 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024
The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
Second-Order Information Matters: Revisiting Machine Unlearning for Large Language Models
Mar 13, 2024
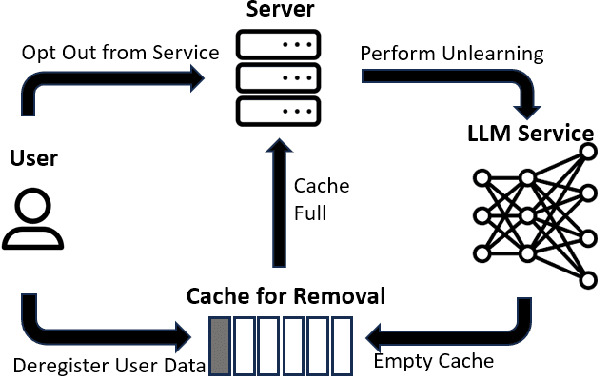
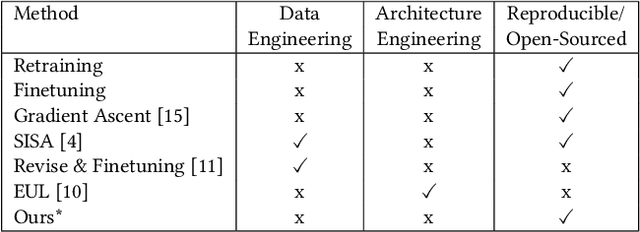
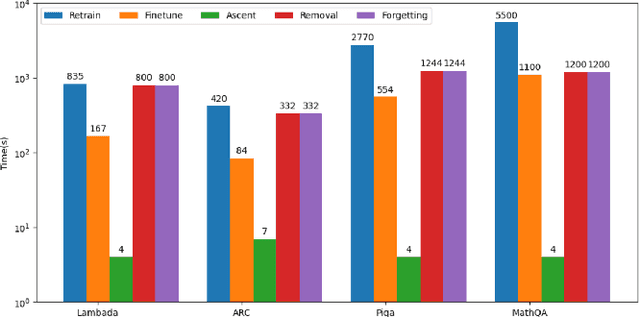
With the rapid development of Large Language Models (LLMs), we have witnessed intense competition among the major LLM products like ChatGPT, LLaMa, and Gemini. However, various issues (e.g. privacy leakage and copyright violation) of the training corpus still remain underexplored. For example, the Times sued OpenAI and Microsoft for infringing on its copyrights by using millions of its articles for training. From the perspective of LLM practitioners, handling such unintended privacy violations can be challenging. Previous work addressed the ``unlearning" problem of LLMs using gradient information, while they mostly introduced significant overheads like data preprocessing or lacked robustness. In this paper, contrasting with the methods based on first-order information, we revisit the unlearning problem via the perspective of second-order information (Hessian). Our unlearning algorithms, which are inspired by classic Newton update, are not only data-agnostic/model-agnostic but also proven to be robust in terms of utility preservation or privacy guarantee. Through a comprehensive evaluation with four NLP datasets as well as a case study on real-world datasets, our methods consistently show superiority over the first-order methods.
2D Ego-Motion with Yaw Estimation using Only mmWave Radars via Two-Way weighted ICP
Mar 31, 2024The interest in single-chip mmWave Radar is driven by their compact form factor, cost-effectiveness, and robustness under harsh environmental conditions. Despite its promising attributes, the principal limitation of mmWave radar lies in its capacity for autonomous yaw rate estimation. Conventional solutions have often resorted to integrating inertial measurement unit (IMU) or deploying multiple radar units to circumvent this shortcoming. This paper introduces an innovative methodology for two-dimensional ego-motion estimation, focusing on yaw rate deduction, utilizing solely mmWave radar sensors. By applying a weighted Iterated Closest Point (ICP) algorithm to register processed points derived from heatmap data, our method facilitates 2D ego-motion estimation devoid of prior information. Through experimental validation, we verified the effectiveness and promise of our technique for ego-motion estimation using exclusively radar data.
