 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Grad-Shafranov equilibria via data-free physics informed neural networks
Nov 22, 2023
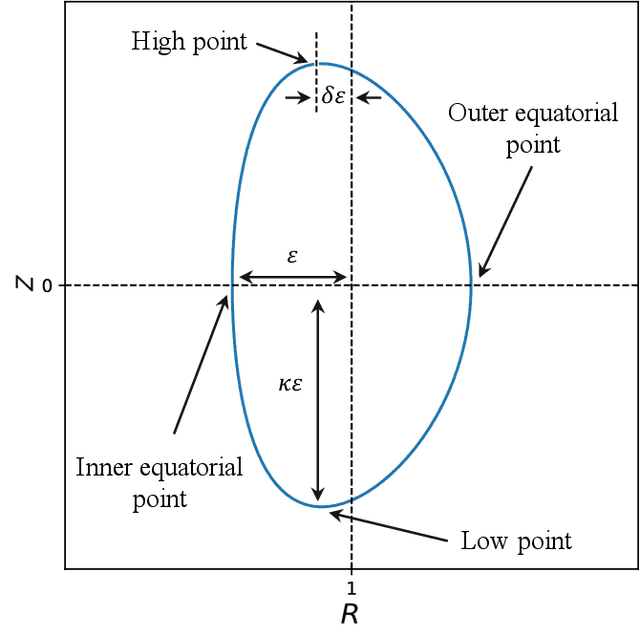
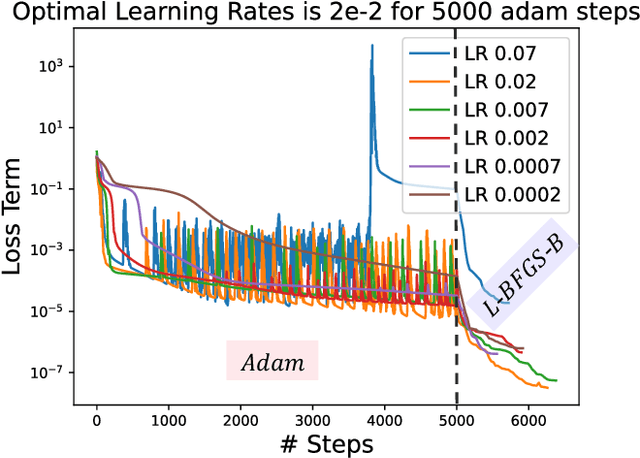
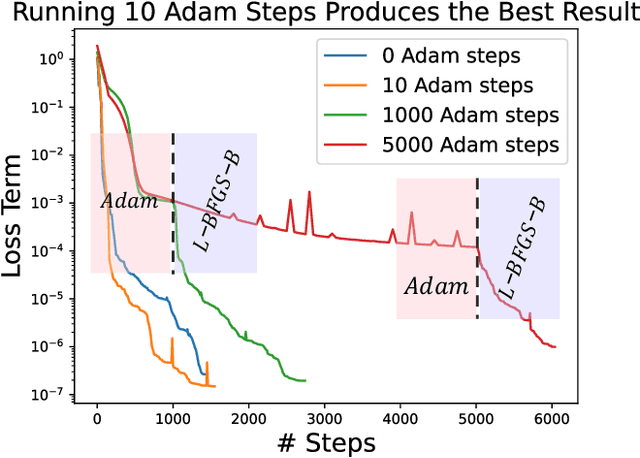
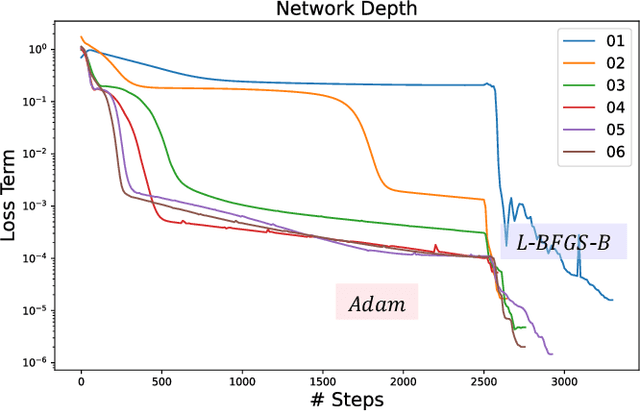
A large number of magnetohydrodynamic (MHD) equilibrium calculations are often required for uncertainty quantification, optimization, and real-time diagnostic information, making MHD equilibrium codes vital to the field of plasma physics. In this paper, we explore a method for solving the Grad-Shafranov equation by using Physics-Informed Neural Networks (PINNs). For PINNs, we optimize neural networks by directly minimizing the residual of the PDE as a loss function. We show that PINNs can accurately and effectively solve the Grad-Shafranov equation with several different boundary conditions. We also explore the parameter space by varying the size of the model, the learning rate, and boundary conditions to map various trade-offs such as between reconstruction error and computational speed. Additionally, we introduce a parameterized PINN framework, expanding the input space to include variables such as pressure, aspect ratio, elongation, and triangularity in order to handle a broader range of plasma scenarios within a single network. Parametrized PINNs could be used in future work to solve inverse problems such as shape optimization.
