 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CRYPTO-MINE: Cryptanalysis via Mutual Information Neural Estimation
Sep 14, 2023
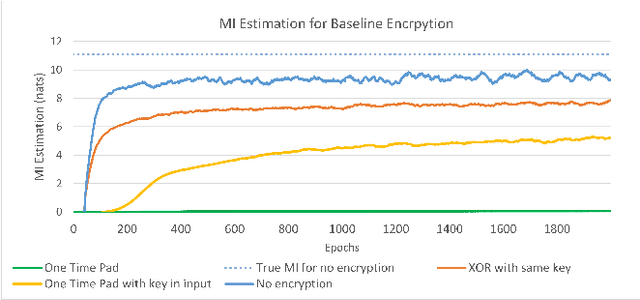
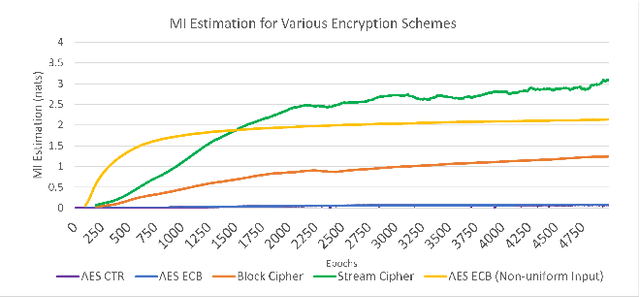
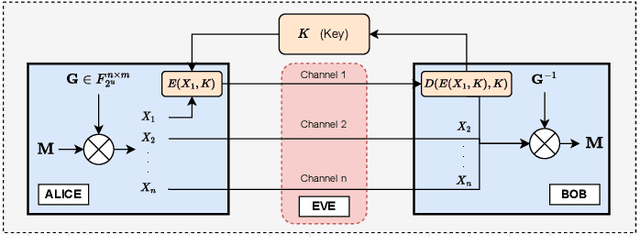
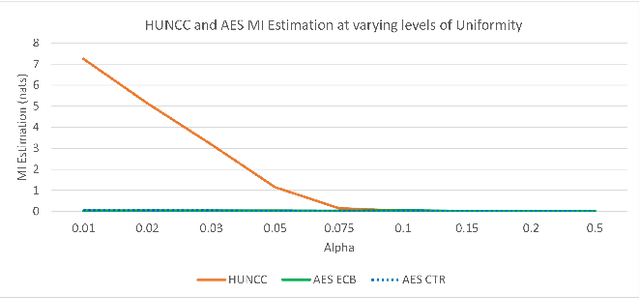
The use of Mutual Information (MI) as a measure to evaluate the efficiency of cryptosystems has an extensive history. However, estimating MI between unknown random variables in a high-dimensional space is challenging. Recent advances in machine learning have enabled progress in estimating MI using neural networks. This work presents a novel application of MI estimation in the field of cryptography. We propose applying this methodology directly to estimate the MI between plaintext and ciphertext in a chosen plaintext attack. The leaked information, if any, from the encryption could potentially be exploited by adversaries to compromise the computational security of the cryptosystem. We evaluate the efficiency of our approach by empirically analyzing multiple encryption schemes and baseline approaches. Furthermore, we extend the analysis to novel network coding-based cryptosystems that provide individual secrecy and study the relationship between information leakage and input distribution.
