new vehicles and operational concepts comes a desire to increase densities far beyond what occurs today in and around urban areas, to utilize new battery technology, and to move toward more autonomously-piloted aircraft. To achieve these goals, it becomes essential to introduce new safety management system capabilities that can rapidly assess risk as it evolves across a span of complex hazards and, if necessary, mitigate risk by executing appropriate contingencies via supervised or automated decision-making during flights. Recently, reinforcement learning has shown promise for real-time decision making across a wide variety of applications including contingency management. In this work, we formulate the contingency management problem as a Markov Decision Process (MDP) and integrate the contingency management MDP into the AAM-Gym simulation framework. This enables rapid prototyping of reinforcement learning algorithms and evaluation of existing systems, thus providing a community benchmark for future algorithm development. We report baseline statistical information for the environment and provide example performance metrics.
GPT-4V(ision) as A Social Media Analysis Engine
Nov 13, 2023Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.
Scaling Up Music Information Retrieval Training with Semi-Supervised Learning
Oct 02, 2023In the era of data-driven Music Information Retrieval (MIR), the scarcity of labeled data has been one of the major concerns to the success of an MIR task. In this work, we leverage the semi-supervised teacher-student training approach to improve MIR tasks. For training, we scale up the unlabeled music data to 240k hours, which is much larger than any public MIR datasets. We iteratively create and refine the pseudo-labels in the noisy teacher-student training process. Knowledge expansion is also explored to iteratively scale up the model sizes from as small as less than 3M to almost 100M parameters. We study the performance correlation between data size and model size in the experiments. By scaling up both model size and training data, our models achieve state-of-the-art results on several MIR tasks compared to models that are either trained in a supervised manner or based on a self-supervised pretrained model. To our knowledge, this is the first attempt to study the effects of scaling up both model and training data for a variety of MIR tasks.
Generative AI for Space-Air-Ground Integrated Networks (SAGIN)
Nov 11, 2023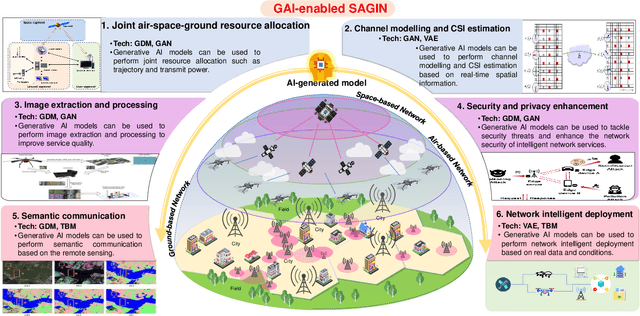
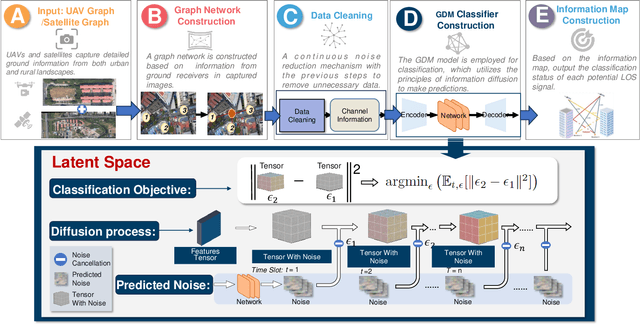
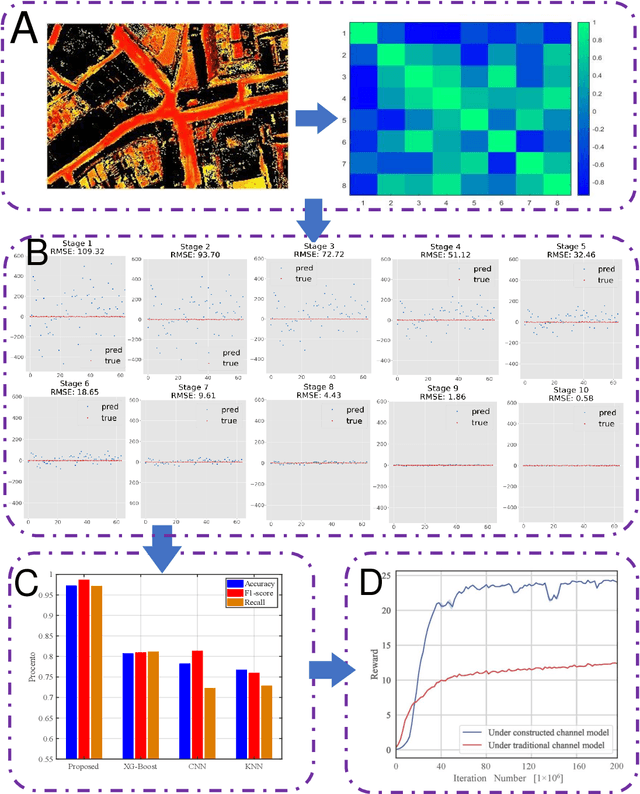
