 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Molecular Identification and Peak Assignment: Leveraging Multi-Level Multimodal Alignment on NMR
Nov 23, 2023
Nuclear magnetic resonance (NMR) spectroscopy plays an essential role across various scientific disciplines, providing valuable insights into molecular dynamics and interactions. Despite the promise of AI-enhanced NMR prediction models, challenges persist in the interpretation of spectra for tasks such as molecular retrieval, isomer recognition, and peak assignment. In response, this paper introduces Multi-Level Multimodal Alignment with Knowledge-Guided Instance-Wise Discrimination (K-M3AID) to establish meaningful correspondences between two heterogeneous modalities: molecular graphs (structures) and NMR spectra. In particular, K-M3AID employs a dual-coordinated contrastive learning architecture, and incorporates a graph-level alignment module, a node-level alignment module, and a communication channel. Notably, the framework introduces knowledge-guided instance-wise discrimination into contrastive learning within the node-level alignment module, significantly enhancing accuracy in cross-modal alignment. Additionally, K-M3AID showcases its capability of meta-learning by demonstrating that skills acquired during node-level alignment positively impact graph-level alignment. Empirical validation underscores K-M3AID's effectiveness in addressing multiple zero-shot tasks, offering a promising solution to bridge the gap between structural information and spectral data in complex NMR scenarios.
Multi-modal In-Context Learning Makes an Ego-evolving Scene Text Recognizer
Nov 23, 2023Scene text recognition (STR) in the wild frequently encounters challenges when coping with domain variations, font diversity, shape deformations, etc. A straightforward solution is performing model fine-tuning tailored to a specific scenario, but it is computationally intensive and requires multiple model copies for various scenarios. Recent studies indicate that large language models (LLMs) can learn from a few demonstration examples in a training-free manner, termed "In-Context Learning" (ICL). Nevertheless, applying LLMs as a text recognizer is unacceptably resource-consuming. Moreover, our pilot experiments on LLMs show that ICL fails in STR, mainly attributed to the insufficient incorporation of contextual information from diverse samples in the training stage. To this end, we introduce E$^2$STR, a STR model trained with context-rich scene text sequences, where the sequences are generated via our proposed in-context training strategy. E$^2$STR demonstrates that a regular-sized model is sufficient to achieve effective ICL capabilities in STR. Extensive experiments show that E$^2$STR exhibits remarkable training-free adaptation in various scenarios and outperforms even the fine-tuned state-of-the-art approaches on public benchmarks.
