 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Graph Representation Learning with Adaptive Augmentation Contrastive
Nov 07, 2023
Temporal graph representation learning aims to generate low-dimensional dynamic node embeddings to capture temporal information as well as structural and property information. Current representation learning methods for temporal networks often focus on capturing fine-grained information, which may lead to the model capturing random noise instead of essential semantic information. While graph contrastive learning has shown promise in dealing with noise, it only applies to static graphs or snapshots and may not be suitable for handling time-dependent noise. To alleviate the above challenge, we propose a novel Temporal Graph representation learning with Adaptive augmentation Contrastive (TGAC) model. The adaptive augmentation on the temporal graph is made by combining prior knowledge with temporal information, and the contrastive objective function is constructed by defining the augmented inter-view contrast and intra-view contrast. To complement TGAC, we propose three adaptive augmentation strategies that modify topological features to reduce noise from the network. Our extensive experiments on various real networks demonstrate that the proposed model outperforms other temporal graph representation learning methods.
Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts
Nov 19, 2023Multi-Task Reinforcement Learning (MTRL) tackles the long-standing problem of endowing agents with skills that generalize across a variety of problems. To this end, sharing representations plays a fundamental role in capturing both unique and common characteristics of the tasks. Tasks may exhibit similarities in terms of skills, objects, or physical properties while leveraging their representations eases the achievement of a universal policy. Nevertheless, the pursuit of learning a shared set of diverse representations is still an open challenge. In this paper, we introduce a novel approach for representation learning in MTRL that encapsulates common structures among the tasks using orthogonal representations to promote diversity. Our method, named Mixture Of Orthogonal Experts (MOORE), leverages a Gram-Schmidt process to shape a shared subspace of representations generated by a mixture of experts. When task-specific information is provided, MOORE generates relevant representations from this shared subspace. We assess the effectiveness of our approach on two MTRL benchmarks, namely MiniGrid and MetaWorld, showing that MOORE surpasses related baselines and establishes a new state-of-the-art result on MetaWorld.
Bounds on Representation-Induced Confounding Bias for Treatment Effect Estimation
Nov 19, 2023State-of-the-art methods for conditional average treatment effect (CATE) estimation make widespread use of representation learning. Here, the idea is to reduce the variance of the low-sample CATE estimation by a (potentially constrained) low-dimensional representation. However, low-dimensional representations can lose information about the observed confounders and thus lead to bias, because of which the validity of representation learning for CATE estimation is typically violated. In this paper, we propose a new, representation-agnostic framework for estimating bounds on the representation-induced confounding bias that comes from dimensionality reduction (or other constraints on the representations) in CATE estimation. First, we establish theoretically under which conditions CATEs are non-identifiable given low-dimensional (constrained) representations. Second, as our remedy, we propose to perform partial identification of CATEs or, equivalently, aim at estimating of lower and upper bounds of the representation-induced confounding bias. We demonstrate the effectiveness of our bounds in a series of experiments. In sum, our framework is of direct relevance in practice where the validity of CATE estimation is of importance.
Link Streams as a Generalization of Graphs and Time Series
Nov 19, 2023A link stream is a set of possibly weighted triplets (t, u, v) modeling that u and v interacted at time t. Link streams offer an effective model for datasets containing both temporal and relational information, making their proper analysis crucial in many applications. They are commonly regarded as sequences of graphs or collections of time series. Yet, a recent seminal work demonstrated that link streams are more general objects of which graphs are only particular cases. It therefore started the construction of a dedicated formalism for link streams by extending graph theory. In this work, we contribute to the development of this formalism by showing that link streams also generalize time series. In particular, we show that a link stream corresponds to a time-series extended to a relational dimension, which opens the door to also extend the framework of signal processing to link streams. We therefore develop extensions of numerous signal concepts to link streams: from elementary ones like energy, correlation, and differentiation, to more advanced ones like Fourier transform and filters.
