 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Knowledge Question Answering via Abstract Reasoning Induction
Nov 15, 2023
In this paper, we tackle the significant challenge of temporal knowledge reasoning in Large Language Models (LLMs), an area where such models frequently encounter difficulties. These difficulties often result in the generation of misleading or incorrect information, primarily due to their limited capacity to process evolving factual knowledge and complex temporal logic. In response, we propose a novel, constructivism-based approach that advocates for a paradigm shift in LLM learning towards an active, ongoing process of knowledge synthesis and customization. At the heart of our proposal is the Abstract Reasoning Induction ARI framework, which divides temporal reasoning into two distinct phases: Knowledge-agnostic and Knowledge-based. This division aims to reduce instances of hallucinations and improve LLMs' capacity for integrating abstract methodologies derived from historical data. Our approach achieves remarkable improvements, with relative gains of 29.7\% and 9.27\% on two temporal QA datasets, underscoring its efficacy in advancing temporal reasoning in LLMs. The code will be released at https://github.com/czy1999/ARI.
Do Localization Methods Actually Localize Memorized Data in LLMs?
Nov 15, 2023Large language models (LLMs) can memorize many pretrained sequences verbatim. This paper studies if we can locate a small set of neurons in LLMs responsible for memorizing a given sequence. While the concept of localization is often mentioned in prior work, methods for localization have never been systematically and directly evaluated; we address this with two benchmarking approaches. In our INJ Benchmark, we actively inject a piece of new information into a small subset of LLM weights and measure whether localization methods can identify these "ground truth" weights. In the DEL Benchmark, we study localization of pretrained data that LLMs have already memorized; while this setting lacks ground truth, we can still evaluate localization by measuring whether dropping out located neurons erases a memorized sequence from the model. We evaluate five localization methods on our two benchmarks, and both show similar rankings. All methods exhibit promising localization ability, especially for pruning-based methods, though the neurons they identify are not necessarily specific to a single memorized sequence.
Clifford Algebra-Based Iterated Extended Kalman Filter with Application to Low-Cost INS/GNSS Navigation
Nov 15, 2023The traditional GNSS-aided inertial navigation system (INS) usually exploits the extended Kalman filter (EKF) for state estimation, and the initial attitude accuracy is key to the filtering performance. To spare the reliance on the initial attitude, this work generalizes the previously proposed trident quaternion within the framework of Clifford algebra to represent the extended pose, IMU biases and lever arms on the Lie group. Consequently, a quasi-group-affine system is established for the low-cost INS/GNSS integrated navigation system, and the right-error Clifford algebra-based EKF (Clifford-RQEKF) is accordingly developed. The iterated filtering approach is further applied to significantly improve the performances of the Clifford-RQEKF and the previously proposed trident quaternion-based EKFs. Numerical simulations and experiments show that all iterated filtering approaches fulfill the fast and global convergence without the prior attitude information, whereas the iterated Clifford-RQEKF performs much better than the others under especially large IMU biases.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