Exploring Machine Learning Models for Federated Learning: A Review of Approaches, Performance, and Limitations
Nov 17, 2023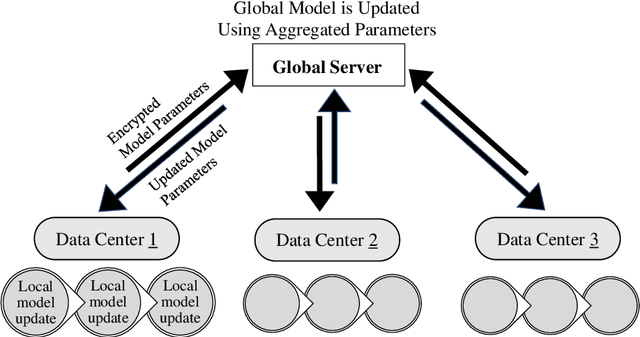

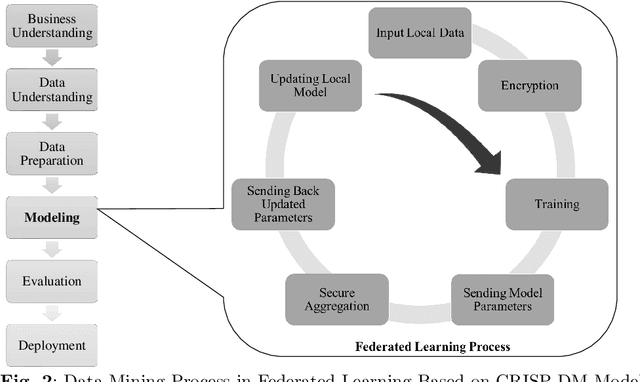
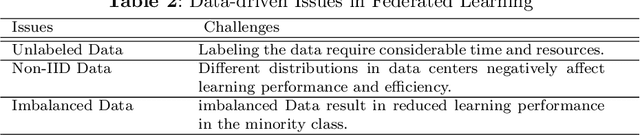
In the growing world of artificial intelligence, federated learning is a distributed learning framework enhanced to preserve the privacy of individuals' data. Federated learning lays the groundwork for collaborative research in areas where the data is sensitive. Federated learning has several implications for real-world problems. In times of crisis, when real-time decision-making is critical, federated learning allows multiple entities to work collectively without sharing sensitive data. This distributed approach enables us to leverage information from multiple sources and gain more diverse insights. This paper is a systematic review of the literature on privacy-preserving machine learning in the last few years based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. Specifically, we have presented an extensive review of supervised/unsupervised machine learning algorithms, ensemble methods, meta-heuristic approaches, blockchain technology, and reinforcement learning used in the framework of federated learning, in addition to an overview of federated learning applications. This paper reviews the literature on the components of federated learning and its applications in the last few years. The main purpose of this work is to provide researchers and practitioners with a comprehensive overview of federated learning from the machine learning point of view. A discussion of some open problems and future research directions in federated learning is also provided.
From Principle to Practice: Vertical Data Minimization for Machine Learning
Nov 17, 2023Aiming to train and deploy predictive models, organizations collect large amounts of detailed client data, risking the exposure of private information in the event of a breach. To mitigate this, policymakers increasingly demand compliance with the data minimization (DM) principle, restricting data collection to only that data which is relevant and necessary for the task. Despite regulatory pressure, the problem of deploying machine learning models that obey DM has so far received little attention. In this work, we address this challenge in a comprehensive manner. We propose a novel vertical DM (vDM) workflow based on data generalization, which by design ensures that no full-resolution client data is collected during training and deployment of models, benefiting client privacy by reducing the attack surface in case of a breach. We formalize and study the corresponding problem of finding generalizations that both maximize data utility and minimize empirical privacy risk, which we quantify by introducing a diverse set of policy-aligned adversarial scenarios. Finally, we propose a range of baseline vDM algorithms, as well as Privacy-aware Tree (PAT), an especially effective vDM algorithm that outperforms all baselines across several settings. We plan to release our code as a publicly available library, helping advance the standardization of DM for machine learning. Overall, we believe our work can help lay the foundation for further exploration and adoption of DM principles in real-world applications.
