 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FSMR: A Feature Swapping Multi-modal Reasoning Approach with Joint Textual and Visual Clues
Mar 29, 2024

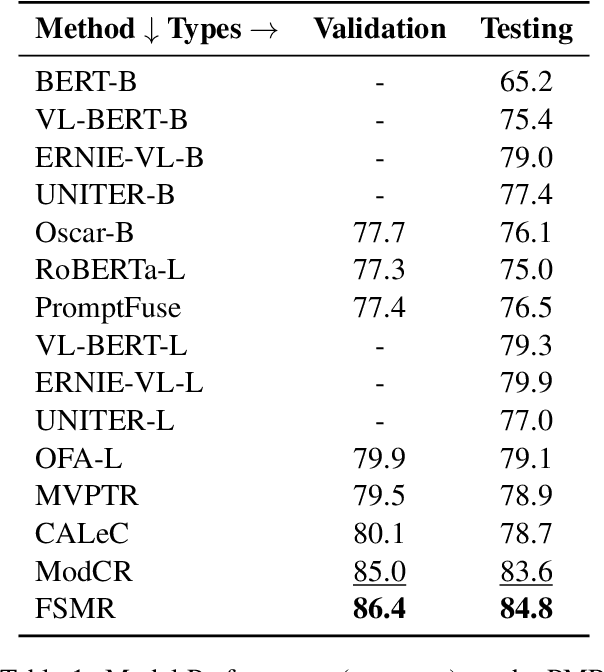
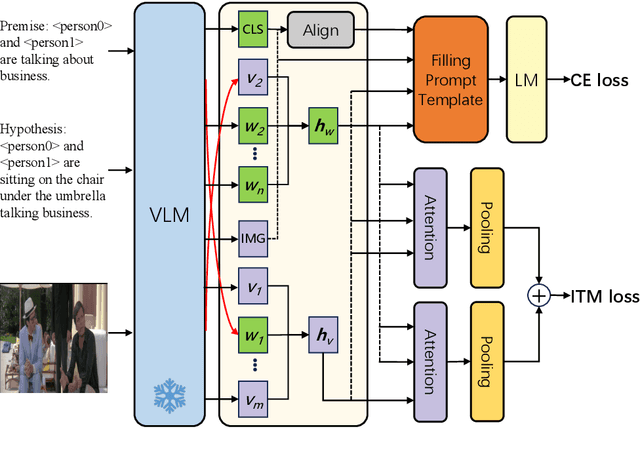
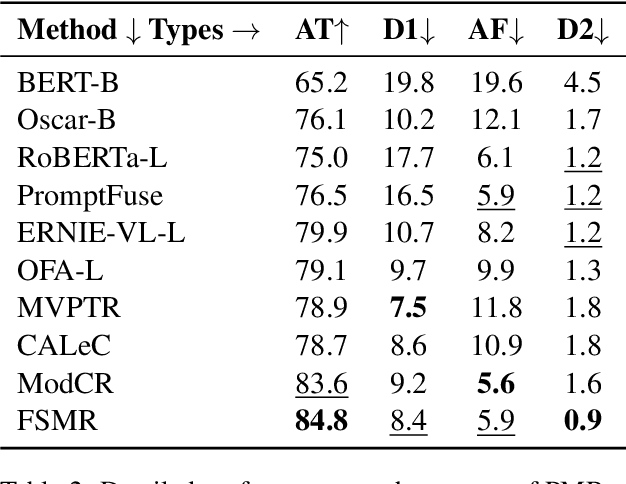
Multi-modal reasoning plays a vital role in bridging the gap between textual and visual information, enabling a deeper understanding of the context. This paper presents the Feature Swapping Multi-modal Reasoning (FSMR) model, designed to enhance multi-modal reasoning through feature swapping. FSMR leverages a pre-trained visual-language model as an encoder, accommodating both text and image inputs for effective feature representation from both modalities. It introduces a unique feature swapping module, enabling the exchange of features between identified objects in images and corresponding vocabulary words in text, thereby enhancing the model's comprehension of the interplay between images and text. To further bolster its multi-modal alignment capabilities, FSMR incorporates a multi-modal cross-attention mechanism, facilitating the joint modeling of textual and visual information. During training, we employ image-text matching and cross-entropy losses to ensure semantic consistency between visual and language elements. Extensive experiments on the PMR dataset demonstrate FSMR's superiority over state-of-the-art baseline models across various performance metrics.