Sparsity-Driven EEG Channel Selection for Brain-Assisted Speech Enhancement
Nov 23, 2023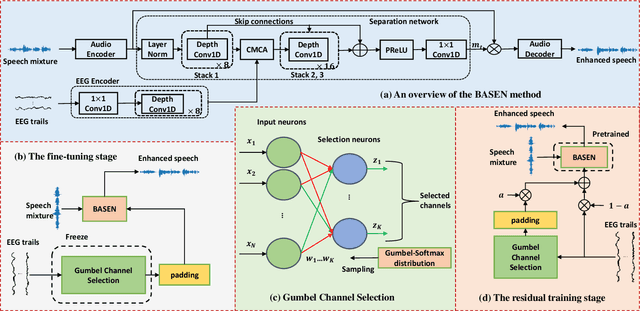
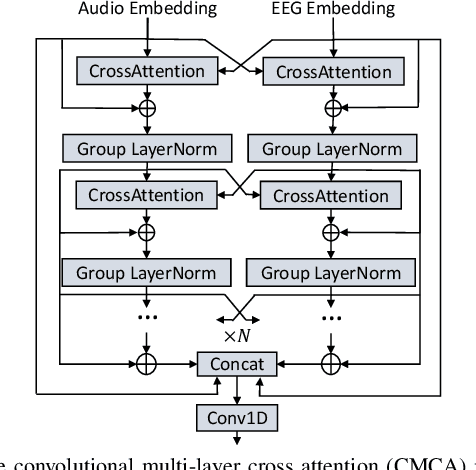
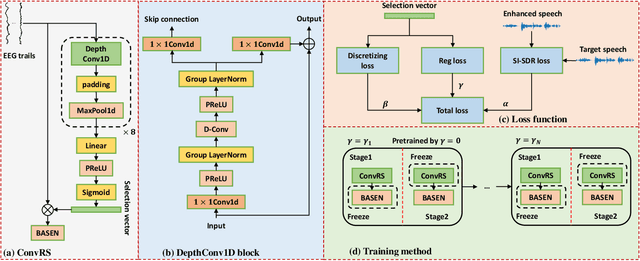
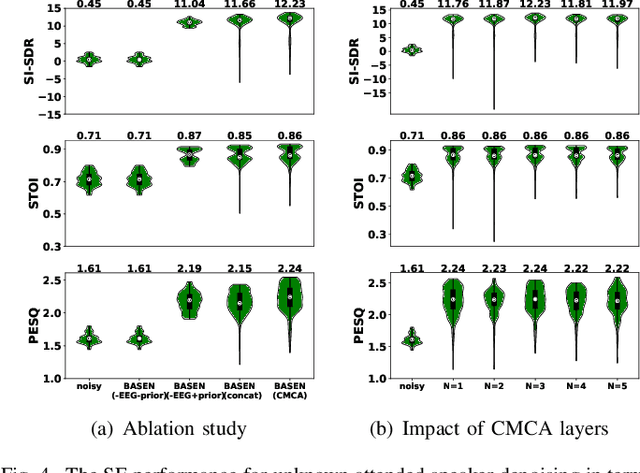
Speech enhancement is widely used as a front-end to improve the speech quality in many audio systems, while it is still hard to extract the target speech in multi-talker conditions without prior information on the speaker identity. It was shown by auditory attention decoding that the attended speaker can be revealed by the electroencephalogram (EEG) of the listener implicitly. In this work, we therefore propose a novel end-to-end brain-assisted speech enhancement network (BASEN), which incorporates the listeners' EEG signals and adopts a temporal convolutional network together with a convolutional multi-layer cross attention module to fuse EEG-audio features. Considering that an EEG cap with sparse channels exhibits multiple benefits and in practice many electrodes might contribute marginally, we further propose two channel selection methods, called residual Gumbel selection and convolutional regularization selection. They are dedicated to tackling the issues of training instability and duplicated channel selections, respectively. Experimental results on a public dataset show the superiority of the proposed baseline BASEN over existing approaches. The proposed channel selection methods can significantly reduce the amount of informative EEG channels with a negligible impact on the performance.
Fair Text Classification with Wasserstein Independence
Nov 21, 2023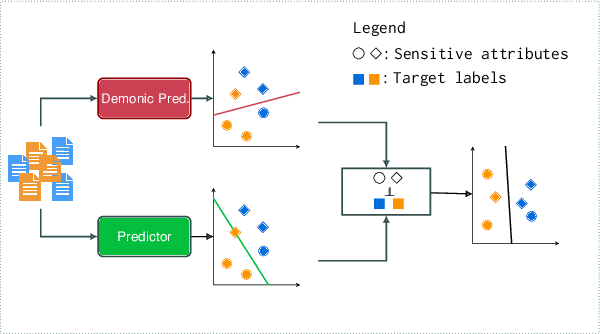
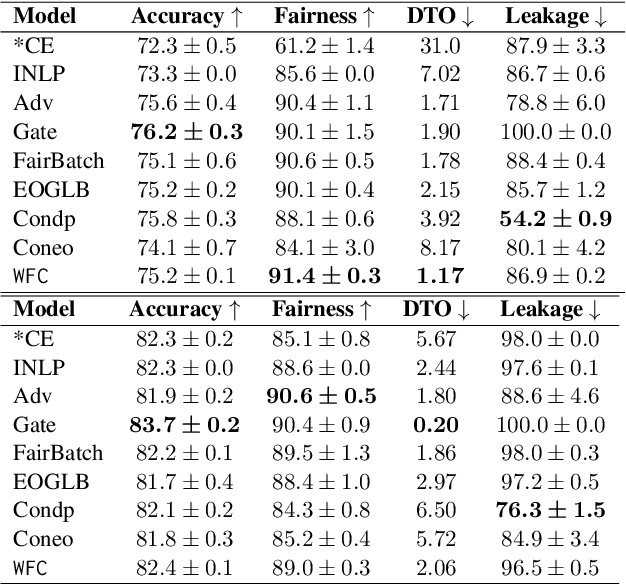
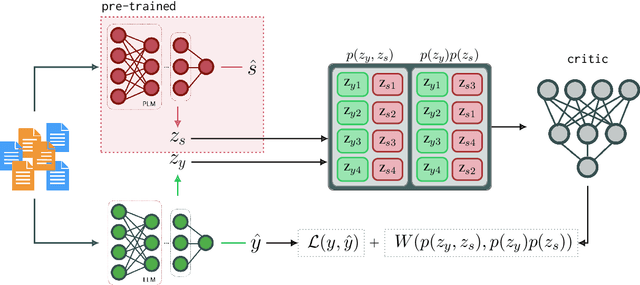
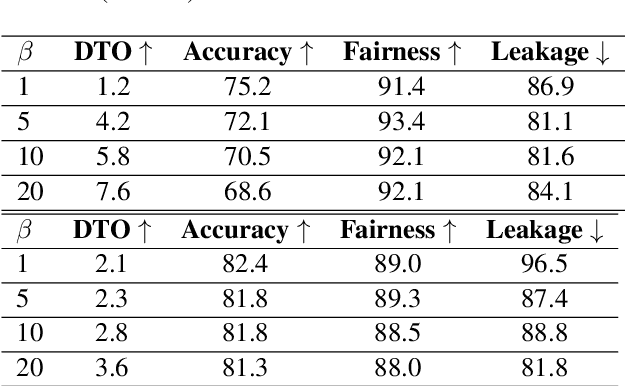
Group fairness is a central research topic in text classification, where reaching fair treatment between sensitive groups (e.g. women vs. men) remains an open challenge. This paper presents a novel method for mitigating biases in neural text classification, agnostic to the model architecture. Considering the difficulty to distinguish fair from unfair information in a text encoder, we take inspiration from adversarial training to induce Wasserstein independence between representations learned