 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Approaching adverse event detection utilizing transformers on clinical time-series
Nov 15, 2023
Patients being admitted to a hospital will most often be associated with a certain clinical development during their stay. However, there is always a risk of patients being subject to the wrong diagnosis or to a certain treatment not pertaining to the desired effect, potentially leading to adverse events. Our research aims to develop an anomaly detection system for identifying deviations from expected clinical trajectories. To address this goal we analyzed 16 months of vital sign recordings obtained from the Nordland Hospital Trust (NHT). We employed an self-supervised framework based on the STraTS transformer architecture to represent the time series data in a latent space. These representations were then subjected to various clustering techniques to explore potential patient phenotypes based on their clinical progress. While our preliminary results from this ongoing research are promising, they underscore the importance of enhancing the dataset with additional demographic information from patients. This additional data will be crucial for a more comprehensive evaluation of the method's performance.
Temporal Knowledge Question Answering via Abstract Reasoning Induction
Nov 15, 2023In this paper, we tackle the significant challenge of temporal knowledge reasoning in Large Language Models (LLMs), an area where such models frequently encounter difficulties. These difficulties often result in the generation of misleading or incorrect information, primarily due to their limited capacity to process evolving factual knowledge and complex temporal logic. In response, we propose a novel, constructivism-based approach that advocates for a paradigm shift in LLM learning towards an active, ongoing process of knowledge synthesis and customization. At the heart of our proposal is the Abstract Reasoning Induction ARI framework, which divides temporal reasoning into two distinct phases: Knowledge-agnostic and Knowledge-based. This division aims to reduce instances of hallucinations and improve LLMs' capacity for integrating abstract methodologies derived from historical data. Our approach achieves remarkable improvements, with relative gains of 29.7\% and 9.27\% on two temporal QA datasets, underscoring its efficacy in advancing temporal reasoning in LLMs. The code will be released at https://github.com/czy1999/ARI.
Do Localization Methods Actually Localize Memorized Data in LLMs?
Nov 15, 2023Large language models (LLMs) can memorize many pretrained sequences verbatim. This paper studies if we can locate a small set of neurons in LLMs responsible for memorizing a given sequence. While the concept of localization is often mentioned in prior work, methods for localization have never been systematically and directly evaluated; we address this with two benchmarking approaches. In our INJ Benchmark, we actively inject a piece of new information into a small subset of LLM weights and measure whether localization methods can identify these "ground truth" weights. In the DEL Benchmark, we study localization of pretrained data that LLMs have already memorized; while this setting lacks ground truth, we can still evaluate localization by measuring whether dropping out located neurons erases a memorized sequence from the model. We evaluate five localization methods on our two benchmarks, and both show similar rankings. All methods exhibit promising localization ability, especially for pruning-based methods, though the neurons they identify are not necessarily specific to a single memorized sequence.
Clifford Algebra-Based Iterated Extended Kalman Filter with Application to Low-Cost INS/GNSS Navigation
Nov 15, 2023The traditional GNSS-aided inertial navigation system (INS) usually exploits the extended Kalman filter (EKF) for state estimation, and the initial attitude accuracy is key to the filtering performance. To spare the reliance on the initial attitude, this work generalizes the previously proposed trident quaternion within the framework of Clifford algebra to represent the extended pose, IMU biases and lever arms on the Lie group. Consequently, a quasi-group-affine system is established for the low-cost INS/GNSS integrated navigation system, and the right-error Clifford algebra-based EKF (Clifford-RQEKF) is accordingly developed. The iterated filtering approach is further applied to significantly improve the performances of the Clifford-RQEKF and the previously proposed trident quaternion-based EKFs. Numerical simulations and experiments show that all iterated filtering approaches fulfill the fast and global convergence without the prior attitude information, whereas the iterated Clifford-RQEKF performs much better than the others under especially large IMU biases.
Semantic-aware Sampling and Transmission in Energy Harvesting Systems: A POMDP Approach
Nov 11, 2023We study real-time tracking problem in an energy harvesting system with a Markov source under an imperfect channel. We consider both sampling and transmission costs and different from most prior studies that assume the source is fully observable, the sampling cost renders the source unobservable. The goal is to jointly optimize sampling and transmission policies for three semantic-aware metrics: i) the age of information (AoI), ii) general distortion, and iii) the age of incorrect information (AoII). To this end, we formulate and solve a stochastic control problem. Specifically, for the AoI metric, we cast a Markov decision process (MDP) problem and solve it using relative value iteration (RVI). For the distortion and AoII metrics, we utilize the partially observable MDP (POMDP) modeling and leverage the notion of belief MDP formulation of POMDP to find optimal policies. For the distortion metric and the AoII metric under the perfect channel setup, we effectively truncate the corresponding belief space and solve an MDP problem using RVI. For the general setup, a deep reinforcement learning policy is proposed. Through simulations, we demonstrate significant performance improvements achieved by the derived policies. The results reveal various switching-type structures of optimal policies and show that a distortion-optimal policy is also AoII optimal.
