 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Challenges of Large Language Models for Mental Health Counseling
Nov 23, 2023
The global mental health crisis is looming with a rapid increase in mental disorders, limited resources, and the social stigma of seeking treatment. As the field of artificial intelligence (AI) has witnessed significant advancements in recent years, large language models (LLMs) capable of understanding and generating human-like text may be used in supporting or providing psychological counseling. However, the application of LLMs in the mental health domain raises concerns regarding the accuracy, effectiveness, and reliability of the information provided. This paper investigates the major challenges associated with the development of LLMs for psychological counseling, including model hallucination, interpretability, bias, privacy, and clinical effectiveness. We explore potential solutions to these challenges that are practical and applicable to the current paradigm of AI. From our experience in developing and deploying LLMs for mental health, AI holds a great promise for improving mental health care, if we can carefully navigate and overcome pitfalls of LLMs.
Multivariate Scenario Generation of Day-Ahead Electricity Prices using Normalizing Flows
Nov 23, 2023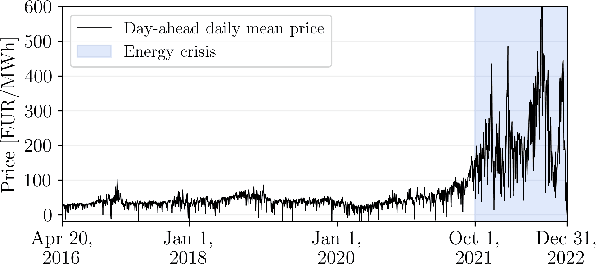
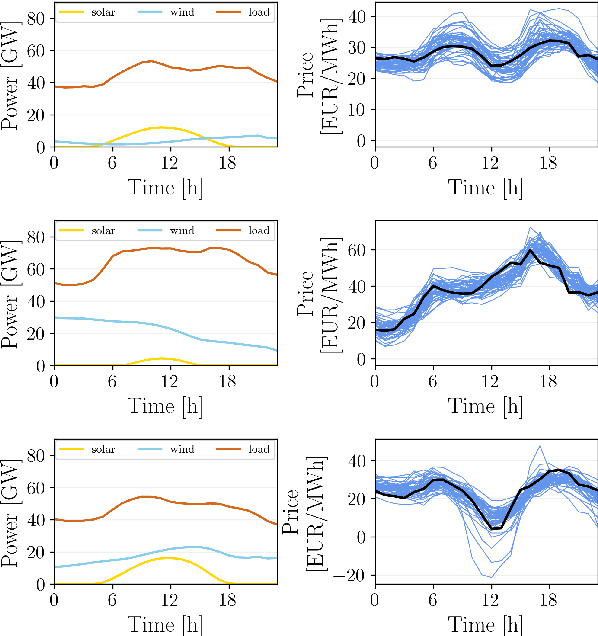
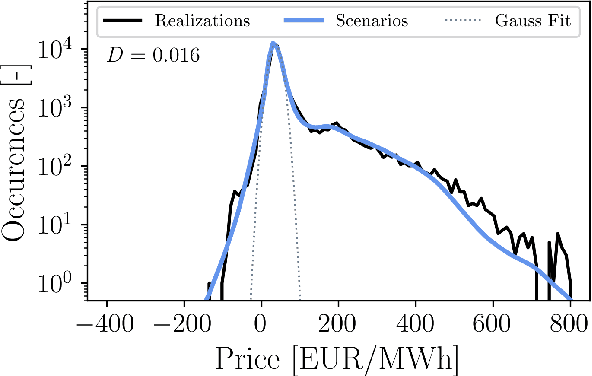
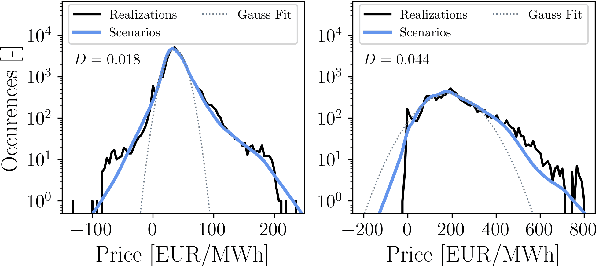
Trading on electricity markets requires accurate information about the realization of electricity prices and the uncertainty attached to the predictions. We present a probabilistic forecasting approach for day-ahead electricity prices using the fully data-driven deep generative model called normalizing flows. Our modeling approach generates full-day scenarios of day-ahead electricity prices based on conditional features such as residual load forecasts. Furthermore, we propose extended feature sets of prior realizations and a periodic retraining scheme that allows the normalizing flow to adapt to the changing conditions of modern electricity markets. In particular, we investigate the impact of the energy crisis ensuing from the Russian invasion of Ukraine. Our results highlight that the normalizing flow generates high-quality scenarios that reproduce the true price distribution and yield highly accurate forecasts. Additionally, our analysis highlights how our improvements towards adaptations in changing regimes allow the normalizing flow to adapt to changing market conditions and enables continued sampling of high-quality day-ahead price scenarios.
PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
Nov 23, 2023
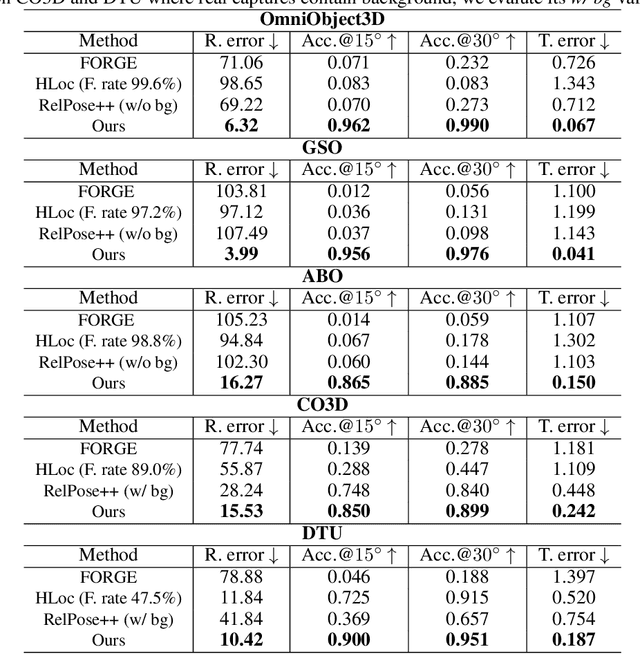
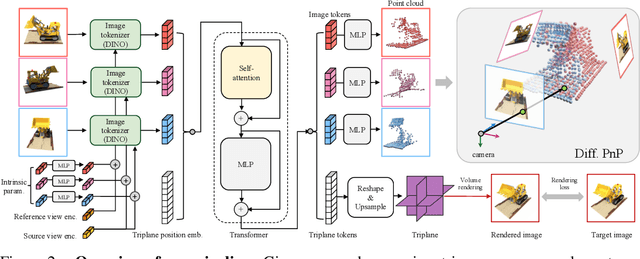
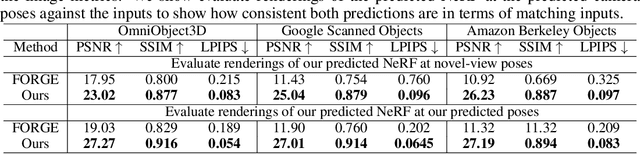
We propose a Pose-Free Large Reconstruction Model (PF-LRM) for reconstructing a 3D object from a few unposed images even with little visual overlap, while simultaneously estimating the relative camera poses in ~1.3 seconds on a single A100 GPU. PF-LRM is a highly scalable method utilizing the self-attention blocks to exchange information between 3D object tokens and 2D image tokens; we predict a coarse point cloud for each view, and then use a differentiable Perspective-n-Point (PnP) solver to obtain camera poses. When trained on a huge amount of multi-view posed data of ~1M objects, PF-LRM shows strong cross-dataset generalization ability, and outperforms baseline methods by a large margin in terms of pose prediction accuracy and 3D reconstruction quality on various unseen evaluation datasets. We also demonstrate our model's applicability in downstream text/image-to-3D task with fast feed-forward inference. Our project website is at: https://totoro97.github.io/pf-lrm .
