 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Risk-averse Batch Active Inverse Reward Design
Nov 20, 2023
Designing a perfect reward function that depicts all the aspects of the intended behavior is almost impossible, especially generalizing it outside of the training environments. Active Inverse Reward Design (AIRD) proposed the use of a series of queries, comparing possible reward functions in a single training environment. This allows the human to give information to the agent about suboptimal behaviors, in order to compute a probability distribution over the intended reward function. However, it ignores the possibility of unknown features appearing in real-world environments, and the safety measures needed until the agent completely learns the reward function. I improved this method and created Risk-averse Batch Active Inverse Reward Design (RBAIRD), which constructs batches, sets of environments the agent encounters when being used in the real world, processes them sequentially, and, for a predetermined number of iterations, asks queries that the human needs to answer for each environment of the batch. After this process is completed in one batch, the probabilities have been improved and are transferred to the next batch. This makes it capable of adapting to real-world scenarios and learning how to treat unknown features it encounters for the first time. I also integrated a risk-averse planner, similar to that of Inverse Reward Design (IRD), which samples a set of reward functions from the probability distribution and computes a trajectory that takes the most certain rewards possible. This ensures safety while the agent is still learning the reward function, and enables the use of this approach in situations where cautiousness is vital. RBAIRD outperformed the previous approaches in terms of efficiency, accuracy, and action certainty, demonstrated quick adaptability to new, unknown features, and can be more widely used for the alignment of crucial, powerful AI models.
A Distributed Multi-Robot Framework for Exploration, Information Acquisition and Consensus
Oct 03, 2023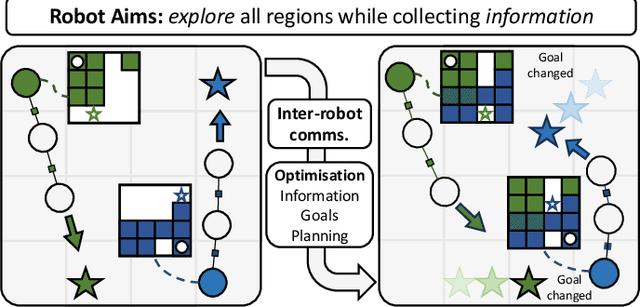
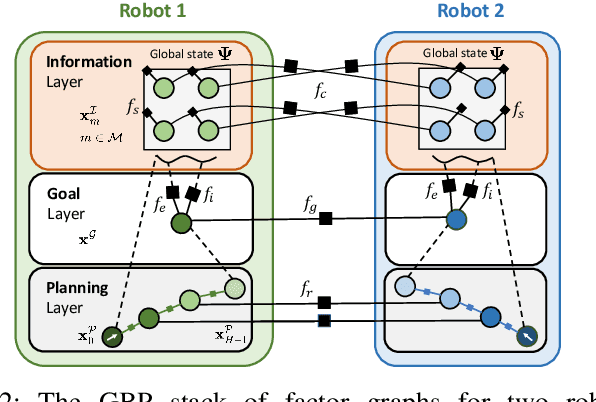
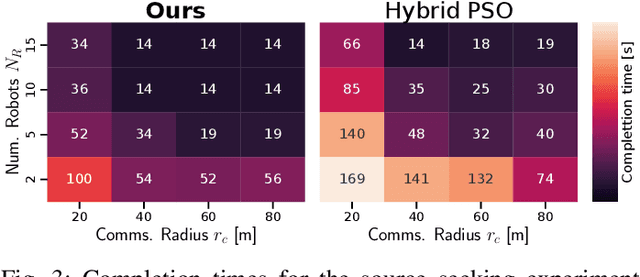

The distributed coordination of robot teams performing complex tasks is challenging to formulate. The different aspects of a complete task such as local planning for obstacle avoidance, global goal coordination and collaborative mapping are often solved separately, when clearly each of these should influence the others for the most efficient behaviour. In this paper we use the example application of distributed information acquisition as a robot team explores a large space to show that we can formulate the whole problem as a single factor graph with multiple connected layers representing each aspect. We use Gaussian Belief Propagation (GBP) as the inference mechanism, which permits parallel, on-demand or asynchronous computation for efficiency when different aspects are more or less important. This is the first time that a distributed GBP multi-robot solver has been proven to enable intelligent collaborative behaviour rather than just guiding robots to individual, selfish goals. We encourage the reader to view our demos at https://aalpatya.github.io/gbpstack
Selective Visual Representations Improve Convergence and Generalization for Embodied AI
Nov 07, 2023Embodied AI models often employ off the shelf vision backbones like CLIP to encode their visual observations. Although such general purpose representations encode rich syntactic and semantic information about the scene, much of this information is often irrelevant to the specific task at hand. This introduces noise within the learning process and distracts the agent's focus from task-relevant visual cues. Inspired by selective attention in humans-the process through which people filter their perception based on their experiences, knowledge, and the task at hand-we introduce a parameter-efficient approach to filter visual stimuli for embodied AI. Our approach induces a task-conditioned bottleneck using a small learnable codebook module. This codebook is trained jointly to optimize task reward and acts as a task-conditioned selective filter over the visual observation. Our experiments showcase state-of-the-art performance for object goal navigation and object displacement across 5 benchmarks, ProcTHOR, ArchitecTHOR, RoboTHOR, AI2-iTHOR, and ManipulaTHOR. The filtered representations produced by the codebook are also able generalize better and converge faster when adapted to other simulation environments such as Habitat. Our qualitative analyses show that agents explore their environments more effectively and their representations retain task-relevant information like target object recognition while ignoring superfluous information about other objects. Code and pretrained models are available at our project website: https://embodied-codebook.github.io.