Morphology-Enhanced CAM-Guided SAM for weakly supervised Breast Lesion Segmentation
Nov 18, 2023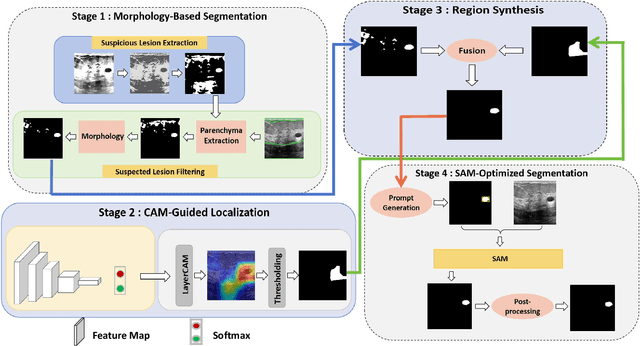
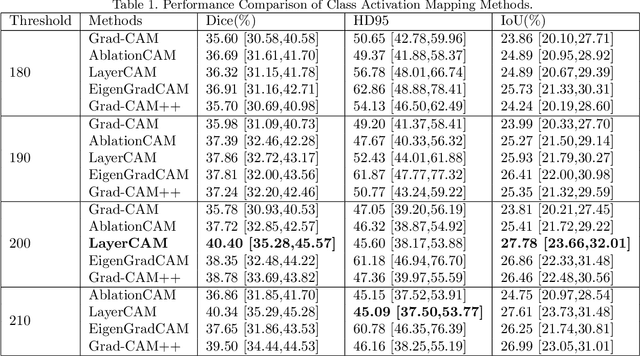
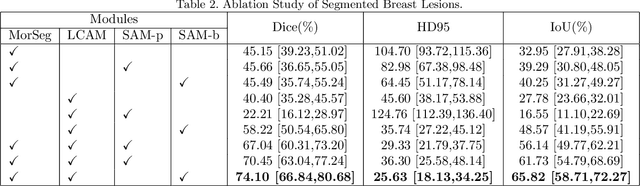
Breast cancer diagnosis challenges both patients and clinicians, with early detection being crucial for effective treatment. Ultrasound imaging plays a key role in this, but its utility is hampered by the need for precise lesion segmentation-a task that is both time-consuming and labor-intensive. To address these challenges, we propose a new framework: a morphology-enhanced, Class Activation Map (CAM)-guided model, which is optimized using a computer vision foundation model known as SAM. This innovative framework is specifically designed for weakly supervised lesion segmentation in early-stage breast ultrasound images. Our approach uniquely leverages image-level annotations, which removes the requirement for detailed pixel-level annotation. Initially, we perform a preliminary segmentation using breast lesion morphology knowledge. Following this, we accurately localize lesions by extracting semantic information through a CAM-based heatmap. These two elements are then fused together, serving as a prompt to guide the SAM in performing refined segmentation. Subsequently, post-processing techniques are employed to rectify topological errors made by the SAM. Our method not only simplifies the segmentation process but also attains accuracy comparable to supervised learning methods that rely on pixel-level annotation. Our framework achieves a Dice score of 74.39% on the test set, demonstrating compareable performance with supervised learning methods. Additionally, it outperforms a supervised learning model, in terms of the Hausdorff distance, scoring 24.27 compared to Deeplabv3+'s 32.22. These experimental results showcase its feasibility and superior performance in integrating weakly supervised learning with SAM. The code is made available at: https://github.com/YueXin18/MorSeg-CAM-SAM.
POISE: Pose Guided Human Silhouette Extraction under Occlusions
Nov 09, 2023Human silhouette extraction is a fundamental task in computer vision with applications in various downstream tasks. However, occlusions pose a significant challenge, leading to incomplete and distorted silhouettes. To address this challenge, we introduce POISE: Pose Guided Human Silhouette Extraction under Occlusions, a novel self-supervised fusion framework that enhances accuracy and robustness in human silhouette prediction. By combining initial silhouette estimates from a segmentation model with human joint predictions from a 2D pose estimation model, POISE leverages the complementary strengths of both approaches, effectively integrating precise body shape information and spatial information to tackle occlusions. Furthermore, the self-supervised nature of \POISE eliminates the need for costly annotations, making it scalable and practical. Extensive experimental results demonstrate its superiority in improving silhouette extraction under occlusions, with promising results in downstream tasks such as gait recognition. The code for our method is available https://github.com/take2rohit/poise.