A Signature Based Approach Towards Global Channel Charting with Ultra Low Complexity
Mar 29, 2024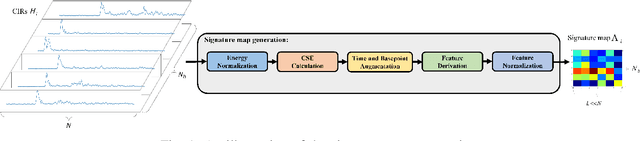
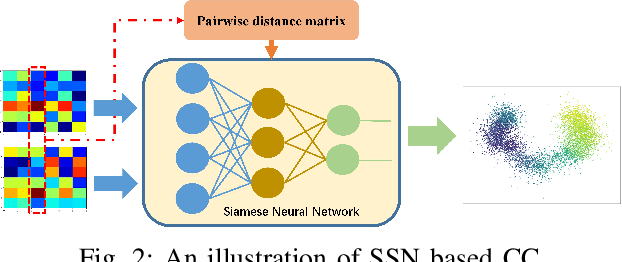
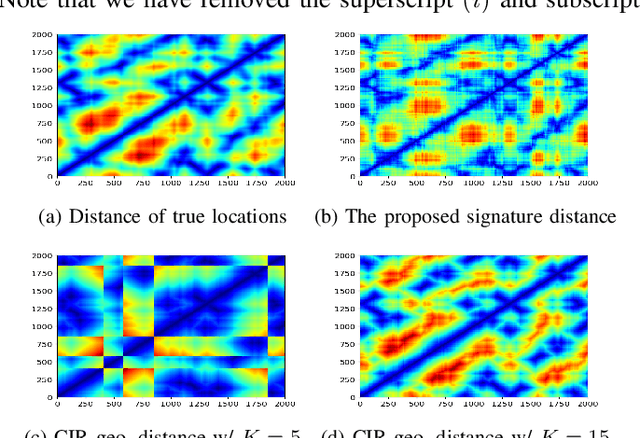
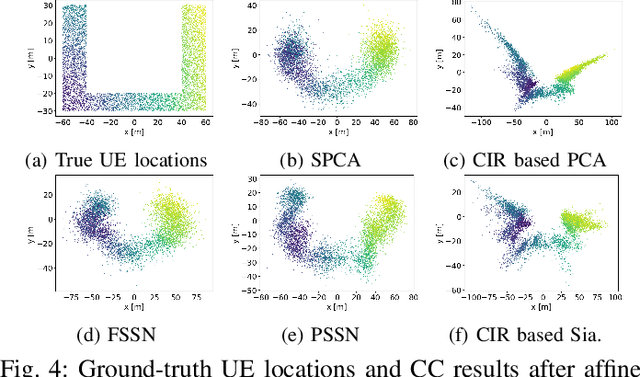
Channel charting, an unsupervised learning method that learns a low-dimensional representation from channel information to preserve geometrical property of physical space of user equipments (UEs), has drawn many attentions from both academic and industrial communities, because it can facilitate many downstream tasks, such as indoor localization, UE handover, beam management, and so on. However, many previous works mainly focus on charting that only preserves local geometry and use raw channel information to learn the chart, which do not consider the global geometry and are often computationally intensive and very time-consuming. Therefore, in this paper, a novel signature based approach for global channel charting with ultra low complexity is proposed. By using an iterated-integral based method called signature transform, a compact feature map and a novel distance metric are proposed, which enable channel charting with ultra low complexity and preserving both local and global geometry. We demonstrate the efficacy of our method using synthetic and open-source real-field datasets.