AdVENTR: Autonomous Robot Navigation in Complex Outdoor Environments
Nov 15, 2023We present a novel system, AdVENTR for autonomous robot navigation in unstructured outdoor environments that consist of uneven and vegetated terrains. Our approach is general and can enable both wheeled and legged robots to handle outdoor terrain complexity including unevenness, surface properties like poor traction, granularity, obstacle stiffness, etc. We use data from sensors including RGB cameras, 3D Lidar, IMU, robot odometry, and pose information with efficient learning-based perception and planning algorithms that can execute on edge computing hardware. Our system uses a scene-aware switching method to perceive the environment for navigation at any time instant and dynamically switches between multiple perception algorithms. We test our system in a variety of sloped, rocky, muddy, and densely vegetated terrains and demonstrate its performance on Husky and Spot robots.
Improving Large-scale Deep Biasing with Phoneme Features and Text-only Data in Streaming Transducer
Nov 15, 2023Deep biasing for the Transducer can improve the recognition performance of rare words or contextual entities, which is essential in practical applications, especially for streaming Automatic Speech Recognition (ASR). However, deep biasing with large-scale rare words remains challenging, as the performance drops significantly when more distractors exist and there are words with similar grapheme sequences in the bias list. In this paper, we combine the phoneme and textual information of rare words in Transducers to distinguish words with similar pronunciation or spelling. Moreover, the introduction of training with text-only data containing more rare words benefits large-scale deep biasing. The experiments on the LibriSpeech corpus demonstrate that the proposed method achieves state-of-the-art performance on rare word error rate for different scales and levels of bias lists.
Non-Uniform Smoothness for Gradient Descent
Nov 15, 2023The analysis of gradient descent-type methods typically relies on the Lipschitz continuity of the objective gradient. This generally requires an expensive hyperparameter tuning process to appropriately calibrate a stepsize for a given problem. In this work we introduce a local first-order smoothness oracle (LFSO) which generalizes the Lipschitz continuous gradients smoothness condition and is applicable to any twice-differentiable function. We show that this oracle can encode all relevant problem information for tuning stepsizes for a suitably modified gradient descent method and give global and local convergence results. We also show that LFSOs in this modified first-order method can yield global linear convergence rates for non-strongly convex problems with extremely flat minima, and thus improve over the lower bound on rates achievable by general (accelerated) first-order methods.
