 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Seeing through the Mask: Multi-task Generative Mask Decoupling Face Recognition
Nov 20, 2023
The outbreak of COVID-19 pandemic make people wear masks more frequently than ever. Current general face recognition system suffers from serious performance degradation,when encountering occluded scenes. The potential reason is that face features are corrupted by occlusions on key facial regions. To tackle this problem, previous works either extract identity-related embeddings on feature level by additional mask prediction, or restore the occluded facial part by generative models. However, the former lacks visual results for model interpretation, while the latter suffers from artifacts which may affect downstream recognition. Therefore, this paper proposes a Multi-task gEnerative mask dEcoupling face Recognition (MEER) network to jointly handle these two tasks, which can learn occlusionirrelevant and identity-related representation while achieving unmasked face synthesis. We first present a novel mask decoupling module to disentangle mask and identity information, which makes the network obtain purer identity features from visible facial components. Then, an unmasked face is restored by a joint-training strategy, which will be further used to refine the recognition network with an id-preserving loss. Experiments on masked face recognition under realistic and synthetic occlusions benchmarks demonstrate that the MEER can outperform the state-ofthe-art methods.
Unveiling the Unseen Potential of Graph Learning through MLPs: Effective Graph Learners Using Propagation-Embracing MLPs
Nov 20, 2023Recent studies attempted to utilize multilayer perceptrons (MLPs) to solve semi-supervised node classification on graphs, by training a student MLP by knowledge distillation (KD) from a teacher graph neural network (GNN). While previous studies have focused mostly on training the student MLP by matching the output probability distributions between the teacher and student models during KD, it has not been systematically studied how to inject the structural information in an explicit and interpretable manner. Inspired by GNNs that separate feature transformation $T$ and propagation $\Pi$, we re-frame the KD process as enabling the student MLP to explicitly learn both $T$ and $\Pi$. Although this can be achieved by applying the inverse propagation $\Pi^{-1}$ before distillation from the teacher GNN, it still comes with a high computational cost from large matrix multiplications during training. To solve this problem, we propose Propagate & Distill (P&D), which propagates the output of the teacher GNN before KD and can be interpreted as an approximate process of the inverse propagation $\Pi^{-1}$. Through comprehensive evaluations using real-world benchmark datasets, we demonstrate the effectiveness of P&D by showing further performance boost of the student MLP.
Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Nov 21, 2023
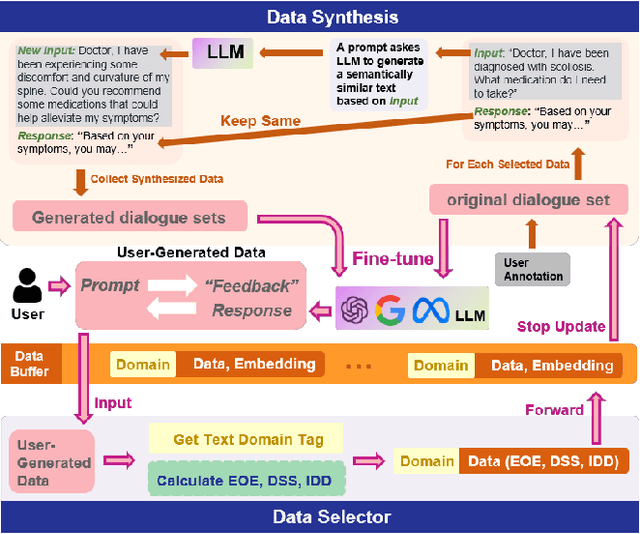
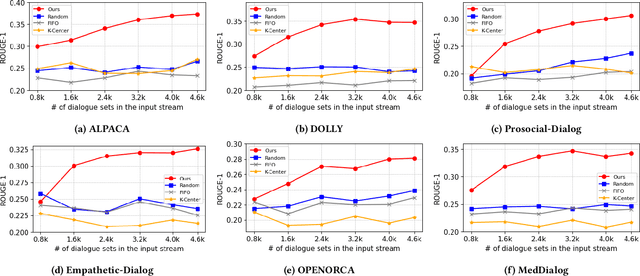
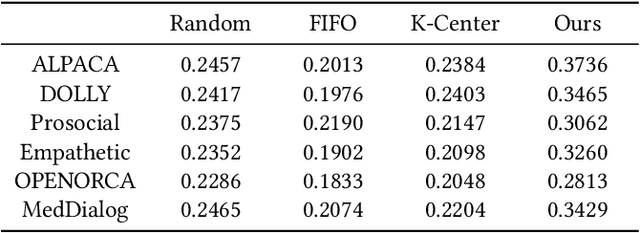
After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.
