 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision
Nov 14, 2023
Large multimodal models (LMMs) suffer from multimodal hallucination, where they provide incorrect responses misaligned with the given visual information. Recent works have conjectured that one of the reasons behind multimodal hallucination might be due to the vision encoder failing to ground on the image properly. To mitigate this issue, we propose a novel approach that leverages self-feedback as visual cues. Building on this approach, we introduce Volcano, a multimodal self-feedback guided revision model. Volcano generates natural language feedback to its initial response based on the provided visual information and utilizes this feedback to self-revise its initial response. Volcano effectively reduces multimodal hallucination and achieves state-of-the-art on MMHal-Bench, POPE, and GAVIE. It also improves on general multimodal abilities and outperforms previous models on MM-Vet and MMBench. Through a qualitative analysis, we show that Volcano's feedback is properly grounded on the image than the initial response. This indicates that Volcano can provide itself with richer visual information, helping alleviate multimodal hallucination. We publicly release Volcano models of 7B and 13B sizes along with the data and code at https://github.com/kaistAI/Volcano.
Collaborative Word-based Pre-trained Item Representation for Transferable Recommendation
Nov 17, 2023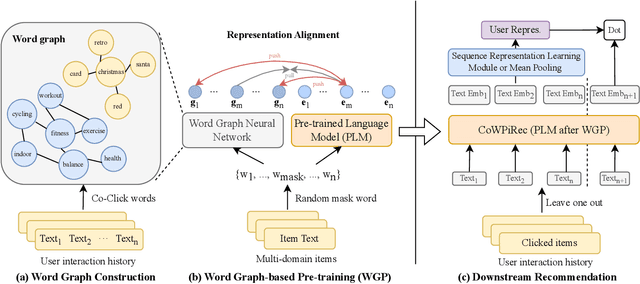
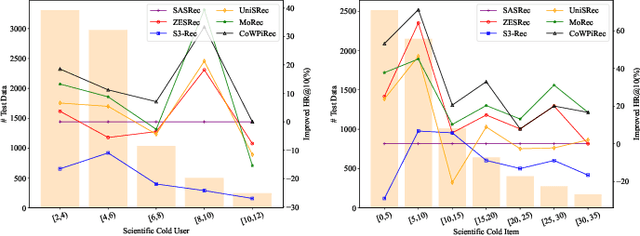
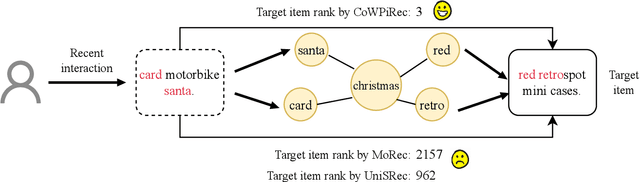
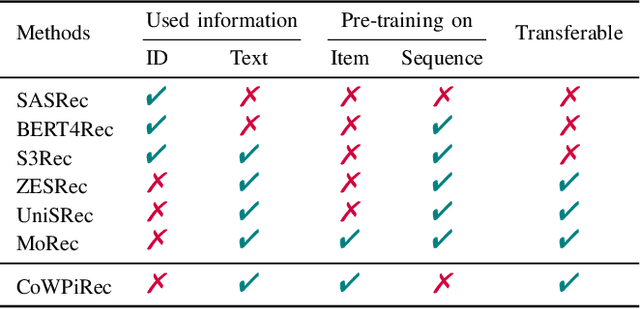
Item representation learning (IRL) plays an essential role in recommender systems, especially for sequential recommendation. Traditional sequential recommendation models usually utilize ID embeddings to represent items, which are not shared across different domains and lack the transferable ability. Recent studies use pre-trained language models (PLM) for item text embeddings (text-based IRL) that are universally applicable across domains. However, the existing text-based IRL is unaware of the important collaborative filtering (CF) information. In this paper, we propose CoWPiRec, an approach of Collaborative Word-based Pre-trained item representation for Recommendation. To effectively incorporate CF information into text-based IRL, we convert the item-level interaction data to a word graph containing word-level collaborations. Subsequently, we design a novel pre-training task to align the word-level semantic- and CF-related item representation. Extensive experimental results on multiple public datasets demonstrate that compared to state-of-the-art transferable sequential recommenders, CoWPiRec achieves significantly better performances in both fine-tuning and zero-shot settings for cross-scenario recommendation and effectively alleviates the cold-start issue. The code is available at: https://github.com/ysh-1998/CoWPiRec.