Assessing the Robustness of Intelligence-Driven Reinforcement Learning
Nov 15, 2023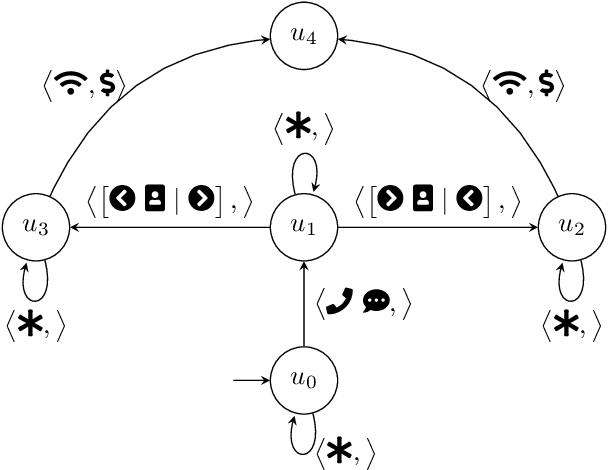
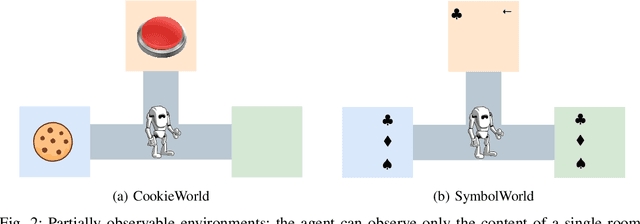
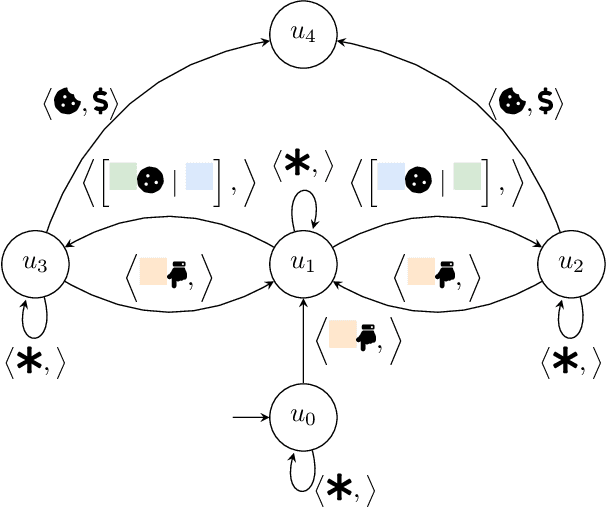
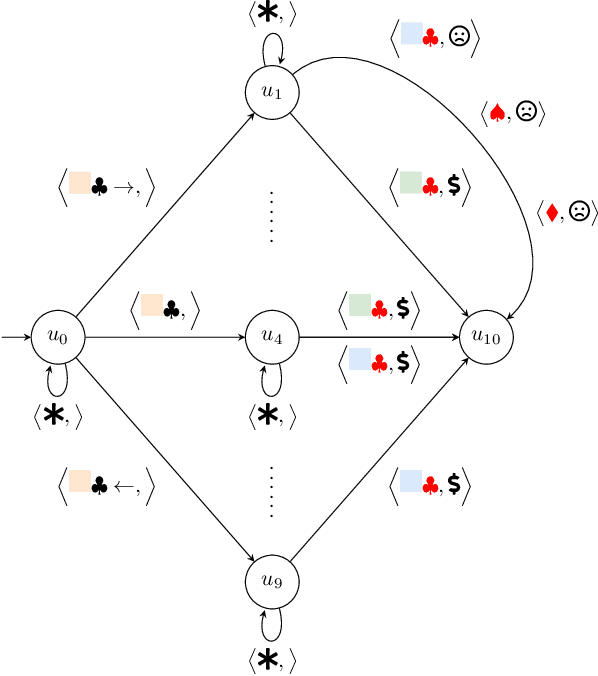
Robustness to noise is of utmost importance in reinforcement learning systems, particularly in military contexts where high stakes and uncertain environments prevail. Noise and uncertainty are inherent features of military operations, arising from factors such as incomplete information, adversarial actions, or unpredictable battlefield conditions. In RL, noise can critically impact decision-making, mission success, and the safety of personnel. Reward machines offer a powerful tool to express complex reward structures in RL tasks, enabling the design of tailored reinforcement signals that align with mission objectives. This paper considers the problem of the robustness of intelligence-driven reinforcement learning based on reward machines. The preliminary results presented suggest the need for further research in evidential reasoning and learning to harden current state-of-the-art reinforcement learning approaches before being mission-critical-ready.
