 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FloodBrain: Flood Disaster Reporting by Web-based Retrieval Augmented Generation with an LLM
Nov 05, 2023



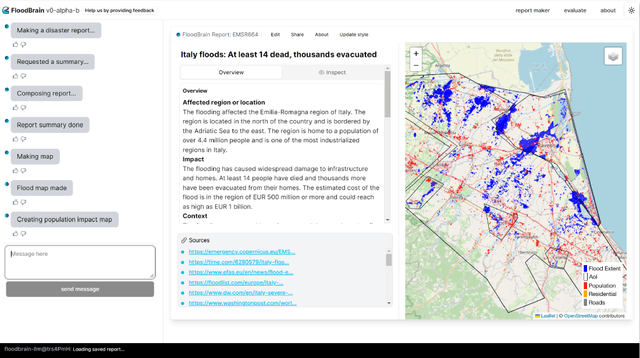
Fast disaster impact reporting is crucial in planning humanitarian assistance. Large Language Models (LLMs) are well known for their ability to write coherent text and fulfill a variety of tasks relevant to impact reporting, such as question answering or text summarization. However, LLMs are constrained by the knowledge within their training data and are prone to generating inaccurate, or "hallucinated", information. To address this, we introduce a sophisticated pipeline embodied in our tool FloodBrain (floodbrain.com), specialized in generating flood disaster impact reports by extracting and curating information from the web. Our pipeline assimilates information from web search results to produce detailed and accurate reports on flood events. We test different LLMs as backbones in our tool and compare their generated reports to human-written reports on different metrics. Similar to other studies, we find a notable correlation between the scores assigned by GPT-4 and the scores given by human evaluators when comparing our generated reports to human-authored ones. Additionally, we conduct an ablation study to test our single pipeline components and their relevancy for the final reports. With our tool, we aim to advance the use of LLMs for disaster impact reporting and reduce the time for coordination of humanitarian efforts in the wake of flood disasters.
SQLNet: Scale-Modulated Query and Localization Network for Few-Shot Class-Agnostic Counting
Nov 16, 2023The class-agnostic counting (CAC) task has recently been proposed to solve the problem of counting all objects of an arbitrary class with several exemplars given in the input image. To address this challenging task, existing leading methods all resort to density map regression, which renders them impractical for downstream tasks that require object locations and restricts their ability to well explore the scale information of exemplars for supervision. To address the limitations, we propose a novel localization-based CAC approach, termed Scale-modulated Query and Localization Network (SQLNet). It fully explores the scales of exemplars in both the query and localization stages and achieves effective counting by accurately locating each object and predicting its approximate size. Specifically, during the query stage, rich discriminative representations of the target class are acquired by the Hierarchical Exemplars Collaborative Enhancement (HECE) module from the few exemplars through multi-scale exemplar cooperation with equifrequent size prompt embedding. These representations are then fed into the Exemplars-Unified Query Correlation (EUQC) module to interact with the query features in a unified manner and produce the correlated query tensor. In the localization stage, the Scale-aware Multi-head Localization (SAML) module utilizes the query tensor to predict the confidence, location, and size of each potential object. Moreover, a scale-aware localization loss is introduced, which exploits flexible location associations and exemplar scales for supervision to optimize the model performance. Extensive experiments demonstrate that SQLNet outperforms state-of-the-art methods on popular CAC benchmarks, achieving excellent performance not only in counting accuracy but also in localization and bounding box generation. Our codes will be available at https://github.com/HCPLab-SYSU/SQLNet
Contrastive Deep Nonnegative Matrix Factorization for Community Detection
Nov 04, 2023Recently, nonnegative matrix factorization (NMF) has been widely adopted for community detection, because of its better interpretability. However, the existing NMF-based methods have the following three problems: 1) they directly transform the original network into community membership space, so it is difficult for them to capture the hierarchical information; 2) they often only pay attention to the topology of the network and ignore its node attributes; 3) it is hard for them to learn the global structure information necessary for community detection. Therefore, we propose a new community detection algorithm, named Contrastive Deep Nonnegative Matrix Factorization (CDNMF). Firstly, we deepen NMF to strengthen its capacity for information extraction. Subsequently, inspired by contrastive learning, our algorithm creatively constructs network topology and node attributes as two contrasting views. Furthermore, we utilize a debiased negative sampling layer and learn node similarity at the community level, thereby enhancing the suitability of our model for community detection. We conduct experiments on three public real graph datasets and the proposed model has achieved better results than state-of-the-art methods. Code available at https://github.com/6lyc/CDNMF.git.