Spot: A Natural Language Interface for Geospatial Searches in OSM
Nov 14, 2023Investigative journalists and fact-checkers have found OpenStreetMap (OSM) to be an invaluable resource for their work due to its extensive coverage and intricate details of various locations, which play a crucial role in investigating news scenes. Despite its value, OSM's complexity presents considerable accessibility and usability challenges, especially for those without a technical background. To address this, we introduce 'Spot', a user-friendly natural language interface for querying OSM data. Spot utilizes a semantic mapping from natural language to OSM tags, leveraging artificially generated sentence queries and a T5 transformer. This approach enables Spot to extract relevant information from user-input sentences and display candidate locations matching the descriptions on a map. To foster collaboration and future advancement, all code and generated data is available as an open-source repository.
Higher-Order Expander Graph Propagation
Nov 14, 2023Graph neural networks operate on graph-structured data via exchanging messages along edges. One limitation of this message passing paradigm is the over-squashing problem. Over-squashing occurs when messages from a node's expanded receptive field are compressed into fixed-size vectors, potentially causing information loss. To address this issue, recent works have explored using expander graphs, which are highly-connected sparse graphs with low diameters, to perform message passing. However, current methods on expander graph propagation only consider pair-wise interactions, ignoring higher-order structures in complex data. To explore the benefits of capturing these higher-order correlations while still leveraging expander graphs, we introduce higher-order expander graph propagation. We propose two methods for constructing bipartite expanders and evaluate their performance on both synthetic and real-world datasets.
Robust Learning Based Condition Diagnosis Method for Distribution Network Switchgear
Nov 14, 2023This paper introduces a robust, learning-based method for diagnosing the state of distribution network switchgear, which is crucial for maintaining the power quality for end users. Traditional diagnostic models often rely heavily on expert knowledge and lack robustness. To address this, our method incorporates an expanded feature vector that includes environmental data, temperature readings, switch position, motor operation, insulation conditions, and local discharge information. We tackle the issue of high dimensionality through feature mapping. The method introduces a decision radius to categorize unlabeled samples and updates the model parameters using a combination of supervised and unsupervised loss, along with a consistency regularization function. This approach ensures robust learning even with a limited number of labeled samples. Comparative analysis demonstrates that this method significantly outperforms existing models in both accuracy and robustness.
Comparison of two data fusion approaches for land use classification
Nov 14, 2023Accurate land use maps, describing the territory from an anthropic utilisation point of view, are useful tools for land management and planning. To produce them, the use of optical images alone remains limited. It is therefore necessary to make use of several heterogeneous sources, each carrying complementary or contradictory information due to their imperfections or their different specifications. This study compares two different approaches i.e. a pre-classification and a post-classification fusion approach for combining several sources of spatial data in the context of land use classification. The approaches are applied on authoritative land use data located in the Gers department in the southwest of France. Pre-classification fusion, while not explicitly modeling imperfections, has the best final results, reaching an overall accuracy of 97% and a macro-mean F1 score of 88%.
Fine-tuning and aligning question answering models for complex information extraction tasks
Sep 26, 2023
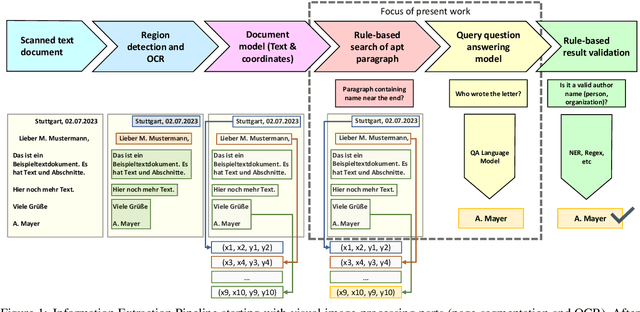
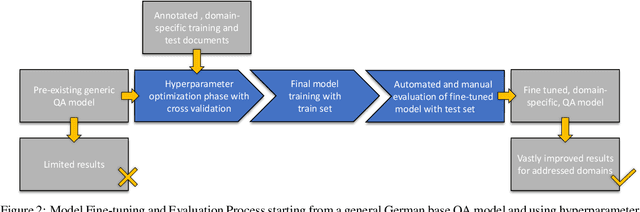

The emergence of Large Language Models (LLMs) has boosted performance and possibilities in various NLP tasks. While the usage of generative AI models like ChatGPT opens up new opportunities for several business use cases, their current tendency to hallucinate fake content strongly limits their applicability to document analysis, such as information retrieval from documents. In contrast, extractive language models like question answering (QA) or passage retrieval models guarantee query results to be found within the boundaries of an according context document, which makes them candidates for more reliable information extraction in productive environments of companies. In this work we propose an approach that uses and integrates extractive QA models for improved feature extraction of German business documents such as insurance reports or medical leaflets into a document analysis solution. We further show that fine-tuning existing German QA models boosts performance for tailored extraction tasks of complex linguistic features like damage cause explanations or descriptions of medication appearance, even with using only a small set of annotated data. Finally, we discuss the relevance of scoring metrics for evaluating information extraction tasks and deduce a combined metric from Levenshtein distance, F1-Score, Exact Match and ROUGE-L to mimic the assessment criteria from human experts.