Dynamic Analysis Method for Hidden Dangers in Substation Based on Knowledge Graph
Nov 22, 2023To address the challenge of identifying and understanding hidden dangers in substations from unstructured text data, a novel dynamic analysis method is proposed. This approach begins by analyzing and extracting data from the unstructured text related to hidden dangers. It then leverages a flexible, distributed data search engine built on Elastic-Search to handle this information. Following this, the hidden Markov model is employed to train the data within the engine. The Viterbi algorithm is integrated to decipher the hidden state sequences, facilitating the segmentation and labeling of entities related to hidden dangers. The final step involves using the Neo4j graph database to dynamically create a knowledge map that visualizes hidden dangers in the substation. This method's effectiveness is demonstrated through an example analysis using data from a specific substation's hidden dangers.
Retargeting Visual Data with Deformation Fields
Nov 22, 2023Seam carving is an image editing method that enable content-aware resizing, including operations like removing objects. However, the seam-finding strategy based on dynamic programming or graph-cut limits its applications to broader visual data formats and degrees of freedom for editing. Our observation is that describing the editing and retargeting of images more generally by a displacement field yields a generalisation of content-aware deformations. We propose to learn a deformation with a neural network that keeps the output plausible while trying to deform it only in places with low information content. This technique applies to different kinds of visual data, including images, 3D scenes given as neural radiance fields, or even polygon meshes. Experiments conducted on different visual data show that our method achieves better content-aware retargeting compared to previous methods.
Learning Using Generated Privileged Information by Text-to-Image Diffusion Models
Sep 26, 2023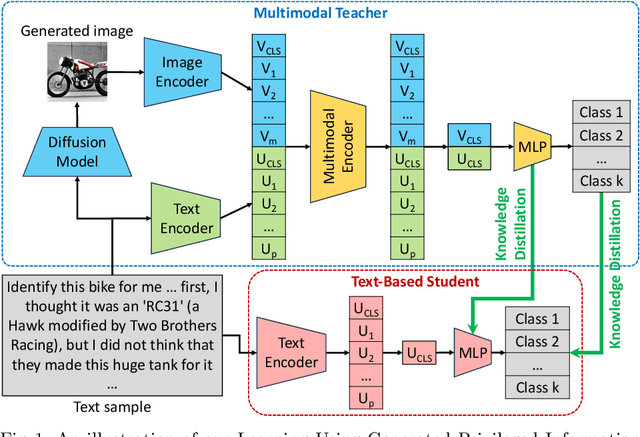
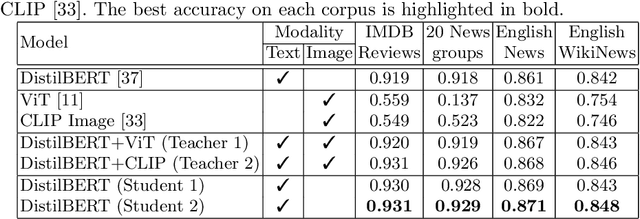

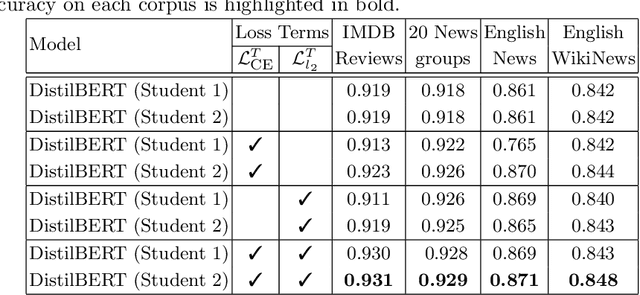
Learning Using Privileged Information is a particular type of knowledge distillation where the teacher model benefits from an additional data representation during training, called privileged information, improving the student model, which does not see the extra representation. However, privileged information is rarely available in practice. To this end, we propose a text classification framework that harnesses text-to-image diffusion models to generate artificial privileged information. The generated images and the original text samples are further used to train multimodal teacher models based on state-of-the-art transformer-based architectures. Finally, the knowledge from multimodal teachers is distilled into a text-based (unimodal) student. Hence, by employing a generative model to produce synthetic data as privileged information, we guide the training of the student model. Our framework, called Learning Using Generated Privileged Information (LUGPI), yields noticeable performance gains on four text classification data sets, demonstrating its potential in text classification without any additional cost during inference.