Blending Reward Functions via Few Expert Demonstrations for Faithful and Accurate Knowledge-Grounded Dialogue Generation
Nov 02, 2023The development of trustworthy conversational information-seeking systems relies on dialogue models that can generate faithful and accurate responses based on relevant knowledge texts. However, two main challenges hinder this task. Firstly, language models may generate hallucinations due to data biases present in their pretraining corpus. Secondly, knowledge texts often contain redundant and irrelevant information that distracts the model's attention from the relevant text span. Previous works use additional data annotations on the knowledge texts to learn a knowledge identification module in order to bypass irrelevant information, but collecting such high-quality span annotations can be costly. In this work, we leverage reinforcement learning algorithms to overcome the above challenges by introducing a novel reward function. Our reward function combines an accuracy metric and a faithfulness metric to provide a balanced quality judgment of generated responses, which can be used as a cost-effective approximation to a human preference reward model when only a few preference annotations are available. Empirical experiments on two conversational information-seeking datasets demonstrate that our method can compete with other strong supervised learning baselines.
GazeForensics: DeepFake Detection via Gaze-guided Spatial Inconsistency Learning
Nov 13, 2023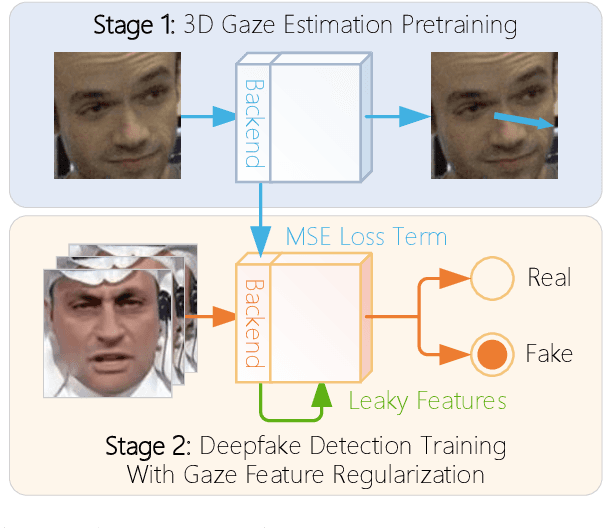
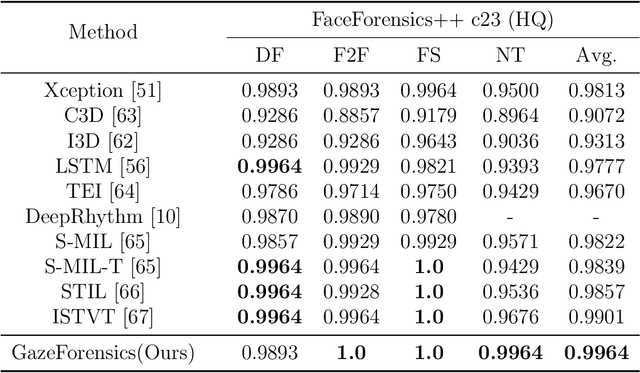
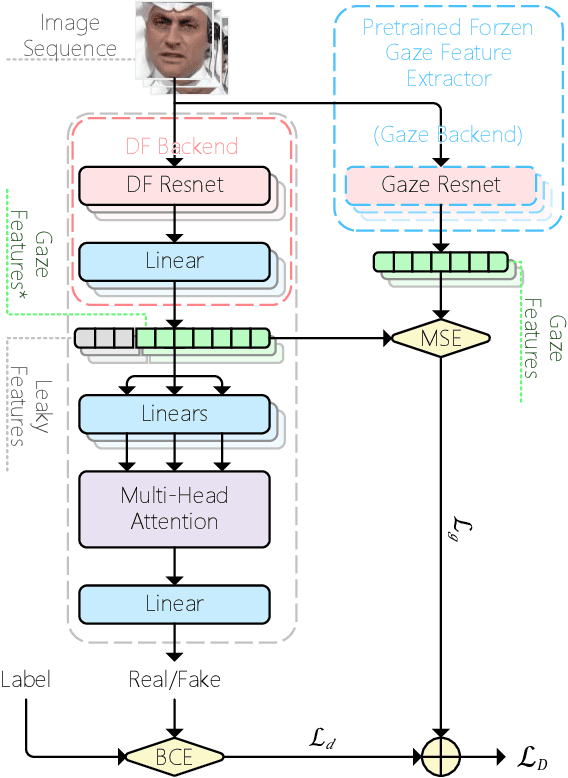
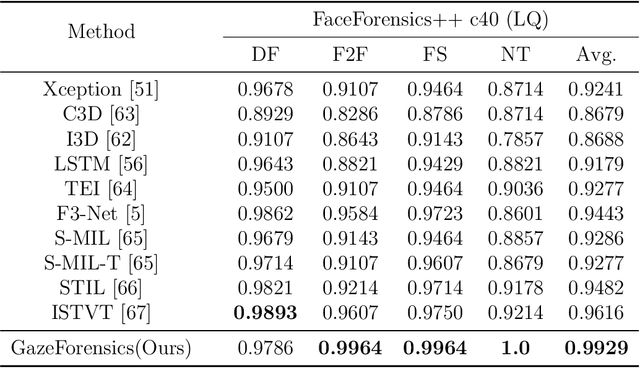
DeepFake detection is pivotal in personal privacy and public safety. With the iterative advancement of DeepFake techniques, high-quality forged videos and images are becoming increasingly deceptive. Prior research has seen numerous attempts by scholars to incorporate biometric features into the field of DeepFake detection. However, traditional biometric-based approaches tend to segregate biometric features from general ones and freeze