SCADI: Self-supervised Causal Disentanglement in Latent Variable Models
Nov 11, 2023Causal disentanglement has great potential for capturing complex situations. However, there is a lack of practical and efficient approaches. It is already known that most unsupervised disentangling methods are unable to produce identifiable results without additional information, often leading to randomly disentangled output. Therefore, most existing models for disentangling are weakly supervised, providing information about intrinsic factors, which incurs excessive costs. Therefore, we propose a novel model, SCADI(SElf-supervised CAusal DIsentanglement), that enables the model to discover semantic factors and learn their causal relationships without any supervision. This model combines a masked structural causal model (SCM) with a pseudo-label generator for causal disentanglement, aiming to provide a new direction for self-supervised causal disentanglement models.
A Model-Agnostic Graph Neural Network for Integrating Local and Global Information
Oct 02, 2023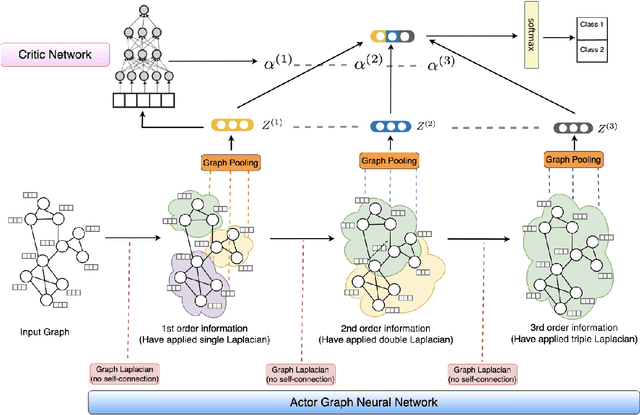
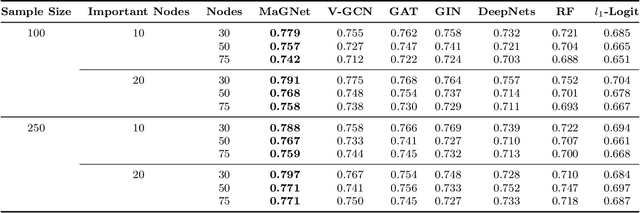
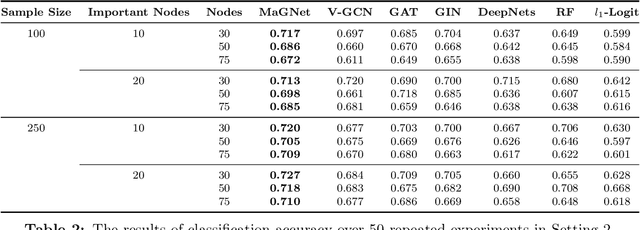
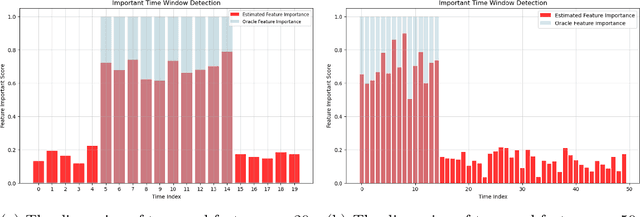
Graph Neural Networks (GNNs) have achieved promising performance in a variety of graph-focused tasks. Despite their success, existing GNNs suffer from two significant limitations: a lack of interpretability in results due to their black-box nature, and an inability to learn representations of varying orders. To tackle these issues, we propose a novel Model-agnostic Graph Neural Network (MaGNet) framework, which is able to sequentially integrate information of various orders, extract knowledge from high-order neighbors, and provide meaningful and interpretable results by identifying influential compact graph structures. In particular, MaGNet consists of two components: an estimation model for the latent representation of complex relationships under graph topology, and an interpretation model that identifies influential nodes, edges, and important node features. Theoretically, we establish the generalization error bound for MaGNet via empirical Rademacher complexity, and showcase its power to represent layer-wise neighborhood mixing. We conduct comprehensive numerical studies using simulated data to demonstrate the superior performance of MaGNet in comparison to several state-of-the-art alternatives. Furthermore, we apply MaGNet to a real-world case study aimed at extracting task-critical information from brain activity data, thereby highlighting its effectiveness in advancing scientific research.
