 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image Patch-Matching with Graph-Based Learning in Street Scenes
Nov 08, 2023
Matching landmark patches from a real-time image captured by an on-vehicle camera with landmark patches in an image database plays an important role in various computer perception tasks for autonomous driving. Current methods focus on local matching for regions of interest and do not take into account spatial neighborhood relationships among the image patches, which typically correspond to objects in the environment. In this paper, we construct a spatial graph with the graph vertices corresponding to patches and edges capturing the spatial neighborhood information. We propose a joint feature and metric learning model with graph-based learning. We provide a theoretical basis for the graph-based loss by showing that the information distance between the distributions conditioned on matched and unmatched pairs is maximized under our framework. We evaluate our model using several street-scene datasets and demonstrate that our approach achieves state-of-the-art matching results.
SINCERE: Supervised Information Noise-Contrastive Estimation REvisited
Sep 25, 2023The information noise-contrastive estimation (InfoNCE) loss function provides the basis of many self-supervised deep learning methods due to its strong empirical results and theoretic motivation. Previous work suggests a supervised contrastive (SupCon) loss to extend InfoNCE to learn from available class labels. This SupCon loss has been widely-used due to reports of good empirical performance. However, in this work we suggest that the specific SupCon loss formulated by prior work has questionable theoretic justification, because it can encourage images from the same class to repel one another in the learned embedding space. This problematic behavior gets worse as the number of inputs sharing one class label increases. We propose the Supervised InfoNCE REvisited (SINCERE) loss as a remedy. SINCERE is a theoretically justified solution for a supervised extension of InfoNCE that never causes images from the same class to repel one another. We further show that minimizing our new loss is equivalent to maximizing a bound on the KL divergence between class conditional embedding distributions. We compare SINCERE and SupCon losses in terms of learning trajectories during pretraining and in ultimate linear classifier performance after finetuning. Our proposed SINCERE loss better separates embeddings from different classes during pretraining while delivering competitive accuracy.
Co-data Learning for Bayesian Additive Regression Trees
Nov 16, 2023Medical prediction applications often need to deal with small sample sizes compared to the number of covariates. Such data pose problems for prediction and variable selection, especially when the covariate-response relationship is complicated. To address these challenges, we propose to incorporate co-data, i.e. external information on the covariates, into Bayesian additive regression trees (BART), a sum-of-trees prediction model that utilizes priors on the tree parameters to prevent overfitting. To incorporate co-data, an empirical Bayes (EB) framework is developed that estimates, assisted by a co-data model, prior covariate weights in the BART model. The proposed method can handle multiple types of co-data simultaneously. Furthermore, the proposed EB framework enables the estimation of the other hyperparameters of BART as well, rendering an appealing alternative to cross-validation. We show that the method finds relevant covariates and that it improves prediction compared to default BART in simulations. If the covariate-response relationship is nonlinear, the method benefits from the flexibility of BART to outperform regression-based co-data learners. Finally, the use of co-data enhances prediction in an application to diffuse large B-cell lymphoma prognosis based on clinical covariates, gene mutations, DNA translocations, and DNA copy number data. Keywords: Bayesian additive regression trees; Empirical Bayes; Co-data; High-dimensional data; Omics; Prediction
