 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Open-Vocabulary Camouflaged Object Segmentation
Nov 19, 2023

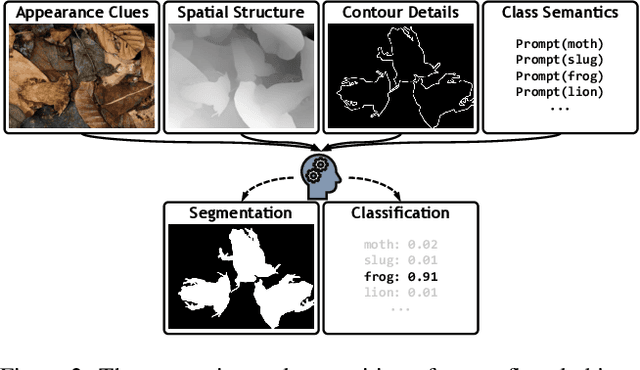
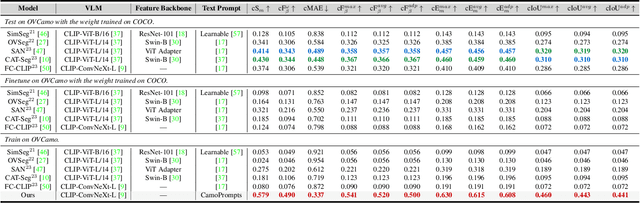

Recently, the emergence of the large-scale vision-language model (VLM), such as CLIP, has opened the way towards open-world object perception. Many works has explored the utilization of pre-trained VLM for the challenging open-vocabulary dense prediction task that requires perceive diverse objects with novel classes at inference time. Existing methods construct experiments based on the public datasets of related tasks, which are not tailored for open vocabulary and rarely involves imperceptible objects camouflaged in complex scenes due to data collection bias and annotation costs. To fill in the gaps, we introduce a new task, open-vocabulary camouflaged object segmentation (OVCOS) and construct a large-scale complex scene dataset (\textbf{OVCamo}) which containing 11,483 hand-selected images with fine annotations and corresponding object classes. Further, we build a strong single-stage open-vocabulary \underline{c}amouflaged \underline{o}bject \underline{s}egmentation transform\underline{er} baseline \textbf{OVCoser} attached to the parameter-fixed CLIP with iterative semantic guidance and structure enhancement. By integrating the guidance of class semantic knowledge and the supplement of visual structure cues from the edge and depth information, the proposed method can efficiently capture camouflaged objects. Moreover, this effective framework also surpasses previous state-of-the-arts of open-vocabulary semantic image segmentation by a large margin on our OVCamo dataset. With the proposed dataset and baseline, we hope that this new task with more practical value can further expand the research on open-vocabulary dense prediction tasks.
Robust Network Slicing: Multi-Agent Policies, Adversarial Attacks, and Defensive Strategies
Nov 19, 2023In this paper, we present a multi-agent deep reinforcement learning (deep RL) framework for network slicing in a dynamic environment with multiple base stations and multiple users. In particular, we propose a novel deep RL framework with multiple actors and centralized critic (MACC) in which actors are implemented as pointer networks to fit the varying dimension of input. We evaluate the performance of the proposed deep RL algorithm via simulations to demonstrate its effectiveness. Subsequently, we develop a deep RL based jammer with limited prior information and limited power budget. The goal of the jammer is to minimize the transmission rates achieved with network slicing and thus degrade the network slicing agents' performance. We design a jammer with both listening and jamming phases and address jamming location optimization as well as jamming channel optimization via deep RL. We evaluate the jammer at the optimized location, generating interference attacks in the optimized set of channels by switching between the jamming phase and listening phase. We show that the proposed jammer can significantly reduce the victims' performance without direct feedback or prior knowledge on the network slicing policies. Finally, we devise a Nash-equilibrium-supervised policy ensemble mixed strategy profile for network slicing (as a defensive measure) and jamming. We evaluate the performance of the proposed policy ensemble algorithm by applying on the network slicing agents and the jammer agent in simulations to show its effectiveness.