TSegFormer: 3D Tooth Segmentation in Intraoral Scans with Geometry Guided Transformer
Nov 22, 2023Optical Intraoral Scanners (IOS) are widely used in digital dentistry to provide detailed 3D information of dental crowns and the gingiva. Accurate 3D tooth segmentation in IOSs is critical for various dental applications, while previous methods are error-prone at complicated boundaries and exhibit unsatisfactory results across patients. In this paper, we propose TSegFormer which captures both local and global dependencies among different teeth and the gingiva in the IOS point clouds with a multi-task 3D transformer architecture. Moreover, we design a geometry-guided loss based on a novel point curvature to refine boundaries in an end-to-end manner, avoiding time-consuming post-processing to reach clinically applicable segmentation. In addition, we create a dataset with 16,000 IOSs, the largest ever IOS dataset to the best of our knowledge. The experimental results demonstrate that our TSegFormer consistently surpasses existing state-of-the-art baselines. The superiority of TSegFormer is corroborated by extensive analysis, visualizations and real-world clinical applicability tests. Our code is available at https://github.com/huiminxiong/TSegFormer.
Enhancing Uncertainty-Based Hallucination Detection with Stronger Focus
Nov 22, 2023Large Language Models (LLMs) have gained significant popularity for their impressive performance across diverse fields. However, LLMs are prone to hallucinate untruthful or nonsensical outputs that fail to meet user expectations in many real-world applications. Existing works for detecting hallucinations in LLMs either rely on external knowledge for reference retrieval or require sampling multiple responses from the LLM for consistency verification, making these methods costly and inefficient. In this paper, we propose a novel reference-free, uncertainty-based method for detecting hallucinations in LLMs. Our approach imitates human focus in factuality checking from three aspects: 1) focus on the most informative and important keywords in the given text; 2) focus on the unreliable tokens in historical context which may lead to a cascade of hallucinations; and 3) focus on the token properties such as token type and token frequency. Experimental results on relevant datasets demonstrate the effectiveness of our proposed method, which achieves state-of-the-art performance across all the evaluation metrics and eliminates the need for additional information.
GazeForensics: DeepFake Detection via Gaze-guided Spatial Inconsistency Learning
Nov 22, 2023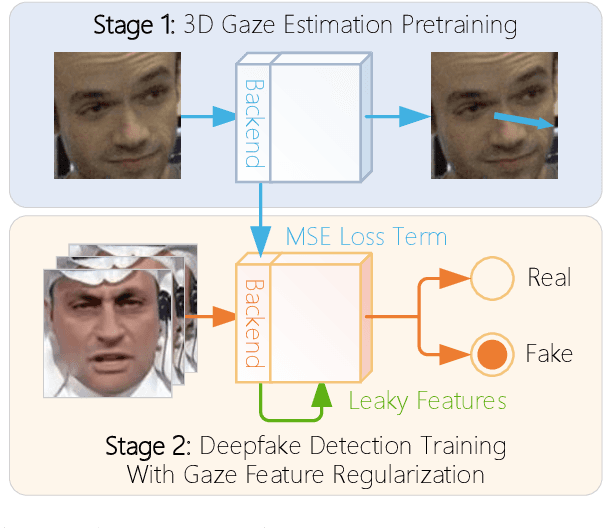
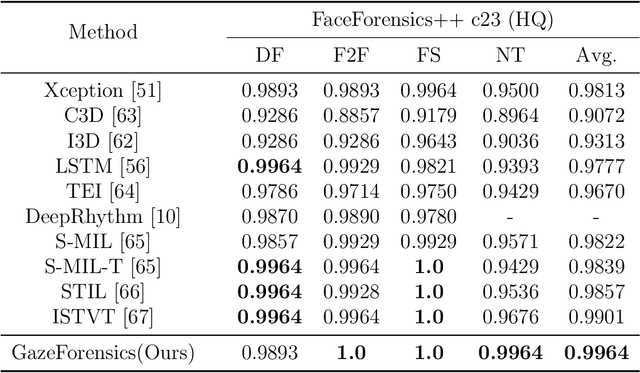
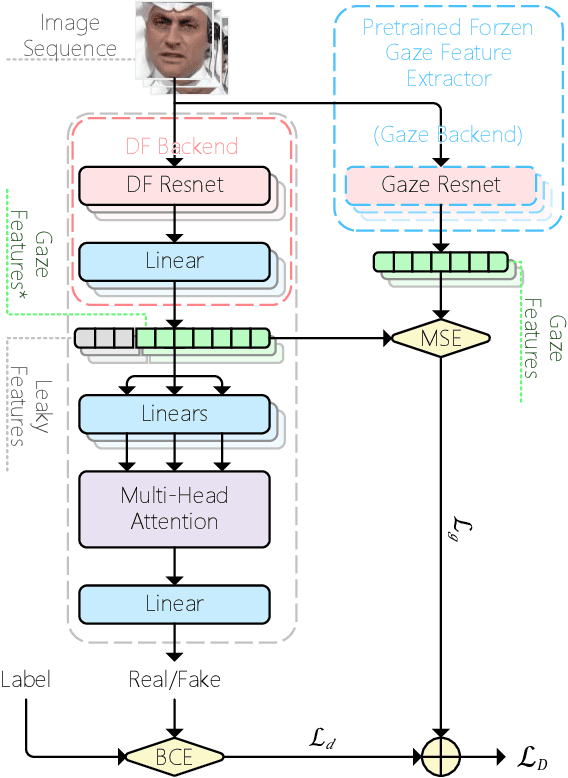
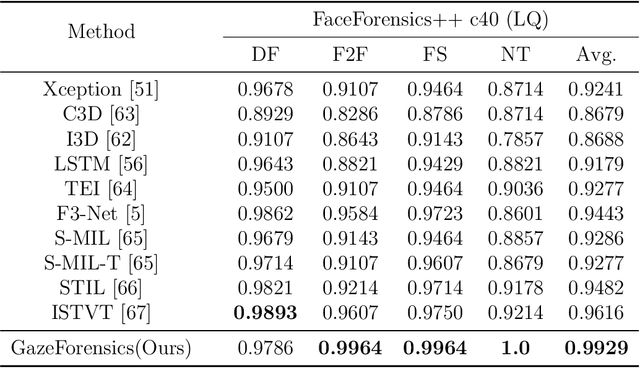
DeepFake detection is pivotal in personal privacy and public safety. With the iterative advancement of DeepFake techniques, high-quality forged videos and images are becoming increasingly deceptive. Prior research has seen numerous attempts by scholars to incorporate biometric features into the field of DeepFake detection. However, traditional biometric-based approaches tend to segregate biometric features from general ones and freeze the biometric feature extractor. These approaches resulted in the exclusion of valuable general features, potentially leading to a performance decline