uHD: Unary Processing for Lightweight and Dynamic Hyperdimensional Computing
Nov 16, 2023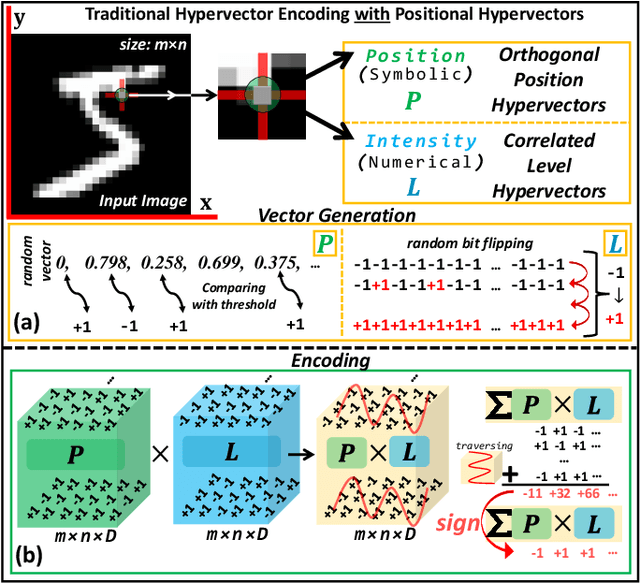
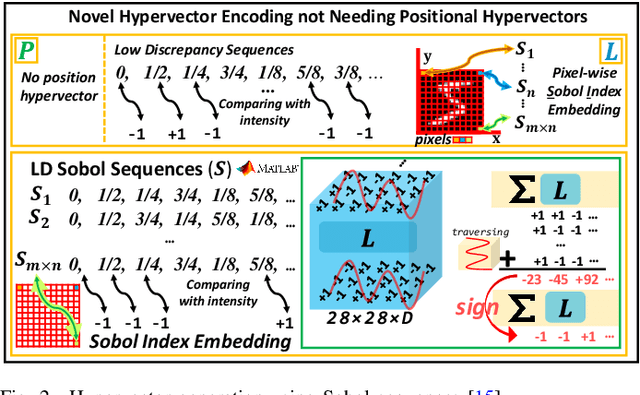
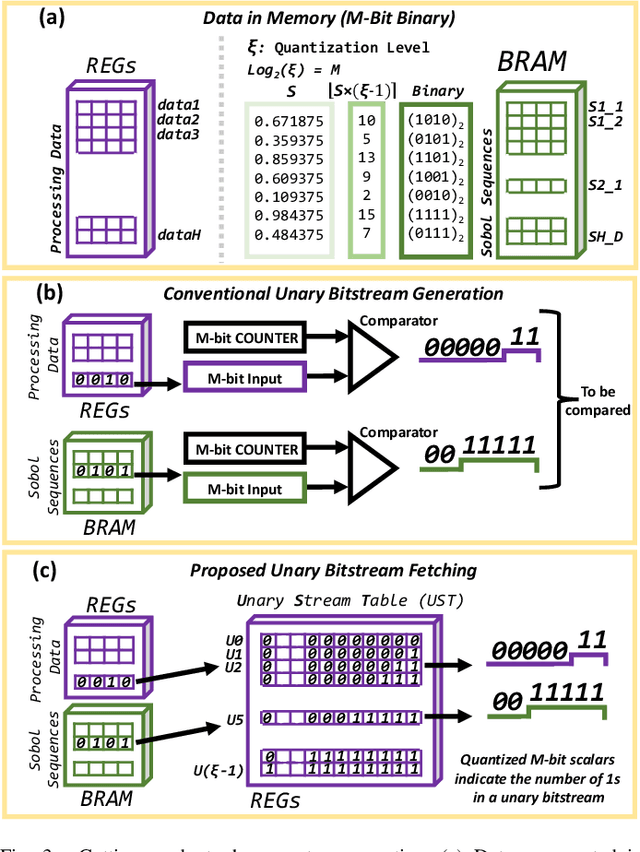
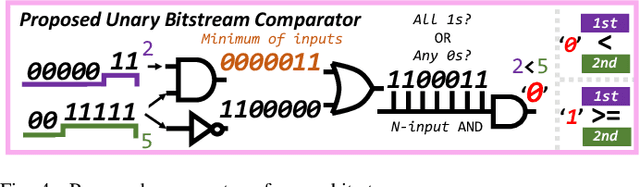
Hyperdimensional computing (HDC) is a novel computational paradigm that operates on long-dimensional vectors known as hypervectors. The hypervectors are constructed as long bit-streams and form the basic building blocks of HDC systems. In HDC, hypervectors are generated from scalar values without taking their bit significance into consideration. HDC has been shown to be efficient and robust in various data processing applications, including computer vision tasks. To construct HDC models for vision applications, the current state-of-the-art practice utilizes two parameters for data encoding: pixel intensity and pixel position. However, the intensity and position information embedded in high-dimensional vectors are generally not generated dynamically in the HDC models. Consequently, the optimal design of hypervectors with high model accuracy requires powerful computing platforms for training. A more efficient approach to generating hypervectors is to create them dynamically during the training phase, which results in accurate, low-cost, and highly performable vectors. To this aim, we use low-discrepancy sequences to generate intensity hypervectors only, while avoiding position hypervectors. By doing so, the multiplication step in vector encoding is eliminated, resulting in a power-efficient HDC system. For the first time in the literature, our proposed approach employs lightweight vector generators utilizing unary bit-streams for efficient encoding of data instead of using conventional comparator-based generators.
SABAF: Removing Strong Attribute Bias from Neural Networks with Adversarial Filtering
Nov 16, 2023Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for prediction is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. To that end, in this work, we mathematically and empirically reveal the limitation of existing attribute bias removal methods in presence of strong bias and propose a new method that can mitigate this limitation. Specifically, we first derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength, revealing that they are effective only when the inherent bias in the dataset is relatively weak. Next, we derive a necessary condition for the existence of any method that can remove attribute bias regardless of the bias strength. Inspired by this condition, we then propose a new method using an adversarial objective that directly filters out protected attributes in the input space while maximally preserving all other attributes, without requiring any specific target label. The proposed method achieves state-of-the-art performance in both strong and moderate bias settings. We provide extensive experiments on synthetic, image, and census datasets, to verify the derived theoretical bound and its consequences in practice, and evaluate the effectiveness of the proposed method in removing strong attribute bias.