to predict our target label and the ones learned to predict some sensitive attribute. Our approach provides two significant advantages. Firstly, it does not require annotations of sensitive attributes in both testing and training data. This is more suitable for real-life scenarios compared to existing methods that require annotations of sensitive attributes at train time. Second, our approach exhibits a comparable or better fairness-accuracy trade-off compared to existing methods.
Instance-aware 3D Semantic Segmentation powered by Shape Generators and Classifiers
Nov 21, 2023Existing 3D semantic segmentation methods rely on point-wise or voxel-wise feature descriptors to output segmentation predictions. However, these descriptors are often supervised at point or voxel level, leading to segmentation models that can behave poorly at instance-level. In this paper, we proposed a novel instance-aware approach for 3D semantic segmentation. Our method combines several geometry processing tasks supervised at instance-level to promote the consistency of the learned feature representation. Specifically, our methods use shape generators and shape classifiers to perform shape reconstruction and classification tasks for each shape instance. This enforces the feature representation to faithfully encode both structural and local shape information, with an awareness of shape instances. In the experiments, our method significantly outperform existing approaches in 3D semantic segmentation on several public benchmarks, such as Waymo Open Dataset, SemanticKITTI and ScanNetV2.
AI for Agriculture: the Comparison of Semantic Segmentation Methods for Crop Mapping with Sentinel-2 Imagery
Nov 21, 2023Crop mapping is one of the most common tasks in artificial intelligence for agriculture due to higher food demands from a growing population and increased awareness of climate change. In case of vineyards, the texture is very important for crop segmentation: with higher resolution satellite imagery the texture is easily detected by majority of state-of-the-art algorithms. However, this task becomes increasingly more difficult as the resolution of satellite imagery decreases and the information about the texture becomes unavailable. In this paper we aim to explore the main machine learning methods that can be used with freely available satellite imagery and discuss how and when they can be applied for vineyard segmentation problem. We assess the effectiveness of various widely-used machine learning techniques and offer guidance on selecting the most suitable model for specific scenarios.