and, consequently, a failure to fully exploit the potential of biometric information in assisting DeepFake detection. Moreover, insufficient attention has been dedicated to scrutinizing gaze authenticity within the realm of DeepFake detection in recent years. In this paper, we introduce GazeForensics, an innovative DeepFake detection method that utilizes gaze representation obtained from a 3D gaze estimation model to regularize the corresponding representation within our DeepFake detection model, while concurrently integrating general features to further enhance the performance of our model. Experiment results reveal that our proposed GazeForensics outperforms the current state-of-the-art methods.
FuseNet: Self-Supervised Dual-Path Network for Medical Image Segmentation
Nov 22, 2023Semantic segmentation, a crucial task in computer vision, often relies on labor-intensive and costly annotated datasets for training. In response to this challenge, we introduce FuseNet, a dual-stream framework for self-supervised semantic segmentation that eliminates the need for manual annotation. FuseNet leverages the shared semantic dependencies between the original and augmented images to create a clustering space, effectively assigning pixels to semantically related clusters, and ultimately generating the segmentation map. Additionally, FuseNet incorporates a cross-modal fusion technique that extends the principles of CLIP by replacing textual data with augmented images. This approach enables the model to learn complex visual representations, enhancing robustness against variations similar to CLIP's text invariance. To further improve edge alignment and spatial consistency between neighboring pixels, we introduce an edge refinement loss. This loss function considers edge information to enhance spatial coherence, facilitating the grouping of nearby pixels with similar visual features. Extensive experiments on skin lesion and lung segmentation datasets demonstrate the effectiveness of our method. \href{https://github.com/xmindflow/FuseNet}{Codebase.}
Neural Network Pruning by Gradient Descent
Nov 22, 2023The rapid increase in the parameters of deep learning models has led to significant costs, challenging computational efficiency and model interpretability. In this paper, we introduce a novel and straightforward neural network pruning framework that incorporates the Gumbel-Softmax technique. This framework enables the simultaneous optimization of a network's weights and topology in an end-to-end process using stochastic gradient descent. Empirical results demonstrate its exceptional compression capability, maintaining high accuracy on the MNIST dataset with only 0.15\% of the original network parameters. Moreover, our framework enhances neural network interpretability, not only by allowing easy extraction of feature importance directly from the pruned network but also by enabling visualization of feature symmetry and the pathways of information propagation from features to outcomes. Although the pruning strategy is learned through deep learning, it is surprisingly intuitive and understandable, focusing on selecting key representative features and exploiting data patterns to achieve extreme sparse pruning. We believe our method opens a promising new avenue for deep learning pruning and the creation of interpretable machine learning systems.