Collaborative Grid Mapping for Moving Object Tracking Evaluation
Nov 17, 2023Perception of other road users is a crucial task for intelligent vehicles. Perception systems can use on-board sensors only or be in cooperation with other vehicles or with roadside units. In any case, the performance of perception systems has to be evaluated against ground-truth data, which is a particularly tedious task and requires numerous manual operations. In this article, we propose a novel semi-automatic method for pseudo ground-truth estimation. The principle consists in carrying out experiments with several vehicles equipped with LiDAR sensors and with fixed perception systems located at the roadside in order to collaboratively build reference dynamic data. The method is based on grid mapping and in particular on the elaboration of a background map that holds relevant information that remains valid during a whole dataset sequence. Data from all agents is converted in time-stamped observations grids. A data fusion method that manages uncertainties combines the background map with observations to produce dynamic reference information at each instant. Several datasets have been acquired with three experimental vehicles and a roadside unit. An evaluation of this method is finally provided in comparison to a handmade ground truth.
Community-Aware Efficient Graph Contrastive Learning via Personalized Self-Training
Nov 18, 2023In recent years, graph contrastive learning (GCL) has emerged as one of the optimal solutions for various supervised tasks at the node level. However, for unsupervised and structure-related tasks such as community detection, current GCL algorithms face difficulties in acquiring the necessary community-level information, resulting in poor performance. In addition, general contrastive learning algorithms improve the performance of downstream tasks by increasing the number of negative samples, which leads to severe class collision and unfairness of community detection. To address above issues, we propose a novel Community-aware Efficient Graph Contrastive Learning Framework (CEGCL) to jointly learn community partition and node representations in an end-to-end manner. Specifically, we first design a personalized self-training (PeST) strategy for unsupervised scenarios, which enables our model to capture precise community-level personalized information in a graph. With the benefit of the PeST, we alleviate class collision and unfairness without sacrificing the overall model performance. Furthermore, the aligned graph clustering (AlGC) is employed to obtain the community partition. In this module, we align the clustering space of our downstream task with that in PeST to achieve more consistent node embeddings. Finally, we demonstrate the effectiveness of our model for community detection both theoretically and experimentally. Extensive experimental results also show that our CEGCL exhibits state-of-the-art performance on three benchmark datasets with different scales.
VaSAB: The variable size adaptive information bottleneck for disentanglement on speech and singing voice
Oct 05, 2023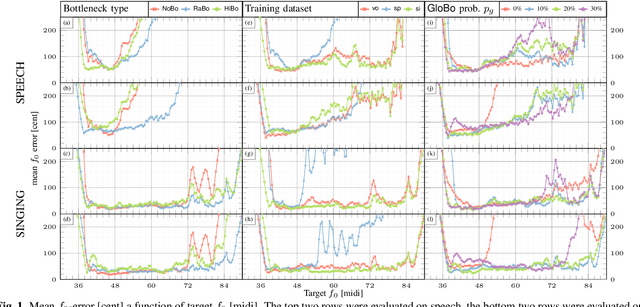
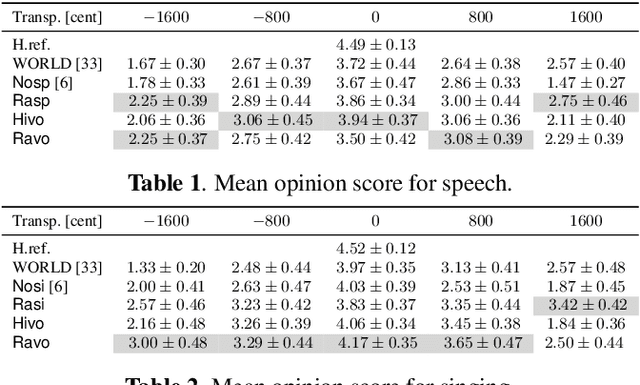
The information bottleneck auto-encoder is a tool for disentanglement commonly used for voice transformation. The successful disentanglement relies on the right choice of bottleneck size. Previous bottleneck auto-encoders created the bottleneck by the dimension of the latent space or through vector quantization and had no means to change the bottleneck size of a specific model. As the bottleneck removes information from the disentangled representation, the choice of bottleneck size is a trade-off between disentanglement and synthesis quality. We propose to build the information bottleneck using dropout which allows us to change the bottleneck through the dropout rate and investigate adapting the bottleneck size depending on the context. We experimentally explore into using the adaptive bottleneck for pitch transformation and demonstrate that the adaptive bottleneck leads to improved disentanglement of the F0 parameter for both, speech and singing voice leading to improved synthesis quality. Using the variable bottleneck size, we were able to achieve disentanglement for singing voice including extremely high pitches and create a universal voice model, that works on both speech and singing voice with improved synthesis quality.