Teach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
FreePIH: Training-Free Painterly Image Harmonization with Diffusion Model
Nov 25, 2023This paper provides an efficient training-free painterly image harmonization (PIH) method, dubbed FreePIH, that leverages only a pre-trained diffusion model to achieve state-of-the-art harmonization results. Unlike existing methods that require either training auxiliary networks or fine-tuning a large pre-trained backbone, or both, to harmonize a foreground object with a painterly-style background image, our FreePIH tames the denoising process as a plug-in module for foreground image style transfer. Specifically, we find that the very last few steps of the denoising (i.e., generation) process strongly correspond to the stylistic information of images, and based on this, we propose to augment the latent features of both the foreground and background images with Gaussians for a direct denoising-based harmonization. To guarantee the fidelity of the harmonized image, we make use of multi-scale features to enforce the consistency of the content and stability of the foreground objects in the latent space, and meanwhile, aligning both fore-/back-grounds with the same style. Moreover, to accommodate the generation with more structural and textural details, we further integrate text prompts to attend to the latent features, hence improving the generation quality. Quantitative and qualitative evaluations on COCO and LAION 5B datasets demonstrate that our method can surpass representative baselines by large margins.
GBD-TS: Goal-based Pedestrian Trajectory Prediction with Diffusion using Tree Sampling Algorithm
Nov 25, 2023Predicting pedestrian trajectories is crucial for improving the safety and effectiveness of autonomous driving and mobile robots. However, this task is nontrivial due to the inherent stochasticity of human motion, which naturally requires the predictor to generate multi-model prediction. Previous works have used various generative methods, such as GAN and VAE, for pedestrian trajectory prediction. Nevertheless, these methods may suffer from problems, including mode collapse and relatively low-quality results. The denoising diffusion probabilistic model (DDPM) has recently been applied to trajectory prediction due to its simple training process and powerful reconstruction ability. However, current diffusion-based methods are straightforward without fully leveraging input information and usually require many denoising iterations leading to a long inference time or an additional network for initialization. To address these challenges and promote the application of diffusion models in trajectory prediction, we propose a novel scene-aware multi-modal pedestrian trajectory prediction framework called GBD. GBD combines goal prediction with the diffusion network. First, the goal predictor produces multiple goals, and then the diffusion network generates multi-modal trajectories conditioned on these goals. Furthermore, we introduce a new diffusion sampling algorithm named tree sampling (TS), which leverages common feature to reduce the inference time and improve accuracy for multi-modal prediction. Experimental results demonstrate that our GBD-TS method achieves state-of-the-art performance with real-time inference speed.
Low-latency Visual Previews of Large Synchrotron Micro-CT Datasets
Nov 25, 2023The unprecedented rate at which synchrotron radiation facilities are producing micro-computed (micro-CT) datasets has resulted in an overwhelming amount of data that scientists struggle to browse and interact with in real-time. Thousands of arthropods are scanned into micro-CT within the NOVA project, producing a large collection of gigabyte-sized datasets. In this work, we present methods to reduce the size of this data, scaling it from gigabytes to megabytes, enabling the micro-CT dataset to be delivered in real-time. In addition, arthropods can be identified by scientists even after implementing data reduction methodologies. Our initial step is to devise three distinct visual previews that comply with the best practices of data exploration. Subsequently, each visual preview warrants its own design consideration, thereby necessitating an individual data processing pipeline for each. We aim to present data reduction algorithms applied across the data processing pipelines. Particularly, we reduce size by using the multi-resolution slicemaps, the server-side rendering, and the histogram filtering approaches. In the evaluation, we examine the disparities of each method to identify the most favorable arrangement for our operation, which can then be adjusted for other experiments that have comparable necessities. Our demonstration proved that reducing the dataset size to the megabyte range is achievable without compromising the arthropod's geometry information.