Individualized Dynamic Model for Multi-resolutional Data
Nov 22, 2023Mobile health has emerged as a major success in tracking individual health status, due to the popularity and power of smartphones and wearable devices. This has also brought great challenges in handling heterogeneous, multi-resolution data which arise ubiquitously in mobile health due to irregular multivariate measurements collected from individuals. In this paper, we propose an individualized dynamic latent factor model for irregular multi-resolution time series data to interpolate unsampled measurements of time series with low resolution. One major advantage of the proposed method is the capability to integrate multiple irregular time series and multiple subjects by mapping the multi-resolution data to the latent space. In addition, the proposed individualized dynamic latent factor model is applicable to capturing heterogeneous longitudinal information through individualized dynamic latent factors. In theory, we provide the integrated interpolation error bound of the proposed estimator and derive the convergence rate with B-spline approximation methods. Both the simulation studies and the application to smartwatch data demonstrate the superior performance of the proposed method compared to existing methods.
Provable Representation with Efficient Planning for Partially Observable Reinforcement Learning
Nov 20, 2023In real-world reinforcement learning problems, the state information is often only partially observable, which breaks the basic assumption in Markov decision processes, and thus, leads to inferior performances. Partially Observable Markov Decision Processes have been introduced to explicitly take the issue into account for learning, exploration, and planning, but presenting significant computational and statistical challenges. To address these difficulties, we exploit the representation view, which leads to a coherent design framework for a practically tractable reinforcement learning algorithm upon partial observations. We provide a theoretical analysis for justifying the statistical efficiency of the proposed algorithm. We also empirically demonstrate the proposed algorithm can surpass state-of-the-art performance with partial observations across various benchmarks, therefore, pushing reliable reinforcement learning towards more practical applications.
Vision-Language Integration in Multimodal Video Transformers (Partially) Aligns with the Brain
Nov 13, 2023Integrating information from multiple modalities is arguably one of the essential prerequisites for grounding artificial intelligence systems with an understanding of the real world. Recent advances in video transformers that jointly learn from vision, text, and sound over time have made some progress toward this goal, but the degree to which these models integrate information from modalities still remains unclear. In this work, we present a promising approach for probing a pre-trained multimodal video transformer model by leveraging neuroscientific evidence of multimodal information processing in the brain. Using brain recordings of participants watching a popular TV show, we analyze the effects of multi-modal connections and interactions in a pre-trained multi-modal video transformer on the alignment with uni- and multi-modal brain regions. We find evidence that vision enhances masked prediction performance during language processing, providing support that cross-modal representations in models can benefit individual modalities. However, we don't find evidence of brain-relevant information captured by the joint multi-modal transformer representations beyond that captured by all of the individual modalities. We finally show that the brain alignment of the pre-trained joint representation can be improved by fine-tuning using a task that requires vision-language inferences. Overall, our results paint an optimistic picture of the ability of multi-modal transformers to integrate vision and language in partially brain-relevant ways but also show that improving the brain alignment of these models may require new approaches.
ECRF: Entropy-Constrained Neural Radiance Fields Compression with Frequency Domain Optimization
Nov 23, 2023Explicit feature-grid based NeRF models have shown promising results in terms of rendering quality and significant speed-up in training. However, these methods often require a significant amount of data to represent a single scene or object. In this work, we present a compression model that aims to minimize the entropy in the frequency domain in order to effectively reduce the data size. First, we propose using the discrete cosine transform (DCT) on the tensorial radiance fields to compress the feature-grid. This feature-grid is transformed into coefficients, which are then quantized and entropy encoded, following a similar approach to the traditional video coding pipeline. Furthermore, to achieve a higher level of sparsity, we propose using an entropy parameterization technique for the frequency domain, specifically for DCT coefficients of the feature-grid. Since the transformed coefficients are optimized during the training phase, the proposed model does not require any fine-tuning or additional information. Our model only requires a lightweight compression pipeline for encoding and decoding, making it easier to apply volumetric radiance field methods for real-world applications. Experimental results demonstrate that our proposed frequency domain entropy model can achieve superior compression performance across various datasets. The source code will be made publicly available.