META4: Semantically-Aligned Generation of Metaphoric Gestures Using Self-Supervised Text and Speech Representation
Nov 21, 2023Image Schemas are repetitive cognitive patterns that influence the way we conceptualize and reason about various concepts present in speech. These patterns are deeply embedded within our cognitive processes and are reflected in our bodily expressions including gestures. Particularly, metaphoric gestures possess essential characteristics and semantic meanings that align with Image Schemas, to visually represent abstract concepts. The shape and form of gestures can convey abstract concepts, such as extending the forearm and hand or tracing a line with hand movements to visually represent the image schema of PATH. Previous behavior generation models have primarily focused on utilizing speech (acoustic features and text) to drive the generation model of virtual agents. They have not considered key semantic information as those carried by Image Schemas to effectively generate metaphoric gestures. To address this limitation, we introduce META4, a deep learning approach that generates metaphoric gestures from both speech and Image Schemas. Our approach has two primary goals: computing Image Schemas from input text to capture the underlying semantic and metaphorical meaning, and generating metaphoric gestures driven by speech and the computed image schemas. Our approach is the first method for generating speech driven metaphoric gestures while leveraging the potential of Image Schemas. We demonstrate the effectiveness of our approach and highlight the importance of both speech and image schemas in modeling metaphoric gestures.
Careful Selection and Thoughtful Discarding: Graph Explicit Pooling Utilizing Discarded Nodes
Nov 21, 2023Graph pooling has been increasingly recognized as crucial for Graph Neural Networks (GNNs) to facilitate hierarchical graph representation learning. Existing graph pooling methods commonly consist of two stages: selecting top-ranked nodes and discarding the remaining to construct coarsened graph representations. However, this paper highlights two key issues with these methods: 1) The process of selecting nodes to discard frequently employs additional Graph Convolutional Networks or Multilayer Perceptrons, lacking a thorough evaluation of each node's impact on the final graph representation and subsequent prediction tasks. 2) Current graph pooling methods tend to directly discard the noise segment (dropped) of the graph without accounting for the latent information contained within these elements. To address the first issue, we introduce a novel Graph Explicit Pooling (GrePool) method, which selects nodes by explicitly leveraging the relationships between the nodes and final representation vectors crucial for classification. The second issue is addressed using an extended version of GrePool (i.e., GrePool+), which applies a uniform loss on the discarded nodes. This addition is designed to augment the training process and improve classification accuracy. Furthermore, we conduct comprehensive experiments across 12 widely used datasets to validate our proposed method's effectiveness, including the Open Graph Benchmark datasets. Our experimental results uniformly demonstrate that GrePool outperforms 14 baseline methods for most datasets. Likewise, implementing GrePool+ enhances GrePool's performance without incurring additional computational costs.
