 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Causal Discovery Under Local Privacy
Nov 15, 2023
Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
Chain of Thought with Explicit Evidence Reasoning for Few-shot Relation Extraction
Nov 15, 2023Few-shot relation extraction involves identifying the type of relationship between two specific entities within a text, using a limited number of annotated samples. A variety of solutions to this problem have emerged by applying meta-learning and neural graph techniques which typically necessitate a training process for adaptation. Recently, the strategy of in-context learning has been demonstrating notable results without the need of training. Few studies have already utilized in-context learning for zero-shot information extraction. Unfortunately, the evidence for inference is either not considered or implicitly modeled during the construction of chain-of-thought prompts. In this paper, we propose a novel approach for few-shot relation extraction using large language models, named CoT-ER, chain-of-thought with explicit evidence reasoning. In particular, CoT-ER first induces large language models to generate evidences using task-specific and concept-level knowledge. Then these evidences are explicitly incorporated into chain-of-thought prompting for relation extraction. Experimental results demonstrate that our CoT-ER approach (with 0% training data) achieves competitive performance compared to the fully-supervised (with 100% training data) state-of-the-art approach on the FewRel1.0 and FewRel2.0 datasets.
Enhancing data efficiency in reinforcement learning: a novel imagination mechanism based on mesh information propagation
Sep 27, 2023Reinforcement learning(RL) algorithms face the challenge of limited data efficiency, particularly when dealing with high-dimensional state spaces and large-scale problems. Most of RL methods often rely solely on state transition information within the same episode when updating the agent's Critic, which can lead to low data efficiency and sub-optimal training time consumption. Inspired by human-like analogical reasoning abilities, we introduce a novel mesh information propagation mechanism, termed the 'Imagination Mechanism (IM)', designed to significantly enhance the data efficiency of RL algorithms. Specifically, IM enables information generated by a single sample to be effectively broadcasted to different states across episodes, instead of simply transmitting in the same episode. This capability enhances the model's comprehension of state interdependencies and facilitates more efficient learning of limited sample information. To promote versatility, we extend the IM to function as a plug-and-play module that can be seamlessly and fluidly integrated into other widely adopted RL algorithms. Our experiments demonstrate that IM consistently boosts four mainstream SOTA RL algorithms, such as SAC, PPO, DDPG, and DQN, by a considerable margin, ultimately leading to superior performance than before across various tasks. For access to our code and data, please visit https://github.com/OuAzusaKou/imagination_mechanism
Time Series Synthesis Using the Matrix Profile for Anonymization
Nov 05, 2023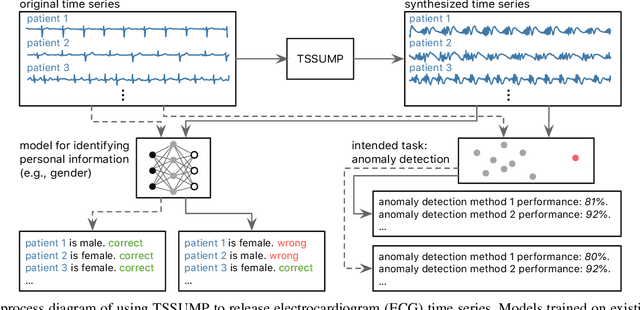
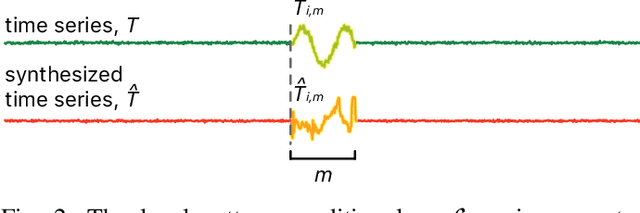
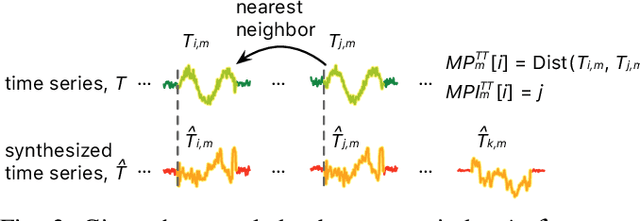
Publishing and sharing data is crucial for the data mining community, allowing collaboration and driving open innovation. However, many researchers cannot release their data due to privacy regulations or fear of leaking confidential business information. To alleviate such issues, we propose the Time Series Synthesis Using the Matrix Profile (TSSUMP) method, where synthesized time series can be released in lieu of the original data. The TSSUMP method synthesizes time series by preserving similarity join information (i.e., Matrix Profile) while reducing the correlation between the synthesized and the original time series. As a result, neither the values for the individual time steps nor the local patterns (or shapes) from the original data can be recovered, yet the resulting data can be used for downstream tasks that data analysts are interested in. We concentrate on similarity joins because they are one of the most widely applied time series data mining routines across different data mining tasks. We test our method on a case study of ECG and gender masking prediction. In this case study, the gender information is not only removed from the synthesized time series, but the synthesized time series also preserves enough information from the original time series. As a result, unmodified data mining tools can obtain near-identical performance on the synthesized time series as on the original time series.