MPCNN: A Novel Matrix Profile Approach for CNN-based Sleep Apnea Classification
Nov 25, 2023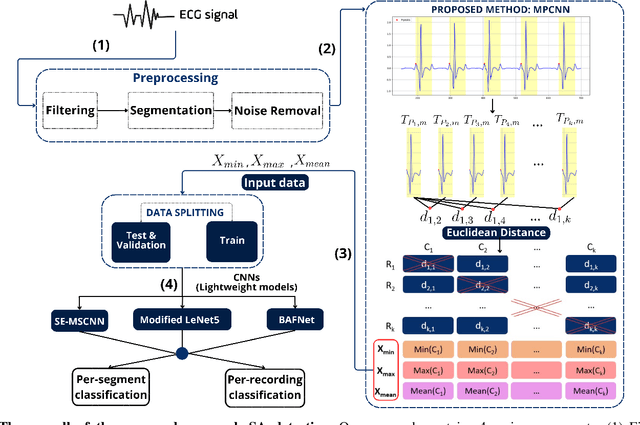
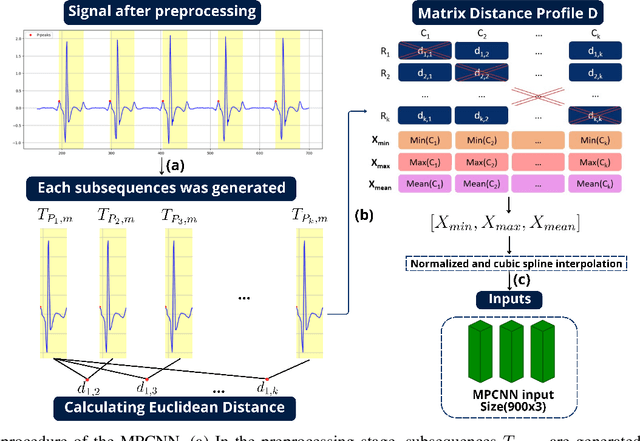
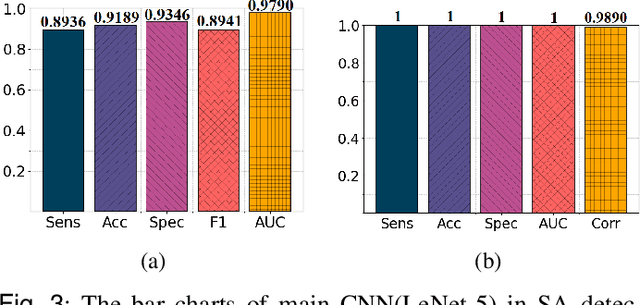
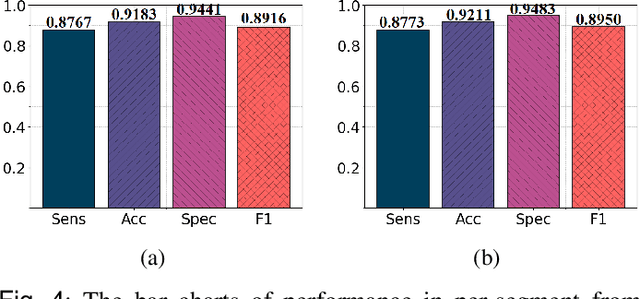
Sleep apnea (SA) is a significant respiratory condition that poses a major global health challenge. Previous studies have investigated several machine and deep learning models for electrocardiogram (ECG)-based SA diagnoses. Despite these advancements, conventional feature extractions derived from ECG signals, such as R-peaks and RR intervals, may fail to capture crucial information encompassed within the complete PQRST segments. In this study, we propose an innovative approach to address this diagnostic gap by delving deeper into the comprehensive segments of the ECG signal. The proposed methodology draws inspiration from Matrix Profile algorithms, which generate an Euclidean distance profile from fixed-length signal subsequences. From this, we derived the Min Distance Profile (MinDP), Max Distance Profile (MaxDP), and Mean Distance Profile (MeanDP) based on the minimum, maximum, and mean of the profile distances, respectively. To validate the effectiveness of our approach, we use the modified LeNet-5 architecture as the primary CNN model, along with two existing lightweight models, BAFNet and SE-MSCNN, for ECG classification tasks. Our extensive experimental results on the PhysioNet Apnea-ECG dataset revealed that with the new feature extraction method, we achieved a per-segment accuracy up to 92.11 \% and a per-recording accuracy of 100\%. Moreover, it yielded the highest correlation compared to state-of-the-art methods, with a correlation coefficient of 0.989. By introducing a new feature extraction method based on distance relationships, we enhanced the performance of certain lightweight models, showing potential for home sleep apnea test (HSAT) and SA detection in IoT devices. The source code for this work is made publicly available in GitHub: https://github.com/vinuni-vishc/MPCNN-Sleep-Apnea.