Semantic Information Extraction for Text Data with Probability Graph
Sep 16, 2023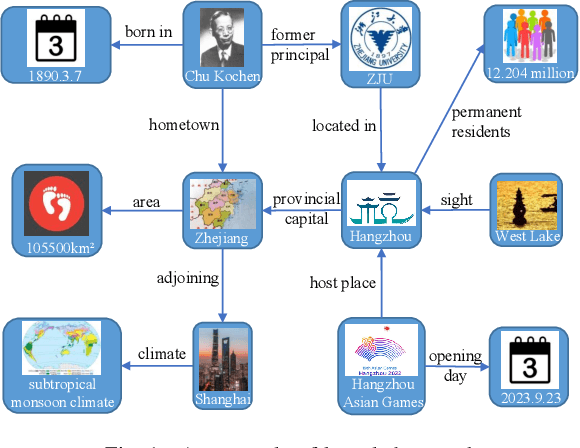
In this paper, the problem of semantic information extraction for resource constrained text data transmission is studied. In the considered model, a sequence of text data need to be transmitted within a communication resource-constrained network, which only allows limited data transmission. Thus, at the transmitter, the original text data is extracted with natural language processing techniques. Then, the extracted semantic information is captured in a knowledge graph. An additional probability dimension is introduced in this graph to capture the importance of each information. This semantic information extraction problem is posed as an optimization framework whose goal is to extract most important semantic information for transmission. To find an optimal solution for this problem, a Floyd's algorithm based solution coupled with an efficient sorting mechanism is proposed. Numerical results testify the effectiveness of the proposed algorithm with regards to two novel performance metrics including semantic uncertainty and semantic similarity.
GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Nov 20, 2023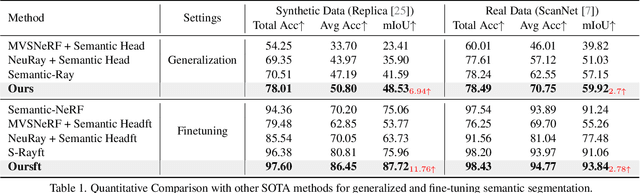
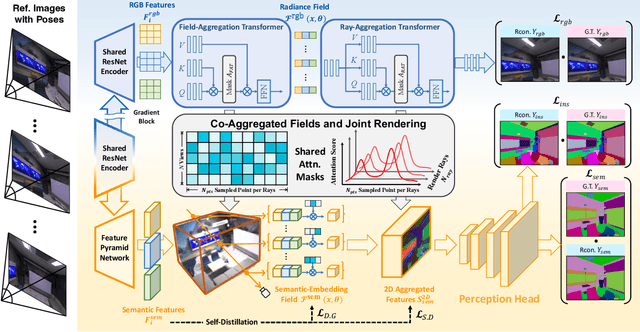
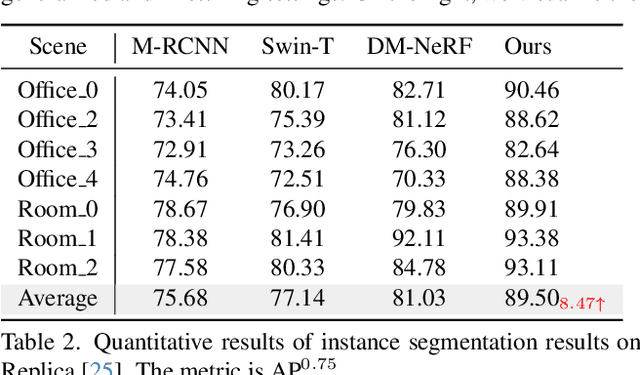
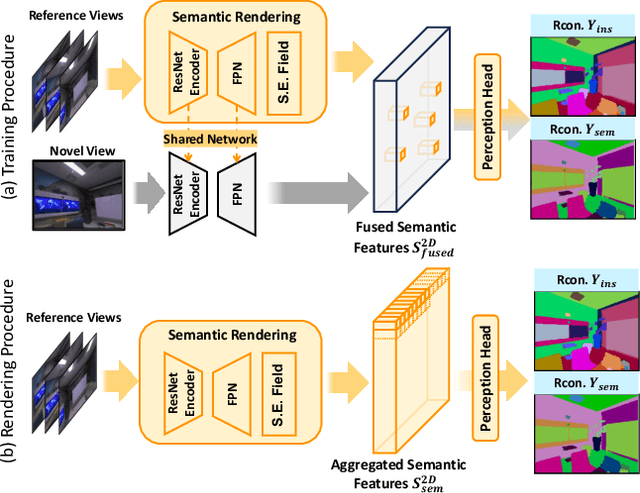
Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, \textit{i.e.}, the "label rendering" task, to build semantic NeRFs. However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object. To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception. To accomplish this goal, we introduce transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering of both fields. In addition, we propose two self-distillation mechanisms, i.e., the Semantic Distill Loss and the Depth-Guided Semantic Distill Loss, to enhance the discrimination and quality of the semantic field and the maintenance of geometric consistency. In evaluation, we conduct experimental comparisons under two perception tasks (\textit{i.e.} semantic and instance segmentation) using both synthetic and real-world datasets. Notably, our method outperforms SOTA approaches by 6.94\%, 11.76\%, and 8.47\% on generalized semantic segmentation, finetuning semantic segmentation, and instance segmentation, respectively.
Domain Transfer in Latent Space (DTLS) Wins on Image Super-Resolution -- a Non-Denoising Model