A Graphical Model of Hurricane Evacuation Behaviors
Nov 16, 2023Natural disasters such as hurricanes are increasing and causing widespread devastation. People's decisions and actions regarding whether to evacuate or not are critical and have a large impact on emergency planning and response. Our interest lies in computationally modeling complex relationships among various factors influencing evacuation decisions. We conducted a study on the evacuation of Hurricane Irma of the 2017 Atlantic hurricane season. The study was guided by the Protection motivation theory (PMT), a widely-used framework to understand people's responses to potential threats. Graphical models were constructed to represent the complex relationships among the factors involved and the evacuation decision. We evaluated different graphical structures based on conditional independence tests using Irma data. The final model largely aligns with PMT. It shows that both risk perception (threat appraisal) and difficulties in evacuation (coping appraisal) influence evacuation decisions directly and independently. Certain information received from media was found to influence risk perception, and through it influence evacuation behaviors indirectly. In addition, several variables were found to influence both risk perception and evacuation behaviors directly, including family and friends' suggestions, neighbors' evacuation behaviors, and evacuation notices from officials.
CARE: Extracting Experimental Findings From Clinical Literature
Nov 16, 2023Extracting fine-grained experimental findings from literature can provide massive utility for scientific applications. Prior work has focused on developing annotation schemas and datasets for limited aspects of this problem, leading to simpler information extraction datasets which do not capture the real-world complexity and nuance required for this task. Focusing on biomedicine, this work presents CARE (Clinical Aggregation-oriented Result Extraction) -- a new IE dataset for the task of extracting clinical findings. We develop a new annotation schema capturing fine-grained findings as n-ary relations between entities and attributes, which includes phenomena challenging for current IE systems such as discontinuous entity spans, nested relations, and variable arity n-ary relations. Using this schema, we collect extensive annotations for 700 abstracts from two sources: clinical trials and case reports. We also benchmark the performance of various state-of-the-art IE systems on our dataset, including extractive models and generative LLMs in fully supervised and limited data settings. Our results demonstrate the difficulty of our dataset -- even SOTA models such as GPT4 struggle, particularly on relation extraction. We release our annotation schema and CARE to encourage further research on extracting and aggregating scientific findings from literature.
On the Quantification of Image Reconstruction Uncertainty without Training Data
Nov 16, 2023Computational imaging plays a pivotal role in determining hidden information from sparse measurements. A robust inverse solver is crucial to fully characterize the uncertainty induced by these measurements, as it allows for the estimation of the complete posterior of unrecoverable targets. This, in turn, facilitates a probabilistic interpretation of observational data for decision-making. In this study, we propose a deep variational framework that leverages a deep generative model to learn an approximate posterior distribution to effectively quantify image reconstruction uncertainty without the need for training data. We parameterize the target posterior using a flow-based model and minimize their Kullback-Leibler (KL) divergence to achieve accurate uncertainty estimation. To bolster stability, we introduce a robust flow-based model with bi-directional regularization and enhance expressivity through gradient boosting. Additionally, we incorporate a space-filling design to achieve substantial variance reduction on both latent prior space and target posterior space. We validate our method on several benchmark tasks and two real-world applications, namely fastMRI and black hole image reconstruction. Our results indicate that our method provides reliable and high-quality image reconstruction with robust uncertainty estimation.