I2SRM: Intra- and Inter-Sample Relationship Modeling for Multimodal Information Extraction
Oct 10, 2023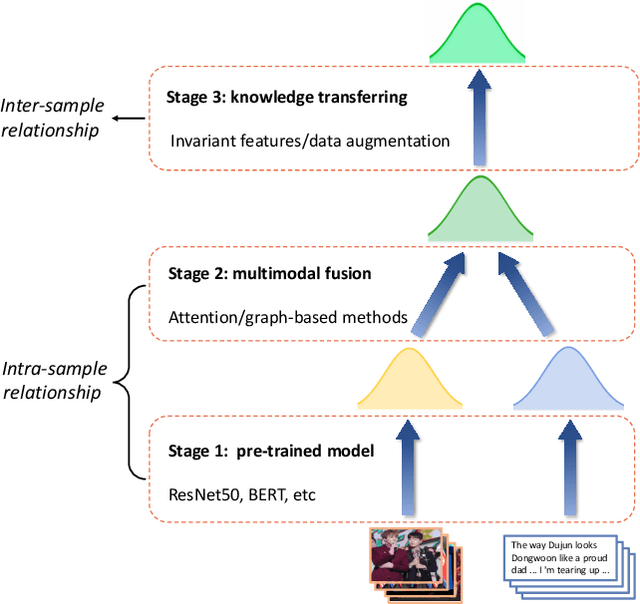
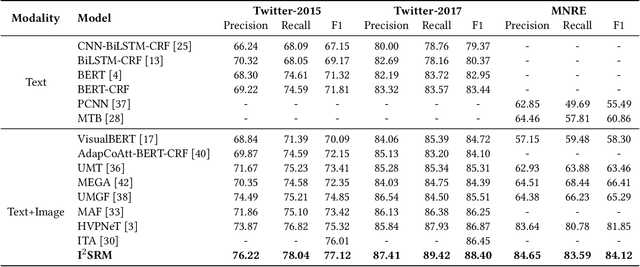
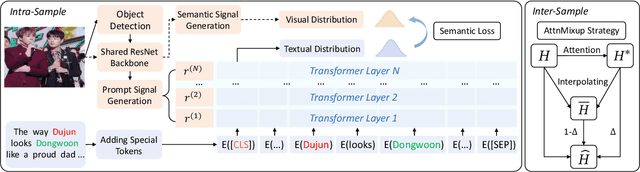
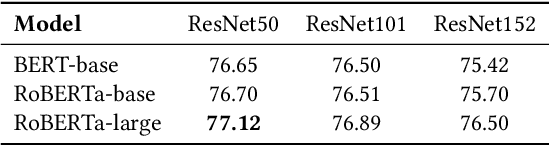
Multimodal information extraction is attracting research attention nowadays, which requires aggregating representations from different modalities. In this paper, we present the Intra- and Inter-Sample Relationship Modeling (I2SRM) method for this task, which contains two modules. Firstly, the intra-sample relationship modeling module operates on a single sample and aims to learn effective representations. Embeddings from textual and visual modalities are shifted to bridge the modality gap caused by distinct pre-trained language and image models. Secondly, the inter-sample relationship modeling module considers relationships among multiple samples and focuses on capturing the interactions. An AttnMixup strategy is proposed, which not only enables collaboration among samples but also augments data to improve generalization. We conduct extensive experiments on the multimodal named entity recognition datasets Twitter-2015 and Twitter-2017, and the multimodal relation extraction dataset MNRE. Our proposed method I2SRM achieves competitive results, 77.12% F1-score on Twitter-2015, 88.40% F1-score on Twitter-2017, and 84.12% F1-score on MNRE.