Profiling Irony & Stereotype: Exploring Sentiment, Topic, and Lexical Features
Nov 08, 2023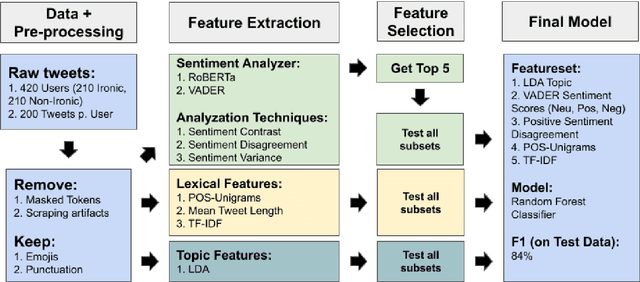
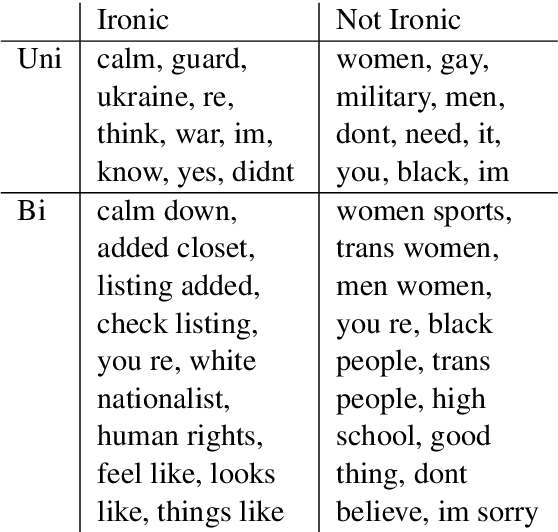


Social media has become a very popular source of information. With this popularity comes an interest in systems that can classify the information produced. This study tries to create such a system detecting irony in Twitter users. Recent work emphasize the importance of lexical features, sentiment features and the contrast herein along with TF-IDF and topic models. Based on a thorough feature selection process, the resulting model contains specific sub-features from these areas. Our model reaches an F1-score of 0.84, which is above the baseline. We find that lexical features, especially TF-IDF, contribute the most to our models while sentiment and topic modeling features contribute less to overall performance. Lastly, we highlight multiple interesting and important paths for further exploration.
Preserving Privacy in GANs Against Membership Inference Attack
Nov 06, 2023Generative Adversarial Networks (GANs) have been widely used for generating synthetic data for cases where there is a limited size real-world dataset or when data holders are unwilling to share their data samples. Recent works showed that GANs, due to overfitting and memorization, might leak information regarding their training data samples. This makes GANs vulnerable to Membership Inference Attacks (MIAs). Several defense strategies have been proposed in the literature to mitigate this privacy issue. Unfortunately, defense strategies based on differential privacy are proven to reduce extensively the quality of the synthetic data points. On the other hand, more recent frameworks such as PrivGAN and PAR-GAN are not suitable for small-size training datasets. In the present work, the overfitting in GANs is studied in terms of the discriminator, and a more general measure of overfitting based on the Bhattacharyya coefficient is defined. Then, inspired by Fano's inequality, our first defense mechanism against MIAs is proposed. This framework, which requires only a simple modification in the loss function of GANs, is referred to as the maximum entropy GAN or MEGAN and significantly improves the robustness of GANs to MIAs. As a second defense strategy, a more heuristic model based on minimizing the information leaked from generated samples about the training data points is presented. This approach is referred to as mutual information minimization GAN (MIMGAN) and uses a variational representation of the mutual information to minimize the information that a synthetic sample might leak about the whole training data set. Applying the proposed frameworks to some commonly used data sets against state-of-the-art MIAs reveals that the proposed methods can reduce the accuracy of the adversaries to the level of random guessing accuracy with a small reduction in the quality of the synthetic data samples.