MaGRITTe: Manipulative and Generative 3D Realization from Image, Topview and Text
Mar 30, 2024The generation of 3D scenes from user-specified conditions offers a promising avenue for alleviating the production burden in 3D applications. Previous studies required significant effort to realize the desired scene, owing to limited control conditions. We propose a method for controlling and generating 3D scenes under multimodal conditions using partial images, layout information represented in the top view, and text prompts. Combining these conditions to generate a 3D scene involves the following significant difficulties: (1) the creation of large datasets, (2) reflection on the interaction of multimodal conditions, and (3) domain dependence of the layout conditions. We decompose the process of 3D scene generation into 2D image generation from the given conditions and 3D scene generation from 2D images. 2D image generation is achieved by fine-tuning a pretrained text-to-image model with a small artificial dataset of partial images and layouts, and 3D scene generation is achieved by layout-conditioned depth estimation and neural radiance fields (NeRF), thereby avoiding the creation of large datasets. The use of a common representation of spatial information using 360-degree images allows for the consideration of multimodal condition interactions and reduces the domain dependence of the layout control. The experimental results qualitatively and quantitatively demonstrated that the proposed method can generate 3D scenes in diverse domains, from indoor to outdoor, according to multimodal conditions.
Dependability Evaluation of Stable Diffusion with Soft Errors on the Model Parameters
Mar 30, 2024Stable Diffusion is a popular Transformer-based model for image generation from text; it applies an image information creator to the input text and the visual knowledge is added in a step-by-step fashion to create an image that corresponds to the input text. However, this diffusion process can be corrupted by errors from the underlying hardware, which are especially relevant for implementations at the nanoscales. In this paper, the dependability of Stable Diffusion is studied focusing on soft errors in the memory that stores the model parameters; specifically, errors are injected into some critical layers of the Transformer in different blocks of the image information creator, to evaluate their impact on model performance. The simulations results reveal several conclusions: 1) errors on the down blocks of the creator have a larger impact on the quality of the generated images than those on the up blocks, while the errors on middle block have negligible effect; 2) errors on the self-attention (SA) layers have larger impact on the results than those on the cross-attention (CA) layers; 3) for CA layers, errors on deeper levels result in a larger impact; 4) errors on blocks at the first levels tend to introduce noise in the image, and those on deep layers tend to introduce large colored blocks. These results provide an initial understanding of the impact of errors on Stable Diffusion.
Logits of API-Protected LLMs Leak Proprietary Information
Mar 15, 2024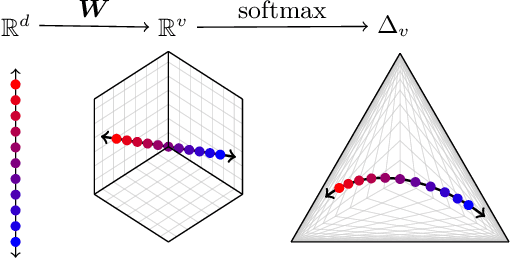

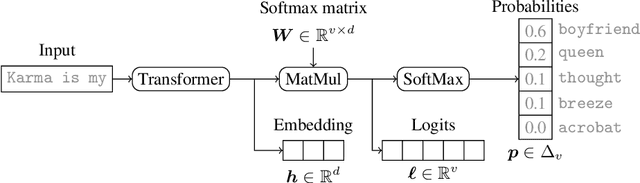

The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption about the model architecture, it is possible to learn a surprisingly large amount of non-public information about an API-protected LLM from a relatively small number of API queries (e.g., costing under $1,000 for OpenAI's gpt-3.5-turbo). Our findings are centered on one key observation: most modern LLMs suffer from a softmax bottleneck, which restricts the model outputs to a linear subspace of the full output space. We show that this lends itself to a model image or a model signature which unlocks several capabilities with affordable cost: efficiently discovering the LLM's hidden size, obtaining full-vocabulary outputs, detecting and disambiguating different model updates, identifying the source LLM given a single full LLM output, and even estimating the output layer parameters. Our empirical investigations show the effectiveness of our methods, which allow us to estimate the embedding size of OpenAI's gpt-3.5-turbo to be about 4,096. Lastly, we discuss ways that LLM providers can guard against these attacks, as well as how these capabilities can be viewed as a feature (rather than a bug) by allowing for greater transparency and accountability.
TWIN-GPT: Digital Twins for Clinical Trials via Large Language Model
Apr 01, 2024Recently, there has been a burgeoning interest in virtual clinical trials, which simulate real-world scenarios and hold the potential to significantly enhance patient safety, expedite development, reduce costs, and contribute to the broader scientific knowledge in healthcare. Existing research often focuses on leveraging electronic health records (EHRs) to support clinical trial outcome prediction. Yet, trained with limited clinical trial outcome data, existing approaches frequently struggle to perform accurate predictions. Some research has attempted to generate EHRs to augment model development but has fallen short in personalizing the generation for individual patient profiles. Recently, the emergence of large language models has illuminated new possibilities, as their embedded comprehensive clinical knowledge has proven beneficial in addressing medical issues. In this paper, we propose a large language model-based digital twin creation approach, called TWIN-GPT. TWIN-GPT can establish cross-dataset associations of medical information given limited data, generating unique personalized digital twins for different patients, thereby preserving individual patient characteristics. Comprehensive experiments show that using digital twins created by TWIN-GPT can boost clinical trial outcome prediction, exceeding various previous prediction approaches. Besides, we also demonstrate that TWIN-GPT can generate high-fidelity trial data that closely approximate specific patients, aiding in more accurate result predictions in data-scarce situations. Moreover, our study provides practical evidence for the application of digital twins in healthcare, highlighting its potential significance.