Inclusive Design Insights from a Preliminary Image-Based Conversational Search Systems Evaluation
Mar 29, 2024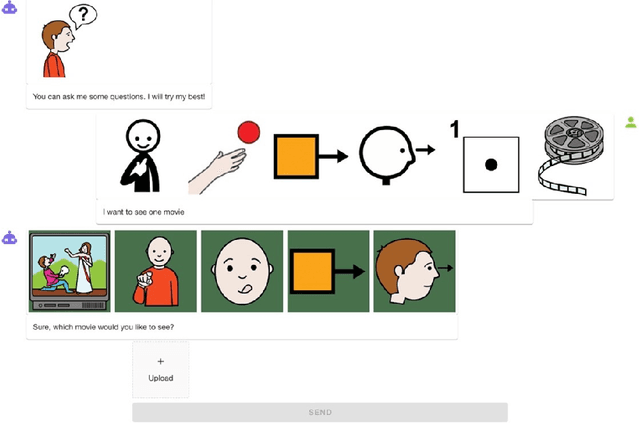
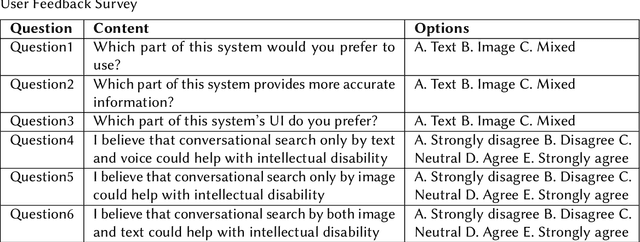
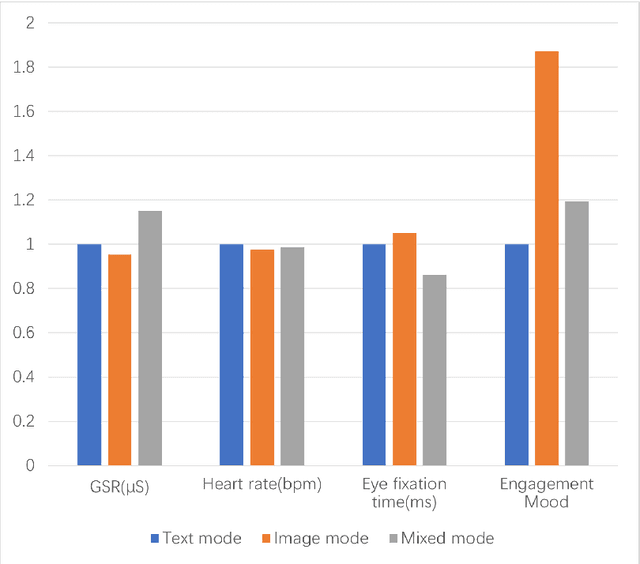
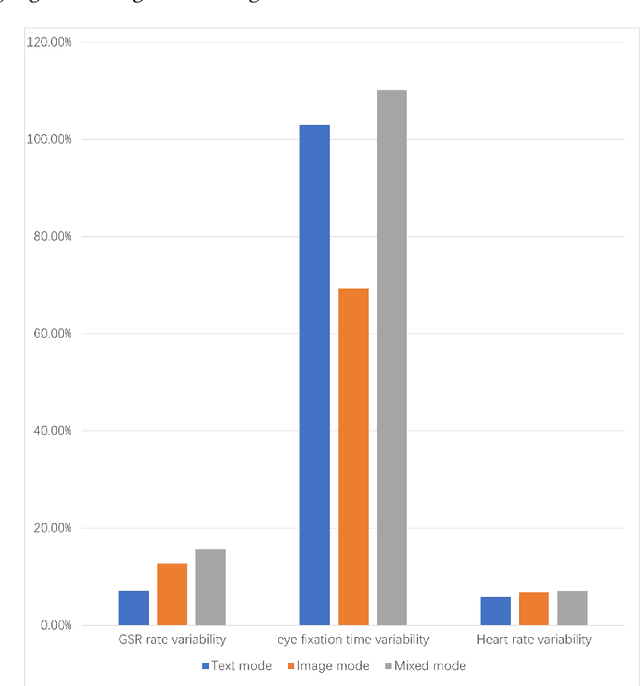
The digital realm has witnessed the rise of various search modalities, among which the Image-Based Conversational Search System stands out. This research delves into the design, implementation, and evaluation of this specific system, juxtaposing it against its text-based and mixed counterparts. A diverse participant cohort ensures a broad evaluation spectrum. Advanced tools facilitate emotion analysis, capturing user sentiments during interactions, while structured feedback sessions offer qualitative insights. Results indicate that while the text-based system minimizes user confusion, the image-based system presents challenges in direct information interpretation. However, the mixed system achieves the highest engagement, suggesting an optimal blend of visual and textual information. Notably, the potential of these systems, especially the image-based modality, to assist individuals with intellectual disabilities is highlighted. The study concludes that the Image-Based Conversational Search System, though challenging in some aspects, holds promise, especially when integrated into a mixed system, offering both clarity and engagement.