the biometric feature extractor. These approaches resulted in the exclusion of valuable general features, potentially leading to a performance decline and, consequently, a failure to fully exploit the potential of biometric information in assisting DeepFake detection. Moreover, insufficient attention has been dedicated to scrutinizing gaze authenticity within the realm of DeepFake detection in recent years. In this paper, we introduce GazeForensics, an innovative DeepFake detection method that utilizes gaze representation obtained from a 3D gaze estimation model to regularize the corresponding representation within our DeepFake detection model, while concurrently integrating general features to further enhance the performance of our model. Experiment results reveal that our proposed GazeForensics outperforms the current state-of-the-art methods.
Joint Angle and Delay Cramér-Rao Bound Optimization for Integrated Sensing and Communications
Nov 13, 2023In this paper, we study a multi-input multi-output (MIMO) beamforming design in an integrated sensing and communication (ISAC) system, in which an ISAC base station (BS) is used to communicate with multiple downlink users and simultaneously the communication signals are reused for sensing multiple targets. Our interested sensing parameters are the angle and delay information of the targets, which can be used to locate these targets. Under this consideration, we first derive the Cram\'{e}r-Rao bound (CRB) for angle and delay estimation. Then, we optimize the transmit beamforming at the BS to minimize the CRB, subject to communication rate and power constraints. In particular, we obtain the optimal solution in closed-form in the case of single-target and single-user, and in the case of multi-target and multi-user scenario, the sparsity of the optimal solution is proven, leading to a reduction in computational complexity during optimization. The numerical results demonstrate that the optimized beamforming yields excellent positioning performance and effectively reduces the requirement for a large number of antennas at the BS.