In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering
Nov 16, 2023Large language models (LLMs) demonstrate emergent in-context learning capabilities, where they adapt to new tasks based on example demonstrations. However, in-context learning has seen limited effectiveness in many settings, is difficult to quantitatively control and takes up context window space. To overcome these limitations, we propose an alternative approach that recasts in-context learning as in-context vectors (ICV). Using ICV has two steps. We first use a forward pass on demonstration examples to create the in-context vector from the latent embedding of the LLM. This vector captures essential information about the intended task. On a new query, instead of adding demonstrations to the prompt, we shift the latent states of the LLM using the ICV. The ICV approach has several benefits: 1) it enables the LLM to more effectively follow the demonstration examples; 2) it's easy to control by adjusting the magnitude of the ICV; 3) it reduces the length of the prompt by removing the in-context demonstrations; 4) ICV is computationally much more efficient than fine-tuning. We demonstrate that ICV achieves better performance compared to standard in-context learning and fine-tuning on diverse tasks including safety, style transfer, role-playing and formatting. Moreover, we show that we can flexibly teach LLM to simultaneously follow different types of instructions by simple vector arithmetics on the corresponding ICVs.
Beyond PCA: A Probabilistic Gram-Schmidt Approach to Feature Extraction
Nov 15, 2023Linear feature extraction at the presence of nonlinear dependencies among the data is a fundamental challenge in unsupervised learning. We propose using a Probabilistic Gram-Schmidt (PGS) type orthogonalization process in order to detect and map out redundant dimensions. Specifically, by applying the PGS process over any family of functions which presumably captures the nonlinear dependencies in the data, we construct a series of covariance matrices that can either be used to remove those dependencies from the principal components, or to identify new large-variance directions. In the former case, we prove that under certain assumptions the resulting algorithms detect and remove nonlinear dependencies whenever those dependencies lie in the linear span of the chosen function family. In the latter, we provide information-theoretic guarantees in terms of entropy reduction. Both proposed methods extract linear features from the data while removing nonlinear redundancies. We provide simulation results on synthetic and real-world datasets which show improved performance over PCA and state-of-the-art linear feature extraction algorithms, both in terms of variance maximization of the extracted features, and in terms of improved performance of classification algorithms.
A Spectral Diffusion Prior for Hyperspectral Image Super-Resolution
Nov 15, 2023Fusion-based hyperspectral image (HSI) super-resolution aims to produce a high-spatial-resolution HSI by fusing a low-spatial-resolution HSI and a high-spatial-resolution multispectral image. Such a HSI super-resolution process can be modeled as an inverse problem, where the prior knowledge is essential for obtaining the desired solution. Motivated by the success of diffusion models, we propose a novel spectral diffusion prior for fusion-based HSI super-resolution. Specifically, we first investigate the spectrum generation problem and design a spectral diffusion model to model the spectral data distribution. Then, in the framework of maximum a posteriori, we keep the transition information between every two neighboring states during the reverse generative process, and thereby embed the knowledge of trained spectral diffusion model into the fusion problem in the form of a regularization term. At last, we treat each generation step of the final optimization problem as its subproblem, and employ the Adam to solve these subproblems in a reverse sequence. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The code of the proposed approach will be available on https://github.com/liuofficial/SDP.
SparseSpikformer: A Co-Design Framework for Token and Weight Pruning in Spiking Transformer
Nov 15, 2023As the third-generation neural network, the Spiking Neural Network (SNN) has the advantages of low power consumption and high energy efficiency, making it suitable for implementation on edge devices. More recently, the most advanced SNN, Spikformer, combines the self-attention module from Transformer with SNN to achieve remarkable performance. However, it adopts larger channel dimensions in MLP layers, leading to an increased number of redundant model parameters. To effectively decrease the computational complexity and weight parameters of the model, we explore the Lottery Ticket Hypothesis (LTH) and discover a very sparse ($\ge$90%) subnetwork that achieves comparable performance to the original network. Furthermore, we also design a lightweight token selector module, which can remove unimportant background information from images based on the average spike firing rate of neurons, selecting only essential foreground image tokens to participate in attention calculation. Based on that, we present SparseSpikformer, a co-design framework aimed at achieving sparsity in Spikformer through token and weight pruning techniques. Experimental results demonstrate that our framework can significantly reduce 90% model parameters and cut down Giga Floating-Point Operations (GFLOPs) by 20% while maintaining the accuracy of the original model.
ActiveDC: Distribution Calibration for Active Finetuning
Nov 15, 2023The pretraining-finetuning paradigm has gained popularity in various computer vision tasks. In this paradigm, the emergence of active finetuning arises due to the abundance of large-scale data and costly annotation requirements. Active finetuning involves selecting a subset of data from an unlabeled pool for annotation, facilitating subsequent finetuning. However, the use of a limited number of training samples can lead to a biased distribution, potentially resulting in model overfitting. In this paper, we propose a new method called ActiveDC for the active finetuning tasks. Firstly, we select samples for annotation by optimizing the distribution similarity between the subset to be selected and the entire unlabeled pool in continuous space. Secondly, we calibrate the distribution of the selected samples by exploiting implicit category information in the unlabeled pool. The feature visualization provides an intuitive sense of the effectiveness of our approach to distribution calibration. We conducted extensive experiments on three image classification datasets with different sampling ratios. The results indicate that ActiveDC consistently outperforms the baseline performance in all image classification tasks. The improvement is particularly significant when the sampling ratio is low, with performance gains of up to 10%. Our code will be released.