Large Language Models as Topological Structure Enhancers for Text-Attributed Graphs
Nov 24, 2023The latest advancements in large language models (LLMs) have revolutionized the field of natural language processing (NLP). Inspired by the success of LLMs in NLP tasks, some recent work has begun investigating the potential of applying LLMs in graph learning tasks. However, most of the existing work focuses on utilizing LLMs as powerful node feature augmenters, leaving employing LLMs to enhance graph topological structures an understudied problem. In this work, we explore how to leverage the information retrieval and text generation capabilities of LLMs to refine/enhance the topological structure of text-attributed graphs (TAGs) under the node classification setting. First, we propose using LLMs to help remove unreliable edges and add reliable ones in the TAG. Specifically, we first let the LLM output the semantic similarity between node attributes through delicate prompt designs, and then perform edge deletion and edge addition based on the similarity. Second, we propose using pseudo-labels generated by the LLM to improve graph topology, that is, we introduce the pseudo-label propagation as a regularization to guide the graph neural network (GNN) in learning proper edge weights. Finally, we incorporate the two aforementioned LLM-based methods for graph topological refinement into the process of GNN training, and perform extensive experiments on four real-world datasets. The experimental results demonstrate the effectiveness of LLM-based graph topology refinement (achieving a 0.15%--2.47% performance gain on public benchmarks).
FIKIT: Priority-Based Real-time GPU Multi-tasking Scheduling with Kernel Identification
Nov 24, 2023Highly parallelized workloads like machine learning training, inferences and general HPC tasks are greatly accelerated using GPU devices. In a cloud computing cluster, serving a GPU's computation power through multi-tasks sharing is highly demanded since there are always more task requests than the number of GPU available. Existing GPU sharing solutions focus on reducing task-level waiting time or task-level switching costs when multiple jobs competing for a single GPU. Non-stopped computation requests come with different priorities, having non-symmetric impact on QoS for sharing a GPU device. Existing work missed the kernel-level optimization opportunity brought by this setting. To address this problem, we present a novel kernel-level scheduling strategy called FIKIT: Filling Inter-kernel Idle Time. FIKIT incorporates task-level priority information, fine-grained kernel identification, and kernel measurement, allowing low priorities task's execution during high priority task's inter-kernel idle time. Thereby, filling the GPU's device runtime fully, and reduce overall GPU sharing impact to cloud services. Across a set of ML models, the FIKIT based inference system accelerated high priority tasks by 1.33 to 14.87 times compared to the JCT in GPU sharing mode, and more than half of the cases are accelerated by more than 3.5 times. Alternatively, under preemptive sharing, the low-priority tasks have a comparable to default GPU sharing mode JCT, with a 0.84 to 1 times ratio. We further limit the kernel measurement and runtime fine-grained kernel scheduling overhead to less than 10%.
BenthIQ: a Transformer-Based Benthic Classification Model for Coral Restoration
Nov 22, 2023Coral reefs are vital for marine biodiversity, coastal protection, and supporting human livelihoods globally. However, they are increasingly threatened by mass bleaching events, pollution, and unsustainable practices with the advent of climate change. Monitoring the health of these ecosystems is crucial for effective restoration and management. Current methods for creating benthic composition maps often compromise between spatial coverage and resolution. In this paper, we introduce BenthIQ, a multi-label semantic segmentation network designed for high-precision classification of underwater substrates, including live coral, algae, rock, and sand. Although commonly deployed CNNs are limited in learning long-range semantic information, transformer-based models have recently achieved state-of-the-art performance in vision tasks such as object detection and image classification. We integrate the hierarchical Swin Transformer as the backbone of a U-shaped encoder-decoder architecture for local-global semantic feature learning. Using a real-world case study in French Polynesia, we demonstrate that our approach outperforms traditional CNN and attention-based models on pixel-wise classification of shallow reef imagery.