On the Overconfidence Problem in Semantic 3D Mapping
Nov 16, 2023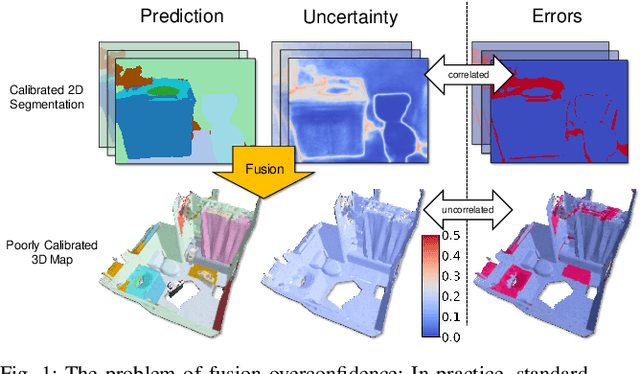
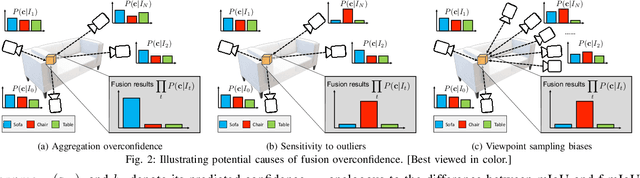
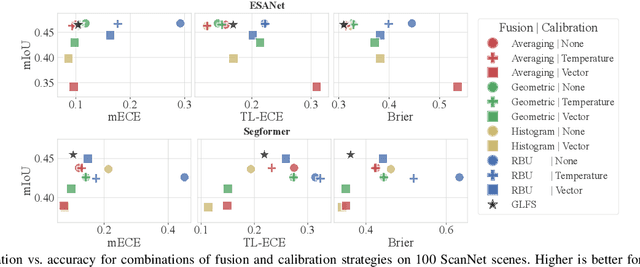
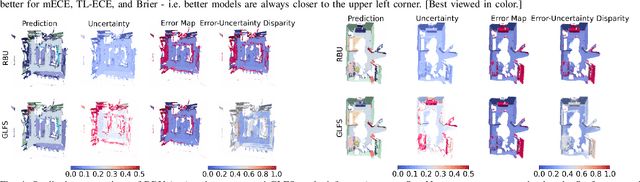
Semantic 3D mapping, the process of fusing depth and image segmentation information between multiple views to build 3D maps annotated with object classes in real-time, is a recent topic of interest. This paper highlights the fusion overconfidence problem, in which conventional mapping methods assign high confidence to the entire map even when they are incorrect, leading to miscalibrated outputs. Several methods to improve uncertainty calibration at different stages in the fusion pipeline are presented and compared on the ScanNet dataset. We show that the most widely used Bayesian fusion strategy is among the worst calibrated, and propose a learned pipeline that combines fusion and calibration, GLFS, which achieves simultaneously higher accuracy and 3D map calibration while retaining real-time capability. We further illustrate the importance of map calibration on a downstream task by showing that incorporating proper semantic fusion on a modular ObjectNav agent improves its success rates. Our code will be provided on Github for reproducibility upon acceptance.
GSAP-NER: A Novel Task, Corpus, and Baseline for Scholarly Entity Extraction Focused on Machine Learning Models and Datasets
Nov 16, 2023Named Entity Recognition (NER) models play a crucial role in various NLP tasks, including information extraction (IE) and text understanding. In academic writing, references to machine learning models and datasets are fundamental components of various computer science publications and necessitate accurate models for identification. Despite the advancements in NER, existing ground truth datasets do not treat fine-grained types like ML model and model architecture as separate entity types, and consequently, baseline models cannot recognize them as such. In this paper, we release a corpus of 100 manually annotated full-text scientific publications and a first baseline model for 10 entity types centered around ML models and datasets. In order to provide a nuanced understanding of how ML models and datasets are mentioned and utilized, our dataset also contains annotations for informal mentions like "our BERT-based model" or "an image CNN". You can find the ground truth dataset and code to replicate model training at https://data.gesis.org/gsap/gsap-ner.
Which Modality should I use -- Text, Motif, or Image? : Understanding Graphs with Large Language Models
Nov 16, 2023Large language models (LLMs) are revolutionizing various fields by leveraging large text corpora for context-aware intelligence. Due to the context size, however, encoding an entire graph with LLMs is fundamentally limited. This paper explores how to better integrate graph data with LLMs and presents a novel approach using various encoding modalities (e.g., text, image, and motif) and approximation of global connectivity of a graph using different prompting methods to enhance LLMs' effectiveness in handling complex graph structures. The study also introduces GraphTMI, a new benchmark for evaluating LLMs in graph structure analysis, focusing on factors such as homophily, motif presence, and graph difficulty. Key findings reveal that image modality, supported by advanced vision-language models like GPT-4V, is more effective than text in managing token limits while retaining critical information. The research also examines the influence of different factors on each encoding modality's performance. This study highlights the current limitations and charts future directions for LLMs in graph understanding and reasoning tasks.