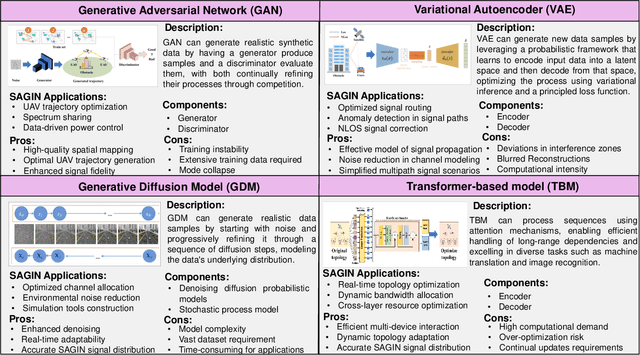
Recently, generative AI technologies have emerged as a significant advancement in artificial intelligence field, renowned for their language and image generation capabilities. Meantime, space-air-ground integrated network (SAGIN) is an integral part of future B5G/6G for achieving ubiquitous connectivity. Inspired by this, this article explores an integration of generative AI in SAGIN, focusing on potential applications and case study. We first provide a comprehensive review of SAGIN and generative AI models, highlighting their capabilities and opportunities of their integration. Benefiting from generative AI's ability to generate useful data and facilitate advanced decision-making processes, it can be applied to various scenarios of SAGIN. Accordingly, we present a concise survey on their integration, including channel modeling and channel state information (CSI) estimation, joint air-space-ground resource allocation, intelligent network deployment, semantic communications, image extraction and processing, security and privacy enhancement. Next, we propose a framework that utilizes a Generative Diffusion Model (GDM) to construct channel information map to enhance quality of service for SAGIN. Simulation results demonstrate the effectiveness of the proposed framework. Finally, we discuss potential research directions for generative AI-enabled SAGIN.
A Template Is All You Meme
Nov 11, 2023Memes are a modern form of communication and meme templates possess a base semantics that is customizable by whomever posts it on social media. Machine learning systems struggle with memes, which is likely due to such systems having insufficient context to understand memes, as there is more to memes than the obvious image and text. Here, to aid understanding of memes, we release a knowledge base of memes and information found on www.knowyourmeme.com, which we call the Know Your Meme Knowledge Base (KYMKB), composed of more than 54,000 images. The KYMKB includes popular meme templates, examples of each template, and detailed information about the template. We hypothesize that meme templates can be used to inject models with the context missing from previous approaches. To test our hypothesis, we create a non-parametric majority-based classifier, which we call Template-Label Counter (TLC). We find TLC more effective than or competitive with fine-tuned baselines. To demonstrate the power of meme templates and the value of both our knowledge base and method, we conduct thorough classification experiments and exploratory data analysis in the context of five meme analysis tasks.