RecExplainer: Aligning Large Language Models for Recommendation Model Interpretability
Nov 18, 2023
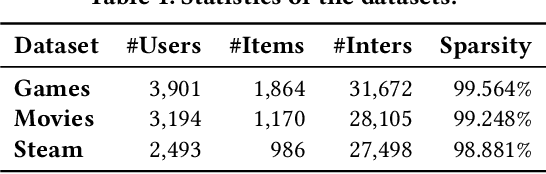

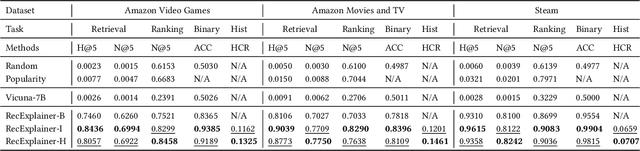
Recommender systems are widely used in various online services, with embedding-based models being particularly popular due to their expressiveness in representing complex signals. However, these models often lack interpretability, making them less reliable and transparent for both users and developers. With the emergence of large language models (LLMs), we find that their capabilities in language expression, knowledge-aware reasoning, and instruction following are exceptionally powerful. Based on this, we propose a new model interpretation approach for recommender systems, by using LLMs as surrogate models and learn to mimic and comprehend target recommender models. Specifically, we introduce three alignment methods: behavior alignment, intention alignment, and hybrid alignment. Behavior alignment operates in the language space, representing user preferences and item information as text to learn the recommendation model's behavior; intention alignment works in the latent space of the recommendation model, using user and item representations to understand the model's behavior; hybrid alignment combines both language and latent spaces for alignment training. To demonstrate the effectiveness of our methods, we conduct evaluation from two perspectives: alignment effect, and explanation generation ability on three public datasets. Experimental results indicate that our approach effectively enables LLMs to comprehend the patterns of recommendation models and generate highly credible recommendation explanations.
SBTRec- A Transformer Framework for Personalized Tour Recommendation Problem with Sentiment Analysis
Nov 18, 2023
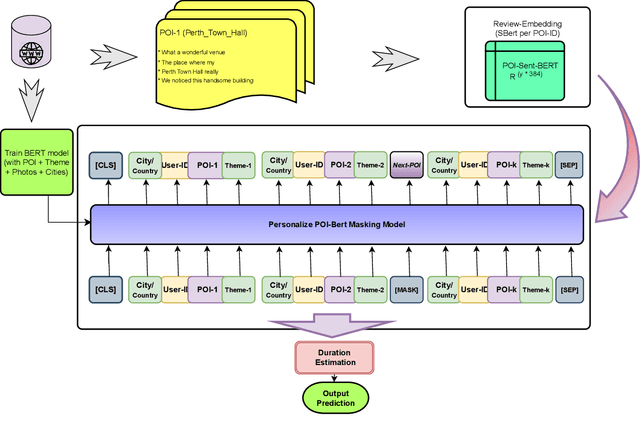
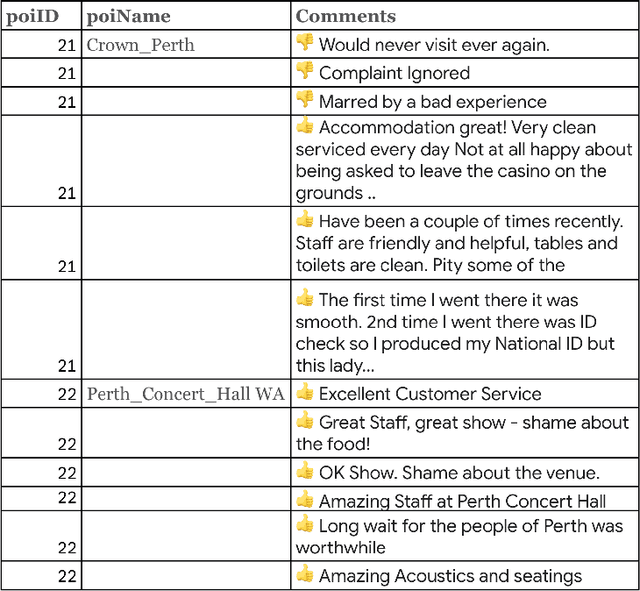
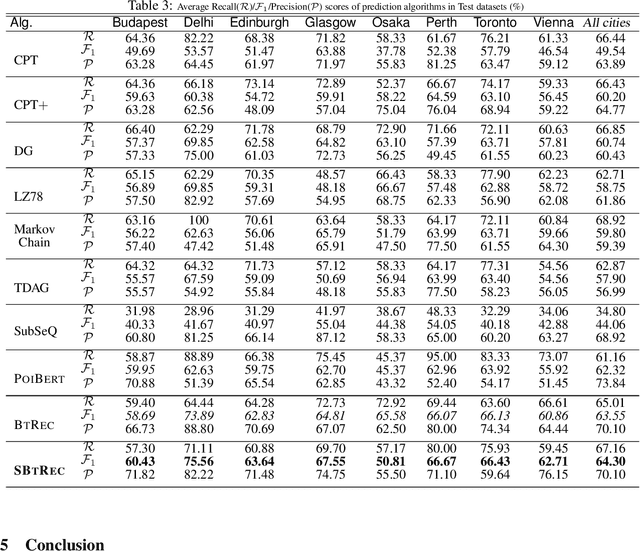
When traveling to an unfamiliar city for holidays, tourists often rely on guidebooks, travel websites, or recommendation systems to plan their daily itineraries and explore popular points of interest (POIs). However, these approaches may lack optimization in terms of time feasibility, localities, and user preferences. In this paper, we propose the SBTRec algorithm: a BERT-based Trajectory Recommendation with sentiment analysis, for recommending personalized sequences of POIs as itineraries. The key contributions of this work include analyzing users' check-ins and uploaded photos to understand the relationship between POI visits and distance. We introduce SBTRec, which encompasses sentiment analysis to improve recommendation accuracy by understanding users' preferences and satisfaction levels from reviews and comments about different POIs. Our proposed algorithms are evaluated against other sequence prediction methods using datasets from 8 cities. The results demonstrate that SBTRec achieves an average F1 score of 61.45%, outperforming baseline algorithms. The paper further discusses the flexibility of the SBTRec algorithm, its ability to adapt to different scenarios and cities without modification, and its potential for extension by incorporating additional information for more reliable predictions. Overall, SBTRec provides personalized and relevant POI recommendations, enhancing tourists' overall trip experiences. Future work includes fine-tuning personalized embeddings for users, with evaluation of users' comments on POIs,~to further enhance prediction accuracy.