Latent Space Inference For Spatial Transcriptomics
Nov 01, 2023In order to understand the complexities of cellular biology, researchers are interested in two important metrics: the genetic expression information of cells and their spatial coordinates within a tissue sample. However, state-of-the art methods, namely single-cell RNA sequencing and image based spatial transcriptomics can only recover a subset of this information, either full genetic expression with loss of spatial information, or spatial information with loss of resolution in sequencing data. In this project, we investigate a probabilistic machine learning method to obtain the full genetic expression information for tissues samples while also preserving their spatial coordinates. This is done through mapping both datasets to a joint latent space representation with the use of variational machine learning methods. From here, the full genetic and spatial information can be decoded and to give us greater insights on the understanding of cellular processes and pathways.
Content Reduction, Surprisal and Information Density Estimation for Long Documents
Sep 12, 2023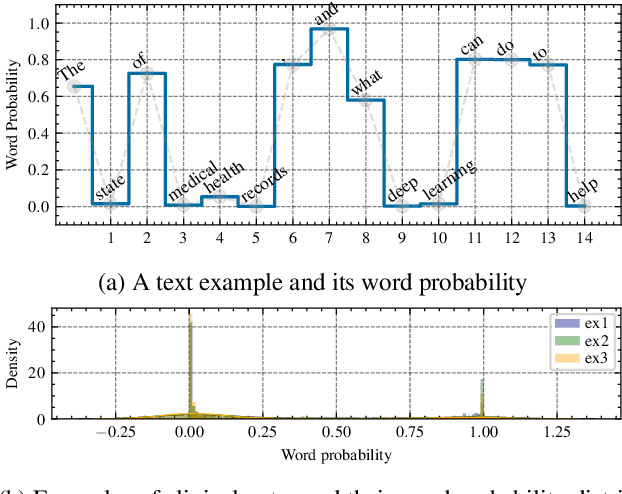
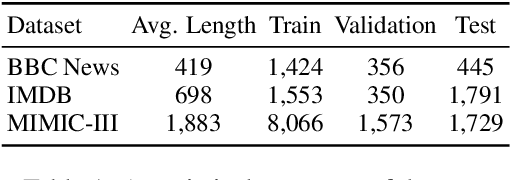
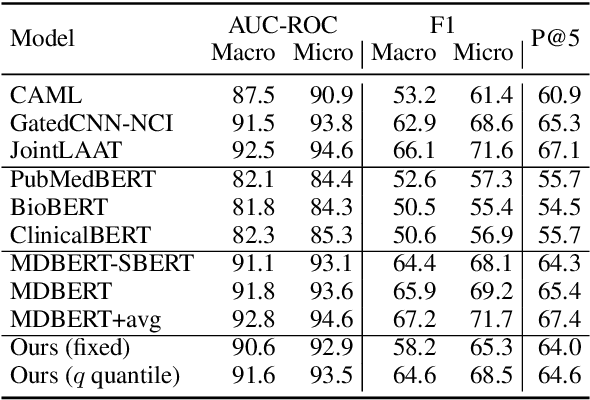
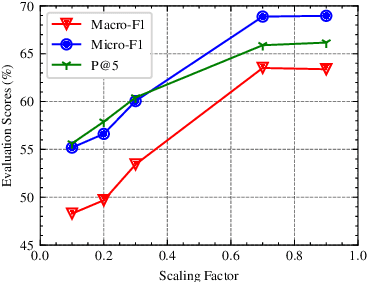
Many computational linguistic methods have been proposed to study the information content of languages. We consider two interesting research questions: 1) how is information distributed over long documents, and 2) how does content reduction, such as token selection and text summarization, affect the information density in long documents. We present four criteria for information density estimation for long documents, including surprisal, entropy, uniform information density, and lexical density. Among those criteria, the first three adopt the measures from information theory. We propose an attention-based word selection method for clinical notes and study machine summarization for multiple-domain documents. Our findings reveal the systematic difference in information density of long text in various domains. Empirical results on automated medical coding from long clinical notes show the effectiveness of the attention-based word selection method.
Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
Sep 21, 2023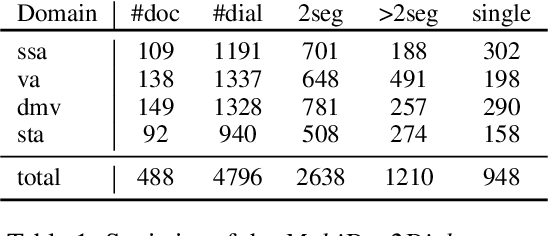
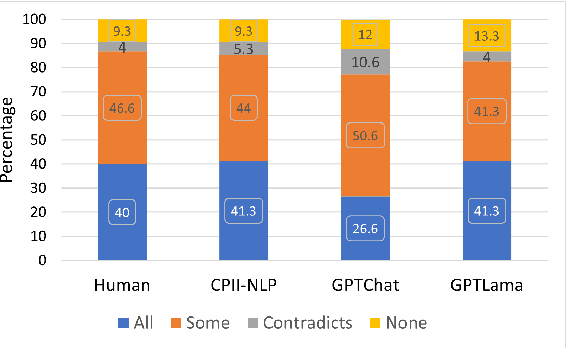
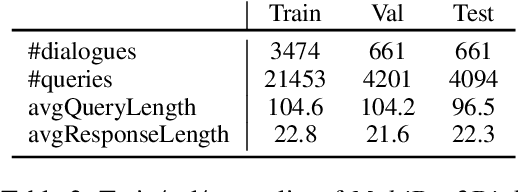

In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
NLQxform: A Language Model-based Question to SPARQL Transformer
Nov 08, 2023In recent years, scholarly data has grown dramatically in terms of both scale and complexity. It becomes increasingly challenging to retrieve information from scholarly knowledge graphs that include large-scale heterogeneous relationships, such as authorship, affiliation, and citation, between various types of entities, e.g., scholars, papers, and organizations. As part of the Scholarly QALD Challenge, this paper presents a question-answering (QA) system called NLQxform, which provides an easy-to-use natural language interface to facilitate accessing scholarly knowledge graphs. NLQxform allows users to express their complex query intentions in natural language questions. A transformer-based language model, i.e., BART, is employed to translate questions into standard SPARQL queries, which can be evaluated to retrieve the required information. According to the public leaderboard of the Scholarly QALD Challenge at ISWC 2023 (Task 1: DBLP-QUAD - Knowledge Graph Question Answering over DBLP), NLQxform achieved an F1 score of 0.85 and ranked first on the QA task, demonstrating the competitiveness of the system.
Deep Image Semantic Communication Model for Artificial Intelligent Internet of Things
Nov 08, 2023With the rapid development of Artificial Intelligent Internet of Things (AIoT), the image data from AIoT devices has been witnessing the explosive increasing. In this paper, a novel deep image semantic communication model is proposed for the efficient image communication in AIoT. Particularly, at the transmitter side, a high-precision image semantic segmentation algorithm is proposed to extract the semantic information of the image to achieve significant compression of the image data. At the receiver side, a semantic image restoration algorithm based on Generative Adversarial Network (GAN) is proposed to convert the semantic image to a real scene image with detailed information. Simulation results demonstrate that the proposed image semantic communication model can improve the image compression ratio and recovery accuracy by 71.93% and 25.07% on average in comparison with WebP and CycleGAN, respectively. More importantly, our demo experiment shows that the proposed model reduces the total delay by 95.26% in the image communication, when comparing with the original image transmission.
Dynamic Local Attention with Hierarchical Patching for Irregular Clinical Time Series
Nov 13, 2023Irregular multivariate time series data is prevalent in the clinical and healthcare domains. It is characterized by time-wise and feature-wise irregularities, making it challenging for machine learning methods to work with. To solve this, we introduce a new model architecture composed of two modules: (1) DLA, a Dynamic Local Attention mechanism that uses learnable queries and feature-specific local windows when computing the self-attention operation. This results in aggregating irregular time steps raw input within each window to a harmonized regular latent space representation while taking into account the different features' sampling rates. (2) A hierarchical MLP mixer that processes the output of DLA through multi-scale patching to leverage information at various scales for the downstream tasks. Our approach outperforms state-of-the-art methods on three real-world datasets, including the latest clinical MIMIC IV dataset.