TryOn-Adapter: Efficient Fine-Grained Clothing Identity Adaptation for High-Fidelity Virtual Try-On
Apr 01, 2024Virtual try-on focuses on adjusting the given clothes to fit a specific person seamlessly while avoiding any distortion of the patterns and textures of the garment. However, the clothing identity uncontrollability and training inefficiency of existing diffusion-based methods, which struggle to maintain the identity even with full parameter training, are significant limitations that hinder the widespread applications. In this work, we propose an effective and efficient framework, termed TryOn-Adapter. Specifically, we first decouple clothing identity into fine-grained factors: style for color and category information, texture for high-frequency details, and structure for smooth spatial adaptive transformation. Our approach utilizes a pre-trained exemplar-based diffusion model as the fundamental network, whose parameters are frozen except for the attention layers. We then customize three lightweight modules (Style Preserving, Texture Highlighting, and Structure Adapting) incorporated with fine-tuning techniques to enable precise and efficient identity control. Meanwhile, we introduce the training-free T-RePaint strategy to further enhance clothing identity preservation while maintaining the realistic try-on effect during the inference. Our experiments demonstrate that our approach achieves state-of-the-art performance on two widely-used benchmarks. Additionally, compared with recent full-tuning diffusion-based methods, we only use about half of their tunable parameters during training. The code will be made publicly available at https://github.com/jiazheng-xing/TryOn-Adapter.
LITE: Modeling Environmental Ecosystems with Multimodal Large Language Models
Apr 01, 2024The modeling of environmental ecosystems plays a pivotal role in the sustainable management of our planet. Accurate prediction of key environmental variables over space and time can aid in informed policy and decision-making, thus improving people's livelihood. Recently, deep learning-based methods have shown promise in modeling the spatial-temporal relationships for predicting environmental variables. However, these approaches often fall short in handling incomplete features and distribution shifts, which are commonly observed in environmental data due to the substantial cost of data collection and malfunctions in measuring instruments. To address these issues, we propose LITE -- a multimodal large language model for environmental ecosystems modeling. Specifically, LITE unifies different environmental variables by transforming them into natural language descriptions and line graph images. Then, LITE utilizes unified encoders to capture spatial-temporal dynamics and correlations in different modalities. During this step, the incomplete features are imputed by a sparse Mixture-of-Experts framework, and the distribution shift is handled by incorporating multi-granularity information from past observations. Finally, guided by domain instructions, a language model is employed to fuse the multimodal representations for the prediction. Our experiments demonstrate that LITE significantly enhances performance in environmental spatial-temporal prediction across different domains compared to the best baseline, with a 41.25% reduction in prediction error. This justifies its effectiveness. Our data and code are available at https://github.com/hrlics/LITE.
Enhancing Reasoning Capacity of SLM using Cognitive Enhancement
Apr 01, 2024Large Language Models (LLMs) have been applied to automate cyber security activities and processes including cyber investigation and digital forensics. However, the use of such models for cyber investigation and digital forensics should address accountability and security considerations. Accountability ensures models have the means to provide explainable reasonings and outcomes. This information can be extracted through explicit prompt requests. For security considerations, it is crucial to address privacy and confidentiality of the involved data during data processing as well. One approach to deal with this consideration is to have the data processed locally using a local instance of the model. Due to limitations of locally available resources, namely memory and GPU capacities, a Smaller Large Language Model (SLM) will typically be used. These SLMs have significantly fewer parameters compared to the LLMs. However, such size reductions have notable performance reduction, especially when tasked to provide reasoning explanations. In this paper, we aim to mitigate performance reduction through the integration of cognitive strategies that humans use for problem-solving. We term this as cognitive enhancement through prompts. Our experiments showed significant improvement gains of the SLMs' performances when such enhancements were applied. We believe that our exploration study paves the way for further investigation into the use of cognitive enhancement to optimize SLM for cyber security applications.