Secure Wireless Communication via Movable-Antenna Array
Nov 13, 2023Movable antenna (MA) array is a novel technology recently developed where positions of transmit/receive antennas can be flexibly adjusted in the specified region to reconfigure the wireless channel and achieve a higher capacity. In this letter, we, for the first time, investigate the MA array-assisted physical-layer security where the confidential information is transmitted from a MA array-enabled Alice to a single-antenna Bob, in the presence of multiple single-antenna and colluding eavesdroppers. We aim to maximize the achievable secrecy rate by jointly designing the transmit beamforming and positions of all antennas at Alice subject to the transmit power budget and specified regions for positions of all transmit antennas. The resulting problem is highly non-convex, for which the projected gradient ascent (PGA) and the alternating optimization methods are utilized to obtain a high-quality suboptimal solution. Simulation results demonstrate that since the additional spatial degree of freedom (DoF) can be fully exploited, the MA array significantly enhances the secrecy rate compared to the conventional fixed-position antenna (FPA) array.
Histopathologic Cancer Detection
Nov 13, 2023Early diagnosis of the cancer cells is necessary for making an effective treatment plan and for the health and safety of a patient. Nowadays, doctors usually use a histological grade that pathologists determine by performing a semi-quantitative analysis of the histopathological and cytological features of hematoxylin-eosin (HE) stained histopathological images. This research contributes a potential classification model for cancer prognosis to efficiently utilize the valuable information underlying the HE-stained histopathological images. This work uses the PatchCamelyon benchmark datasets and trains them in a multi-layer perceptron and convolution model to observe the model's performance in terms of precision, Recall, F1 Score, Accuracy, and AUC Score. The evaluation result shows that the baseline convolution model outperforms the baseline MLP model. Also, this paper introduced ResNet50 and InceptionNet models with data augmentation, where ResNet50 is able to beat the state-of-the-art model. Furthermore, the majority vote and concatenation ensemble were evaluated and provided the future direction of using transfer learning and segmentation to understand the specific features.
STEM Rebalance: A Novel Approach for Tackling Imbalanced Datasets using SMOTE, Edited Nearest Neighbour, and Mixup
Nov 13, 2023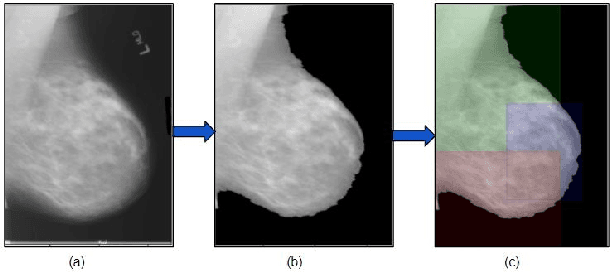
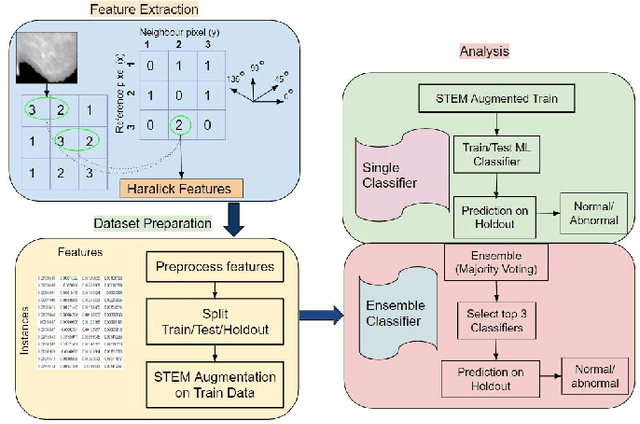
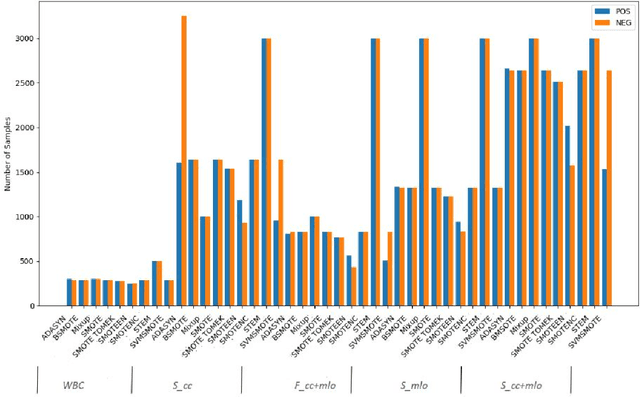