Generating Medical Prescriptions with Conditional Transformer
Nov 18, 2023Access to real-world medication prescriptions is essential for medical research and healthcare quality improvement. However, access to real medication prescriptions is often limited due to the sensitive nature of the information expressed. Additionally, manually labelling these instructions for training and fine-tuning Natural Language Processing (NLP) models can be tedious and expensive. We introduce a novel task-specific model architecture, Label-To-Text-Transformer (\textbf{LT3}), tailored to generate synthetic medication prescriptions based on provided labels, such as a vocabulary list of medications and their attributes. LT3 is trained on a set of around 2K lines of medication prescriptions extracted from the MIMIC-III database, allowing the model to produce valuable synthetic medication prescriptions. We evaluate LT3's performance by contrasting it with a state-of-the-art Pre-trained Language Model (PLM), T5, analysing the quality and diversity of generated texts. We deploy the generated synthetic data to train the SpacyNER model for the Named Entity Recognition (NER) task over the n2c2-2018 dataset. The experiments show that the model trained on synthetic data can achieve a 96-98\% F1 score at Label Recognition on Drug, Frequency, Route, Strength, and Form. LT3 codes and data will be shared at \url{https://github.com/HECTA-UoM/Label-To-Text-Transformer}
CRYPTO-MINE: Cryptanalysis via Mutual Information Neural Estimation
Sep 14, 2023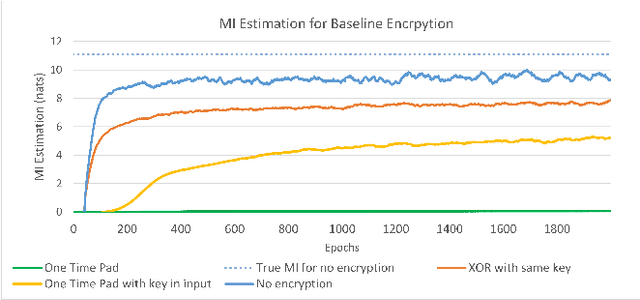
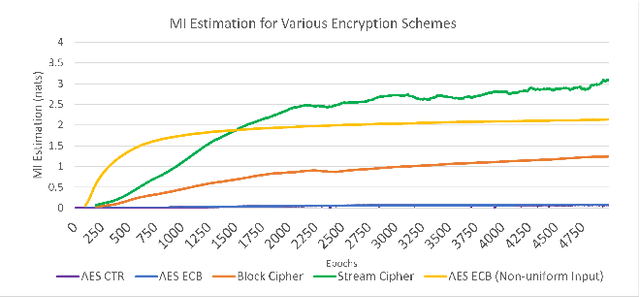
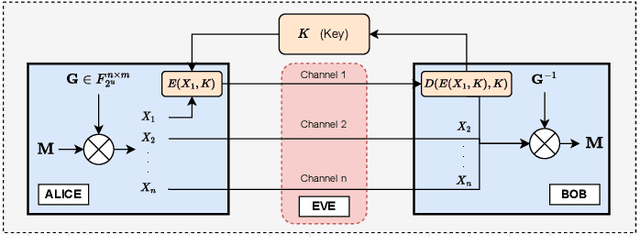
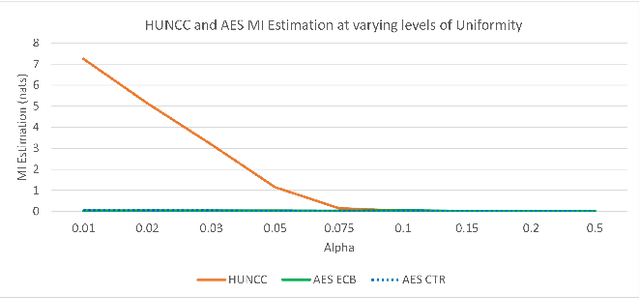
The use of Mutual Information (MI) as a measure to evaluate the efficiency of cryptosystems has an extensive history. However, estimating MI between unknown random variables in a high-dimensional space is challenging. Recent advances in machine learning have enabled progress in estimating MI using neural networks. This work presents a novel application of MI estimation in the field of cryptography. We propose applying this methodology directly to estimate the MI between plaintext and ciphertext in a chosen plaintext attack. The leaked information, if any, from the encryption could potentially be exploited by adversaries to compromise the computational security of the cryptosystem. We evaluate the efficiency of our approach by empirically analyzing multiple encryption schemes and baseline approaches. Furthermore, we extend the analysis to novel network coding-based cryptosystems that provide individual secrecy and study the relationship between information leakage and input distribution.
Solving ARC visual analogies with neural embeddings and vector arithmetic: A generalized method