LLaMA-Excitor: General Instruction Tuning via Indirect Feature Interaction
Apr 01, 2024Existing methods to fine-tune LLMs, like Adapter, Prefix-tuning, and LoRA, which introduce extra modules or additional input sequences to inject new skills or knowledge, may compromise the innate abilities of LLMs. In this paper, we propose LLaMA-Excitor, a lightweight method that stimulates the LLMs' potential to better follow instructions by gradually paying more attention to worthwhile information. Specifically, the LLaMA-Excitor does not directly change the intermediate hidden state during the self-attention calculation of the transformer structure. We designed the Excitor block as a bypass module for the similarity score computation in LLMs' self-attention to reconstruct keys and change the importance of values by learnable prompts. LLaMA-Excitor ensures a self-adaptive allocation of additional attention to input instructions, thus effectively preserving LLMs' pre-trained knowledge when fine-tuning LLMs on low-quality instruction-following datasets. Furthermore, we unify the modeling of multi-modal tuning and language-only tuning, extending LLaMA-Excitor to a powerful visual instruction follower without the need for complex multi-modal alignment. Our proposed approach is evaluated in language-only and multi-modal tuning experimental scenarios. Notably, LLaMA-Excitor is the only method that maintains basic capabilities while achieving a significant improvement (+6%) on the MMLU benchmark. In the visual instruction tuning, we achieve a new state-of-the-art image captioning performance of 157.5 CIDEr on MSCOCO, and a comparable performance (88.39%) on ScienceQA to cutting-edge models with more parameters and extensive vision-language pertaining.
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Mar 31, 2024Personalized recommendation serves as a ubiquitous channel for users to discover information or items tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in pretrained multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications to recommender systems. Furthermore, we discuss open challenges and opportunities for future research in this domain. We hope that this survey, along with our tutorial materials, will inspire further research efforts to advance this evolving landscape.
Privacy-preserving Optics for Enhancing Protection in Face De-identification
Mar 31, 2024The modern surge in camera usage alongside widespread computer vision technology applications poses significant privacy and security concerns. Current artificial intelligence (AI) technologies aid in recognizing relevant events and assisting in daily tasks in homes, offices, hospitals, etc. The need to access or process personal information for these purposes raises privacy concerns. While software-level solutions like face de-identification provide a good privacy/utility trade-off, they present vulnerabilities to sniffing attacks. In this paper, we propose a hardware-level face de-identification method to solve this vulnerability. Specifically, our approach first learns an optical encoder along with a regression model to obtain a face heatmap while hiding the face identity from the source image. We also propose an anonymization framework that generates a new face using the privacy-preserving image, face heatmap, and a reference face image from a public dataset as input. We validate our approach with extensive simulations and hardware experiments.
Recover: A Neuro-Symbolic Framework for Failure Detection and Recovery
Mar 31, 2024Recognizing failures during task execution and implementing recovery procedures is challenging in robotics. Traditional approaches rely on the availability of extensive data or a tight set of constraints, while more recent approaches leverage large language models (LLMs) to verify task steps and replan accordingly. However, these methods often operate offline, necessitating scene resets and incurring in high costs. This paper introduces Recover, a neuro-symbolic framework for online failure identification and recovery. By integrating ontologies, logical rules, and LLM-based planners, Recover exploits symbolic information to enhance the ability of LLMs to generate recovery plans and also to decrease the associated costs. In order to demonstrate the capabilities of our method in a simulated kitchen environment, we introduce OntoThor, an ontology describing the AI2Thor simulator setting. Empirical evaluation shows that OntoThor's logical rules accurately detect all failures in the analyzed tasks, and that Recover considerably outperforms, for both failure detection and recovery, a baseline method reliant solely on LLMs.