Grad-Shafranov equilibria via data-free physics informed neural networks
Nov 22, 2023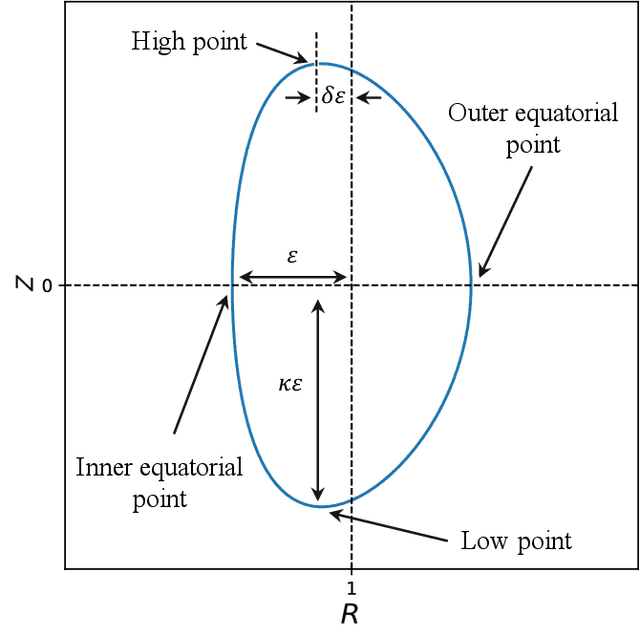
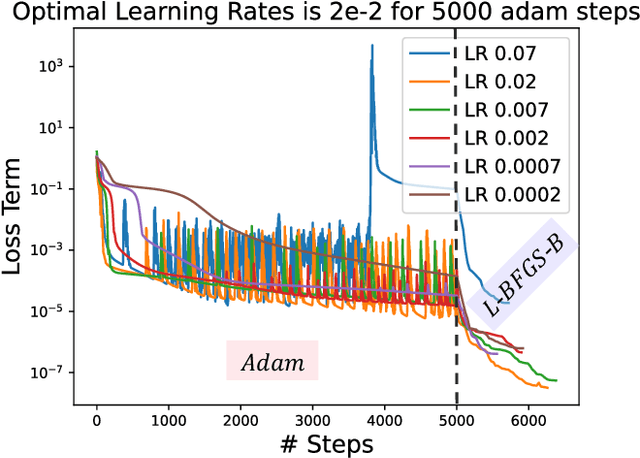
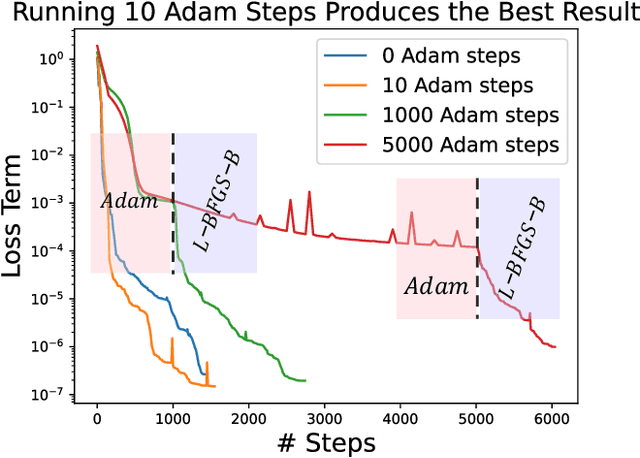
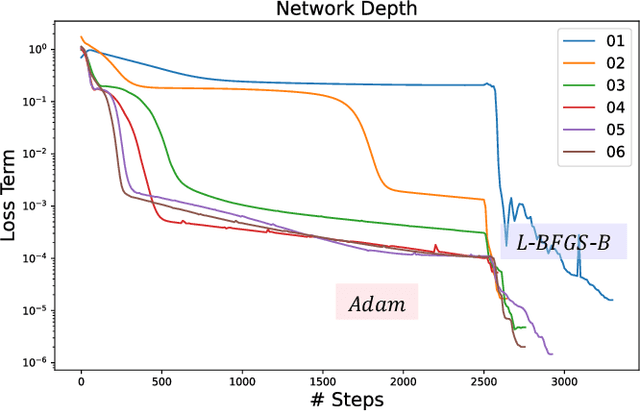
A large number of magnetohydrodynamic (MHD) equilibrium calculations are often required for uncertainty quantification, optimization, and real-time diagnostic information, making MHD equilibrium codes vital to the field of plasma physics. In this paper, we explore a method for solving the Grad-Shafranov equation by using Physics-Informed Neural Networks (PINNs). For PINNs, we optimize neural networks by directly minimizing the residual of the PDE as a loss function. We show that PINNs can accurately and effectively solve the Grad-Shafranov equation with several different boundary conditions. We also explore the parameter space by varying the size of the model, the learning rate, and boundary conditions to map various trade-offs such as between reconstruction error and computational speed. Additionally, we introduce a parameterized PINN framework, expanding the input space to include variables such as pressure, aspect ratio, elongation, and triangularity in order to handle a broader range of plasma scenarios within a single network. Parametrized PINNs could be used in future work to solve inverse problems such as shape optimization.