Robust Hole-Detection in Triangular Meshes Irrespective of the Presence of Singular Vertices
Nov 21, 2023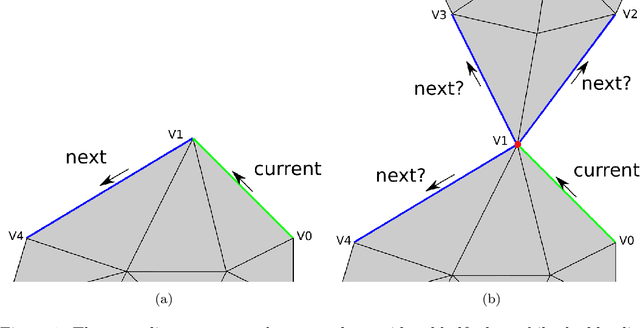

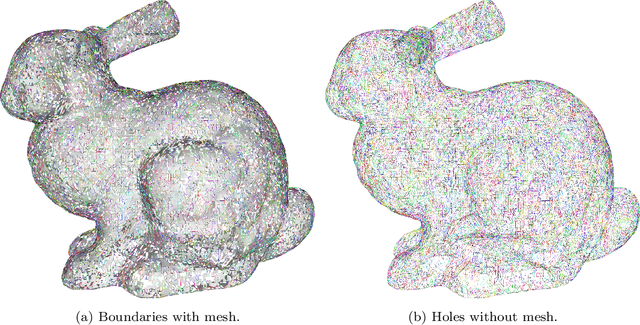
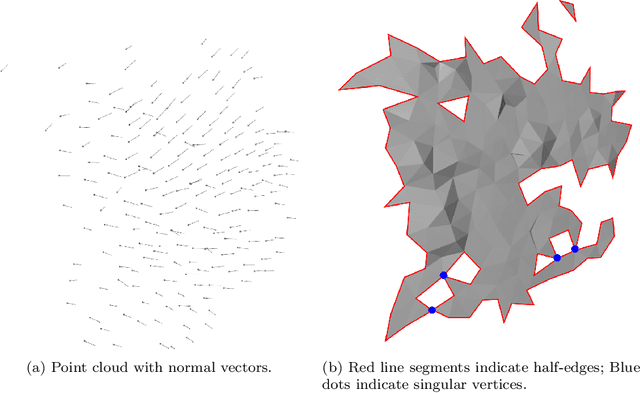
In this work, we present a boundary and hole detection approach that traverses all the boundaries of an edge-manifold triangular mesh, irrespectively of the presence of singular vertices, and subsequently determines and labels all holes of the mesh. The proposed automated hole-detection method is valuable to the computer-aided design (CAD) community as all half-edges within the mesh are utilized and for each half-edge the algorithm guarantees both the existence and the uniqueness of the boundary associated to it. As existing hole-detection approaches assume that singular vertices are absent or may require mesh modification, these methods are ill-equipped to detect boundaries/holes in real-world meshes that contain singular vertices. We demonstrate the method in an underwater autonomous robotic application, exploiting surface reconstruction methods based on point cloud data. In such a scenario the determined holes can be interpreted as information gaps, enabling timely corrective action during the data acquisition. However, the scope of our method is not confined to these two sectors alone; it is versatile enough to be applied on any edge-manifold triangle mesh. An evaluation of the method is performed on both synthetic and real-world data (including a triangle mesh from a point cloud obtained by a multibeam sonar). The source code of our reference implementation is available: https://github.com/Mauhing/hole-detection-on-triangle-mesh.
Efficient Temporally-Aware DeepFake Detection using H.264 Motion Vectors
Nov 17, 2023Video DeepFakes are fake media created with Deep Learning (DL) that manipulate a person's expression or identity. Most current DeepFake detection methods analyze each frame independently, ignoring inconsistencies and unnatural movements between frames. Some newer methods employ optical flow models to capture this temporal aspect, but they are computationally expensive. In contrast, we propose using the related but often ignored Motion Vectors (MVs) and Information Masks (IMs) from the H.264 video codec, to detect temporal inconsistencies in DeepFakes. Our experiments show that this approach is effective and has minimal computational costs, compared with per-frame RGB-only methods. This could lead to new, real-time temporally-aware DeepFake detection methods for video calls and streaming.