Nov 14, 2023Analogical reasoning derives information from known relations and generalizes this information to similar yet unfamiliar situations. One of the first generalized ways in which deep learning models were able to solve verbal analogies was through vector arithmetic of word embeddings, essentially relating words that were mapped to a vector space (e.g., king - man + woman = __?). In comparison, most attempts to solve visual analogies are still predominantly task-specific and less generalizable. This project focuses on visual analogical reasoning and applies the initial generalized mechanism used to solve verbal analogies to the visual realm. Taking the Abstraction and Reasoning Corpus (ARC) as an example to investigate visual analogy solving, we use a variational autoencoder (VAE) to transform ARC items into low-dimensional latent vectors, analogous to the word embeddings used in the verbal approaches. Through simple vector arithmetic, underlying rules of ARC items are discovered and used to solve them. Results indicate that the approach works well on simple items with fewer dimensions (i.e., few colors used, uniform shapes), similar input-to-output examples, and high reconstruction accuracy on the VAE. Predictions on more complex items showed stronger deviations from expected outputs, although, predictions still often approximated parts of the item's rule set. Error patterns indicated that the model works as intended. On the official ARC paradigm, the model achieved a score of 2% (cf. current world record is 21%) and on ConceptARC it scored 8.8%. Although the methodology proposed involves basic dimensionality reduction techniques and standard vector arithmetic, this approach demonstrates promising outcomes on ARC and can easily be generalized to other abstract visual reasoning tasks.
ChoralSynth: Synthetic Dataset of Choral Singing
Nov 14, 2023Choral singing, a widely practiced form of ensemble singing, lacks comprehensive datasets in the realm of Music Information Retrieval (MIR) research, due to challenges arising from the requirement to curate multitrack recordings. To address this, we devised a novel methodology, leveraging state-of-the-art synthesizers to create and curate quality renditions. The scores were sourced from Choral Public Domain Library(CPDL). This work is done in collaboration with a diverse team of musicians, software engineers and researchers. The resulting dataset, complete with its associated metadata, and methodology is released as part of this work, opening up new avenues for exploration and advancement in the field of singing voice research.
Comparative Multi-View Language Grounding
Nov 14, 2023In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.
Non-Parametric Memory Guidance for Multi-Document Summarization
Nov 14, 2023Multi-document summarization (MDS) is a difficult task in Natural Language Processing, aiming to summarize information from several documents. However, the source documents are often insufficient to obtain a qualitative summary. We propose a retriever-guided model combined with non-parametric memory for summary generation. This model retrieves relevant candidates from a database and then generates the summary considering the candidates with a copy mechanism and the source documents. The retriever is implemented with Approximate Nearest Neighbor Search (ANN) to search large databases. Our method is evaluated on the MultiXScience dataset which includes scientific articles. Finally, we discuss our results and possible directions for future work.