Enhancing Object Coherence in Layout-to-Image Synthesis
Nov 25, 2023Layout-to-image synthesis is an emerging technique in conditional image generation. It aims to generate complex scenes, where users require fine control over the layout of the objects in a scene. However, it remains challenging to control the object coherence, including semantic coherence (e.g., the cat looks at the flowers or not) and physical coherence (e.g., the hand and the racket should not be misaligned). In this paper, we propose a novel diffusion model with effective global semantic fusion (GSF) and self-similarity feature enhancement modules to guide the object coherence for this task. For semantic coherence, we argue that the image caption contains rich information for defining the semantic relationship within the objects in the images. Instead of simply employing cross-attention between captions and generated images, which addresses the highly relevant layout restriction and semantic coherence separately and thus leads to unsatisfying results shown in our experiments, we develop GSF to fuse the supervision from the layout restriction and semantic coherence requirement and exploit it to guide the image synthesis process. Moreover, to improve the physical coherence, we develop a Self-similarity Coherence Attention (SCA) module to explicitly integrate local contextual physical coherence into each pixel's generation process. Specifically, we adopt a self-similarity map to encode the coherence restrictions and employ it to extract coherent features from text embedding. Through visualization of our self-similarity map, we explore the essence of SCA, revealing that its effectiveness is not only in capturing reliable physical coherence patterns but also in enhancing complex texture generation. Extensive experiments demonstrate the superiority of our proposed method in both image generation quality and controllability.
Crafting In-context Examples according to LMs' Parametric Knowledge
Nov 16, 2023In-context learning has been applied to knowledge-rich tasks such as question answering. In such scenarios, in-context examples are used to trigger a behaviour in the language model: namely, it should surface information stored in its parametric knowledge. We study the construction of in-context example sets, with a focus on the parametric knowledge of the model regarding in-context examples. We identify 'known' examples, where models can correctly answer from its parametric knowledge, and 'unknown' ones. Our experiments show that prompting with 'unknown' examples decreases the performance, potentially as it encourages hallucination rather than searching its parametric knowledge. Constructing an in-context example set that presents both known and unknown information performs the best across diverse settings. We perform analysis on three multi-answer question answering datasets, which allows us to further study answer set ordering strategies based on the LM's knowledge about each answer. Together, our study sheds lights on how to best construct in-context example sets for knowledge-rich tasks.
GMTR: Graph Matching Transformers
Nov 14, 2023Vision transformers (ViTs) have recently been used for visual matching beyond object detection and segmentation. However, the original grid dividing strategy of ViTs neglects the spatial information of the keypoints, limiting the sensitivity to local information. Therefore, we propose \textbf{QueryTrans} (Query Transformer), which adopts a cross-attention module and keypoints-based center crop strategy for better spatial information extraction. We further integrate the graph attention module and devise a transformer-based graph matching approach \textbf{GMTR} (Graph Matching TRansformers) whereby the combinatorial nature of GM is addressed by a graph transformer neural GM solver. On standard GM benchmarks, GMTR shows competitive performance against the SOTA frameworks. Specifically, on Pascal VOC, GMTR achieves $\mathbf{83.6\%}$ accuracy, $\mathbf{0.9\%}$ higher than the SOTA framework. On Spair-71k, GMTR shows great potential and outperforms most of the previous works. Meanwhile, on Pascal VOC, QueryTrans improves the accuracy of NGMv2 from $80.1\%$ to $\mathbf{83.3\%}$, and BBGM from $79.0\%$ to $\mathbf{84.5\%}$. On Spair-71k, QueryTrans improves NGMv2 from $80.6\%$ to $\mathbf{82.5\%}$, and BBGM from $82.1\%$ to $\mathbf{83.9\%}$. Source code will be made publicly available.