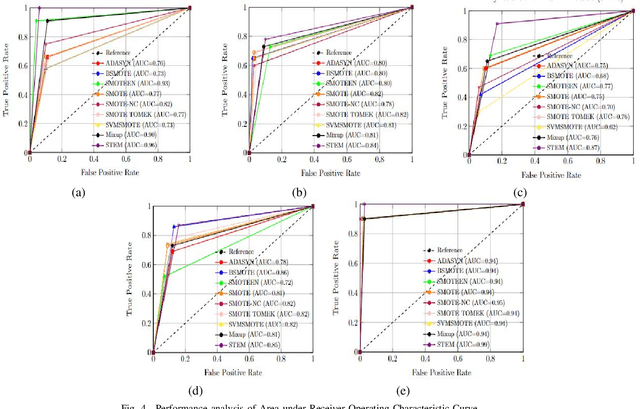
Imbalanced datasets in medical imaging are characterized by skewed class proportions and scarcity of abnormal cases. When trained using such data, models tend to assign higher probabilities to normal cases, leading to biased performance. Common oversampling techniques such as SMOTE rely on local information and can introduce marginalization issues. This paper investigates the potential of using Mixup augmentation that combines two training examples along with their corresponding labels to generate new data points as a generic vicinal distribution. To this end, we propose STEM, which combines SMOTE-ENN and Mixup at the instance level. This integration enables us to effectively leverage the entire distribution of minority classes, thereby mitigating both between-class and within-class imbalances. We focus on the breast cancer problem, where imbalanced datasets are prevalent. The results demonstrate the effectiveness of STEM, which achieves AUC values of 0.96 and 0.99 in the Digital Database for Screening Mammography and Wisconsin Breast Cancer (Diagnostics) datasets, respectively. Moreover, this method shows promising potential when applied with an ensemble of machine learning (ML) classifiers.
* 7 pages, 4 figures, International Conference on Intelligent Computer Communication and Processing
Think Before You Speak: Cultivating Communication Skills of Large Language Models via Inner Monologue
Nov 13, 2023The emergence of large language models (LLMs) further improves the capabilities of open-domain dialogue systems and can generate fluent, coherent, and diverse responses. However, LLMs still lack an important ability: communication skills, which makes them more like information seeking tools than anthropomorphic chatbots. To make LLMs more anthropomorphic and proactive during the conversation, we add five communication skills to the response generation process: topic transition, proactively asking questions, concept guidance, empathy, and summarising often. The addition of communication skills increases the interest of users in the conversation and attracts them to chat for longer. To enable LLMs better understand and use communication skills, we design and add the inner monologue to LLMs. The complete process is achieved through prompt engineering and in-context learning. To evaluate communication skills, we construct a benchmark named Cskills for evaluating various communication skills, which can also more comprehensively evaluate the dialogue generation ability of the model. Experimental results show that the proposed CSIM strategy improves the backbone models and outperforms the baselines in both automatic and human evaluations.