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
Temporal-Aware Refinement for Video-based Human Pose and Shape Recovery
Nov 16, 2023
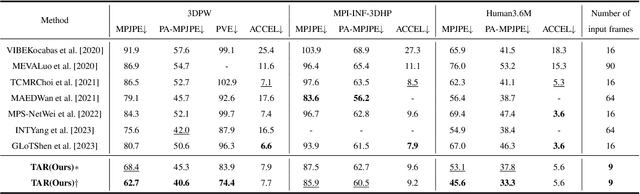
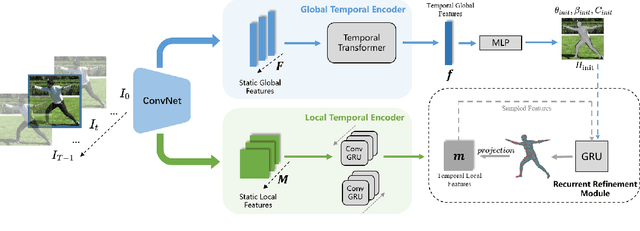
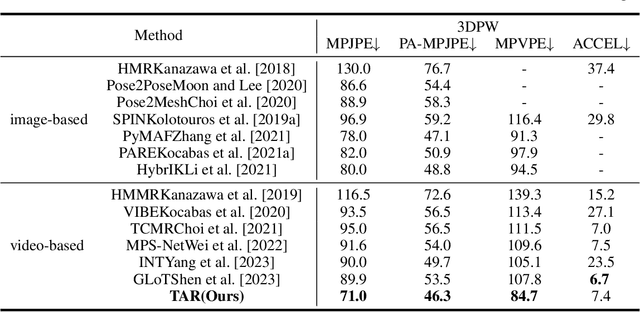
Though significant progress in human pose and shape recovery from monocular RGB images has been made in recent years, obtaining 3D human motion with high accuracy and temporal consistency from videos remains challenging. Existing video-based methods tend to reconstruct human motion from global image features, which lack detailed representation capability and limit the reconstruction accuracy. In this paper, we propose a Temporal-Aware Refining Network (TAR), to synchronously explore temporal-aware global and local image features for accurate pose and shape recovery. First, a global transformer encoder is introduced to obtain temporal global features from static feature sequences. Second, a bidirectional ConvGRU network takes the sequence of high-resolution feature maps as input, and outputs temporal local feature maps that maintain high resolution and capture the local motion of the human body. Finally, a recurrent refinement module iteratively updates estimated SMPL parameters by leveraging both global and local temporal information to achieve accurate and smooth results. Extensive experiments demonstrate that our TAR obtains more accurate results than previous state-of-the-art methods on popular benchmarks, i.e., 3DPW, MPI-INF-3DHP, and Human3.6M.
Clarify When Necessary: Resolving Ambiguity Through Interaction with LMs
Nov 16, 2023Resolving ambiguities through interaction is a hallmark of natural language, and modeling this behavior is a core challenge in crafting AI assistants. In this work, we study such behavior in LMs by proposing a task-agnostic framework for resolving ambiguity by asking users clarifying questions. Our framework breaks down this objective into three subtasks: (1) determining when clarification is needed, (2) determining what clarifying question to ask, and (3) responding accurately with the new information gathered through clarification. We evaluate systems across three NLP applications: question answering, machine translation and natural language inference. For the first subtask, we present a novel uncertainty estimation approach, intent-sim, that determines the utility of querying for clarification by estimating the entropy over user intents. Our method consistently outperforms existing uncertainty estimation approaches at identifying predictions that will benefit from clarification. When only allowed to ask for clarification on 10% of examples, our system is able to double the performance gains over randomly selecting examples to clarify. Furthermore, we find that intent-sim is robust, demonstrating improvements across a wide range of NLP tasks and LMs. Together, our work lays foundation for studying clarifying interactions with LMs.
RED-DOT: Multimodal Fact-checking via Relevant Evidence Detection
Nov 16, 2023Online misinformation is often multimodal in nature, i.e., it is caused by misleading associations between texts and accompanying images. To support the fact-checking process, researchers have been recently developing automatic multimodal methods that gather and analyze external information, evidence, related to the image-text pairs under examination. However, prior works assumed all collected evidence to be relevant. In this study, we introduce a "Relevant Evidence Detection" (RED) module to discern whether each piece of evidence is relevant, to support or refute the claim. Specifically, we develop the "Relevant Evidence Detection Directed Transformer" (RED-DOT) and explore multiple architectural variants (e.g., single or dual-stage) and mechanisms (e.g., "guided attention"). Extensive ablation and comparative experiments demonstrate that RED-DOT achieves significant improvements over the state-of-the-art on the VERITE benchmark by up to 28.5%. Furthermore, our evidence re-ranking and element-wise modality fusion led to RED-DOT achieving competitive and even improved performance on NewsCLIPings+, without the need for numerous evidence or multiple backbone encoders. Finally, our qualitative analysis demonstrates that the proposed "guided attention" module has the potential to enhance the architecture's interpretability. We release our code at: https://github.com/stevejpapad/relevant-evidence-detection