Nov 20, 2023Large scale image super-resolution is a challenging computer vision task, since vast information is missing in a highly degraded image, say for example forscale x16 super-resolution. Diffusion models are used successfully in recent years in extreme super-resolution applications, in which Gaussian noise is used as a means to form a latent photo-realistic space, and acts as a link between the space of latent vectors and the latent photo-realistic space. There are quite a few sophisticated mathematical derivations on mapping the statistics of Gaussian noises making Diffusion Models successful. In this paper we propose a simple approach which gets away from using Gaussian noise but adopts some basic structures of diffusion models for efficient image super-resolution. Essentially, we propose a DNN to perform domain transfer between neighbor domains, which can learn the differences in statistical properties to facilitate gradual interpolation with results of reasonable quality. Further quality improvement is achieved by conditioning the domain transfer with reference to the input LR image. Experimental results show that our method outperforms not only state-of-the-art large scale super resolution models, but also the current diffusion models for image super-resolution. The approach can readily be extended to other image-to-image tasks, such as image enlightening, inpainting, denoising, etc.
Conditional Modeling Based Automatic Video Summarization
Nov 20, 2023The aim of video summarization is to shorten videos automatically while retaining the key information necessary to convey the overall story. Video summarization methods mainly rely on visual factors, such as visual consecutiveness and diversity, which may not be sufficient to fully understand the content of the video. There are other non-visual factors, such as interestingness, representativeness, and storyline consistency that should also be considered for generating high-quality video summaries. Current methods do not adequately take into account these non-visual factors, resulting in suboptimal performance. In this work, a new approach to video summarization is proposed based on insights gained from how humans create ground truth video summaries. The method utilizes a conditional modeling perspective and introduces multiple meaningful random variables and joint distributions to characterize the key components of video summarization. Helper distributions are employed to improve the training of the model. A conditional attention module is designed to mitigate potential performance degradation in the presence of multi-modal input. The proposed video summarization method incorporates the above innovative design choices that aim to narrow the gap between human-generated and machine-generated video summaries. Extensive experiments show that the proposed approach outperforms existing methods and achieves state-of-the-art performance on commonly used video summarization datasets.