M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models
Mar 31, 2024Medical image analysis is essential to clinical diagnosis and treatment, which is increasingly supported by multi-modal large language models (MLLMs). However, previous research has primarily focused on 2D medical images, leaving 3D images under-explored, despite their richer spatial information. This paper aims to advance 3D medical image analysis with MLLMs. To this end, we present a large-scale 3D multi-modal medical dataset, M3D-Data, comprising 120K image-text pairs and 662K instruction-response pairs specifically tailored for various 3D medical tasks, such as image-text retrieval, report generation, visual question answering, positioning, and segmentation. Additionally, we propose M3D-LaMed, a versatile multi-modal large language model for 3D medical image analysis. Furthermore, we introduce a new 3D multi-modal medical benchmark, M3D-Bench, which facilitates automatic evaluation across eight tasks. Through comprehensive evaluation, our method proves to be a robust model for 3D medical image analysis, outperforming existing solutions. All code, data, and models are publicly available at: https://github.com/BAAI-DCAI/M3D.
KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Mar 14, 2024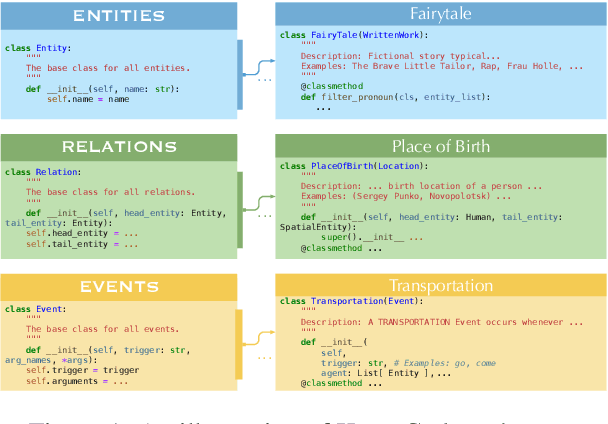
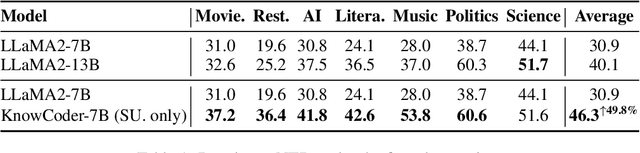
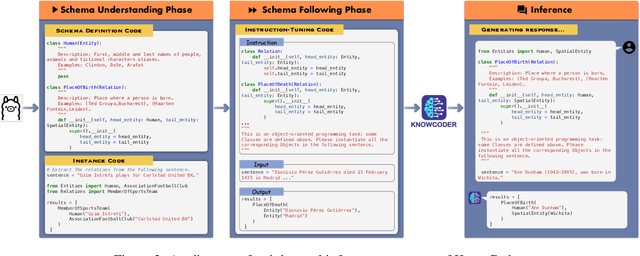
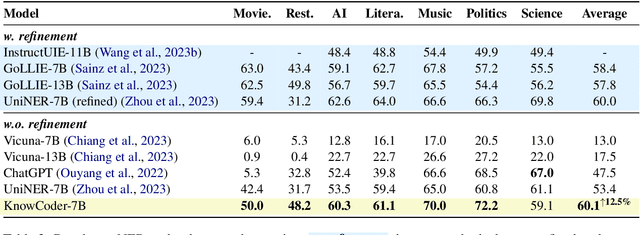
In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over $\textbf{30,000}$ types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a two-phase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around $1.5$B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $\textbf{49.8%}$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $\textbf{12.5%}$ and $\textbf{21.9%}$, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $\textbf{7.5%}$ under the supervised setting.
GeoAuxNet: Towards Universal 3D Representation Learning for Multi-sensor Point Clouds
Mar 28, 2024Point clouds captured by different sensors such as RGB-D cameras and LiDAR possess non-negligible domain gaps. Most existing methods design different network architectures and train separately on point clouds from various sensors. Typically, point-based methods achieve outstanding performances on even-distributed dense point clouds from RGB-D cameras, while voxel-based methods are more efficient for large-range sparse LiDAR point clouds. In this paper, we propose geometry-to-voxel auxiliary learning to enable voxel representations to access point-level geometric information, which supports better generalisation of the voxel-based backbone with additional interpretations of multi-sensor point clouds. Specifically, we construct hierarchical geometry pools generated by a voxel-guided dynamic point network, which efficiently provide auxiliary fine-grained geometric information adapted to different stages of voxel features. We conduct experiments on joint multi-sensor datasets to demonstrate the effectiveness of GeoAuxNet. Enjoying elaborate geometric information, our method outperforms other models collectively trained on multi-sensor datasets, and achieve competitive results with the-state-of-art experts on each single dataset.