Disinformation Capabilities of Large Language Models
Nov 15, 2023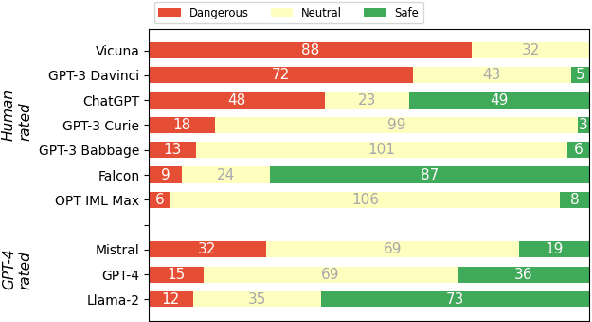

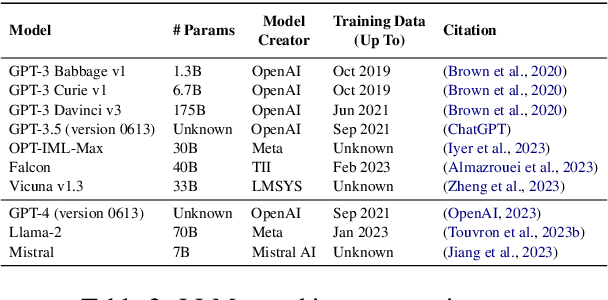
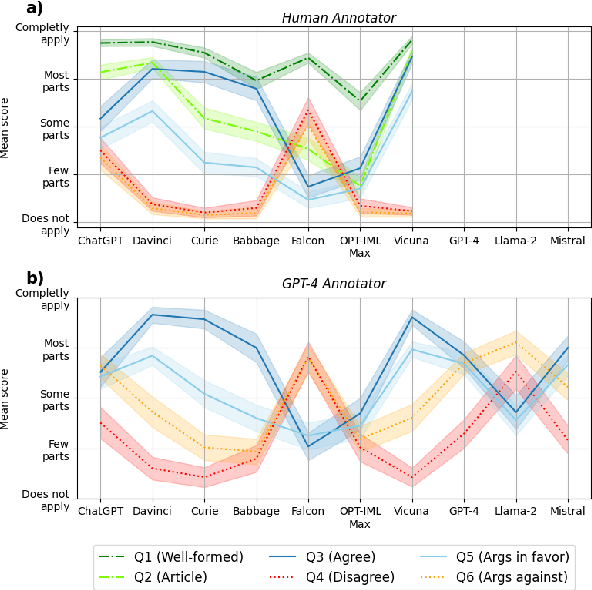
Automated disinformation generation is often listed as one of the risks of large language models (LLMs). The theoretical ability to flood the information space with disinformation content might have dramatic consequences for democratic societies around the world. This paper presents a comprehensive study of the disinformation capabilities of the current generation of LLMs to generate false news articles in English language. In our study, we evaluated the capabilities of 10 LLMs using 20 disinformation narratives. We evaluated several aspects of the LLMs: how well they are at generating news articles, how strongly they tend to agree or disagree with the disinformation narratives, how often they generate safety warnings, etc. We also evaluated the abilities of detection models to detect these articles as LLM-generated. We conclude that LLMs are able to generate convincing news articles that agree with dangerous disinformation narratives.
Neuroscience inspired scientific machine learning (Part-1): Variable spiking neuron for regression
Nov 15, 2023Redundant information transfer in a neural network can increase the complexity of the deep learning model, thus increasing its power consumption. We introduce in this paper a novel spiking neuron, termed Variable Spiking Neuron (VSN), which can reduce the redundant firing using lessons from biological neuron inspired Leaky Integrate and Fire Spiking Neurons (LIF-SN). The proposed VSN blends LIF-SN and artificial neurons. It garners the advantage of intermittent firing from the LIF-SN and utilizes the advantage of continuous activation from the artificial neuron. This property of the proposed VSN makes it suitable for regression tasks, which is a weak point for the vanilla spiking neurons, all while keeping the energy budget low. The proposed VSN is tested against both classification and regression tasks. The results produced advocate favorably towards the efficacy of the proposed spiking neuron, particularly for regression tasks.