Gen-Z: Generative Zero-Shot Text Classification with Contextualized Label Descriptions
Nov 13, 2023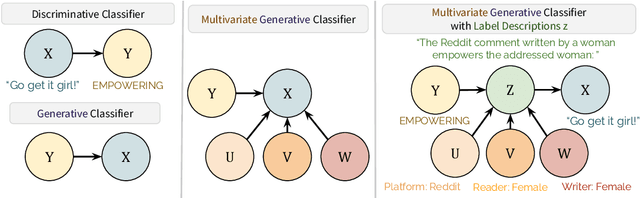
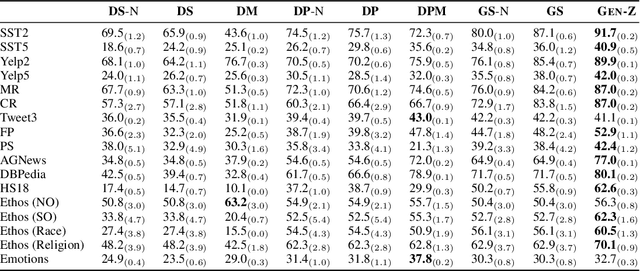
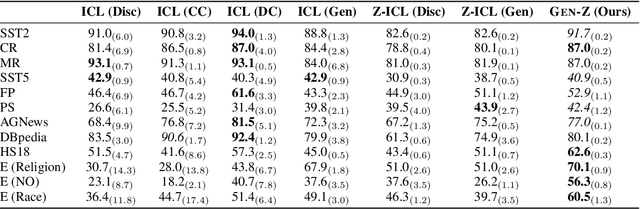
Language model (LM) prompting--a popular paradigm for solving NLP tasks--has been shown to be susceptible to miscalibration and brittleness to slight prompt variations, caused by its discriminative prompting approach, i.e., predicting the label given the input. To address these issues, we propose Gen-Z--a generative prompting framework for zero-shot text classification. GEN-Z is generative, as it measures the LM likelihood of input text, conditioned on natural language descriptions of labels. The framework is multivariate, as label descriptions allow us to seamlessly integrate additional contextual information about the labels to improve task performance. On various standard classification benchmarks, with six open-source LM families, we show that zero-shot classification with simple contextualization of the data source of the evaluation set consistently outperforms both zero-shot and few-shot baselines while improving robustness to prompt variations. Further, our approach enables personalizing classification in a zero-shot manner by incorporating author, subject, or reader information in the label descriptions.
ChartCheck: An Evidence-Based Fact-Checking Dataset over Real-World Chart Images
Nov 13, 2023Data visualizations are common in the real-world. We often use them in data sources such as scientific documents, news articles, textbooks, and social media to summarize key information in a visual form. Charts can also mislead its audience by communicating false information or biasing them towards a specific agenda. Verifying claims against charts is not a straightforward process. It requires analyzing both the text and visual components of the chart, considering characteristics such as colors, positions, and orientations. Moreover, to determine if a claim is supported by the chart content often requires different types of reasoning. To address this challenge, we introduce ChartCheck, a novel dataset for fact-checking against chart images. ChartCheck is the first large-scale dataset with 1.7k real-world charts and 10.5k human-written claims and explanations. We evaluated the dataset on state-of-the-art models and achieved an accuracy of 73.9 in the finetuned setting. Additionally, we identified chart characteristics and reasoning types that challenge the models.
Gendec: A Machine Learning-based Framework for Gender Detection from Japanese Names
Nov 18, 2023Every human has their own name, a fundamental aspect of their identity and cultural heritage. The name often conveys a wealth of information, including details about an individual's background, ethnicity, and, especially, their gender. By detecting gender through the analysis of names, researchers can unlock valuable insights into linguistic patterns and cultural norms, which can be applied to practical applications. Hence, this work presents a novel dataset for Japanese name gender detection comprising 64,139 full names in romaji, hiragana, and kanji forms, along with their biological genders. Moreover, we propose Gendec, a framework for gender detection from Japanese names that leverages diverse approaches, including traditional machine learning techniques or cutting-edge transfer learning models, to predict the gender associated with Japanese names accurately. Through a thorough investigation, the proposed framework is expected to be effective and serve potential applications in various domains.