Frequency Domain Decomposition Translation for Enhanced Medical Image Translation Using GANs
Nov 06, 2023Medical Image-to-image translation is a key task in computer vision and generative artificial intelligence, and it is highly applicable to medical image analysis. GAN-based methods are the mainstream image translation methods, but they often ignore the variation and distribution of images in the frequency domain, or only take simple measures to align high-frequency information, which can lead to distortion and low quality of the generated images. To solve these problems, we propose a novel method called frequency domain decomposition translation (FDDT). This method decomposes the original image into a high-frequency component and a low-frequency component, with the high-frequency component containing the details and identity information, and the low-frequency component containing the style information. Next, the high-frequency and low-frequency components of the transformed image are aligned with the transformed results of the high-frequency and low-frequency components of the original image in the same frequency band in the spatial domain, thus preserving the identity information of the image while destroying as little stylistic information of the image as possible. We conduct extensive experiments on MRI images and natural images with FDDT and several mainstream baseline models, and we use four evaluation metrics to assess the quality of the generated images. Compared with the baseline models, optimally, FDDT can reduce Fr\'echet inception distance by up to 24.4%, structural similarity by up to 4.4%, peak signal-to-noise ratio by up to 5.8%, and mean squared error by up to 31%. Compared with the previous method, optimally, FDDT can reduce Fr\'echet inception distance by up to 23.7%, structural similarity by up to 1.8%, peak signal-to-noise ratio by up to 6.8%, and mean squared error by up to 31.6%.
Exploring Machine Learning Models for Federated Learning: A Review of Approaches, Performance, and Limitations
Nov 17, 2023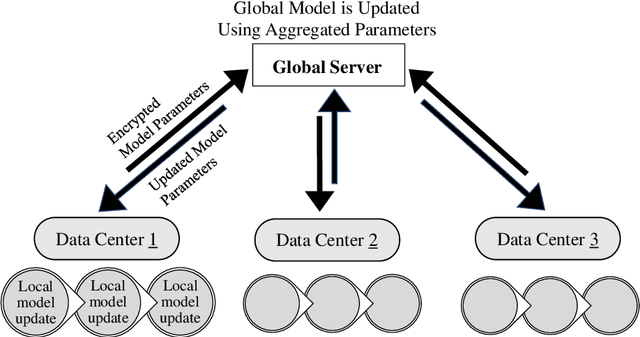

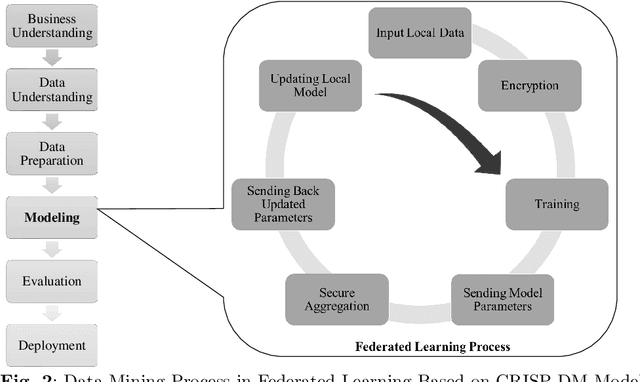
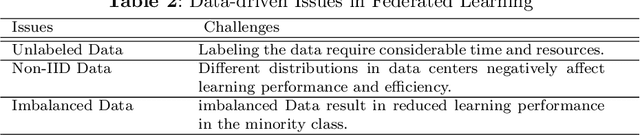
In the growing world of artificial intelligence, federated learning is a distributed learning framework enhanced to preserve the privacy of individuals' data. Federated learning lays the groundwork for collaborative research in areas where the data is sensitive. Federated learning has several implications for real-world problems. In times of crisis, when real-time decision-making is critical, federated learning allows multiple entities to work collectively without sharing sensitive data. This distributed approach enables us to leverage information from multiple sources and gain more diverse insights. This paper is a systematic review of the literature on privacy-preserving machine learning in the last few years based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. Specifically, we have presented an extensive review of supervised/unsupervised machine learning algorithms, ensemble methods, meta-heuristic approaches, blockchain technology, and reinforcement learning used in the framework of federated learning, in addition to an overview of federated learning applications. This paper reviews the literature on the components of federated learning and its applications in the last few years. The main purpose of this work is to provide researchers and practitioners with a comprehensive overview of federated learning from the machine learning point of view. A discussion of some open problems and future research directions in federated learning is also provided.