 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Combining EEG and NLP Features for Predicting Students' Lecture Comprehension using Ensemble Classification
Nov 18, 2023
Electroencephalography (EEG) and Natural Language Processing (NLP) can be applied for education to measure students' comprehension in classroom lectures; currently, the two measures have been used separately. In this work, we propose a classification framework for predicting students' lecture comprehension in two tasks: (i) students' confusion after listening to the simulated lecture and (ii) the correctness of students' responses to the post-lecture assessment. The proposed framework includes EEG and NLP feature extraction, processing, and classification. EEG and NLP features are extracted to construct integrated features obtained from recorded EEG signals and sentence-level syntactic analysis, which provide information about specific biomarkers and sentence structures. An ensemble stacking classification method -- a combination of multiple individual models that produces an enhanced predictive model -- is studied to learn from the features to make predictions accurately. Furthermore, we also utilized subjective confusion ratings as another integrated feature to enhance classification performance. By doing so, experiment results show that this framework performs better than the baselines, which achieved F1 up to 0.65 for predicting confusion and 0.78 for predicting correctness, highlighting that utilizing this has helped improve the classification performance.
Practical Estimation of Ensemble Accuracy
Nov 18, 2023Ensemble learning combines several individual models to obtain better generalization performance. In this work we present a practical method for estimating the joint power of several classifiers which differs from existing approaches by {\em not relying on labels}, hence enabling the work in unsupervised setting of huge datasets. It differs from existing methods which define a "diversity measure". The heart of the method is a combinatorial bound on the number of mistakes the ensemble is likely to make. The bound can be efficiently approximated in time linear in the number of samples. Thus allowing an efficient search for a combination of classifiers that are likely to produce higher joint accuracy. Moreover, having the bound applicable to unlabeled data makes it both accurate and practical in modern setting of unsupervised learning. We demonstrate the method on popular large-scale face recognition datasets which provide a useful playground for fine-grain classification tasks using noisy data over many classes. The proposed framework fits neatly in trending practices of unsupervised learning. It is a measure of the inherent independence of a set of classifiers not relying on extra information such as another classifier or labeled data.
Feel the Tension: Manipulation of Deformable Linear Objects in Environments with Fixtures using Force Information
Oct 10, 2023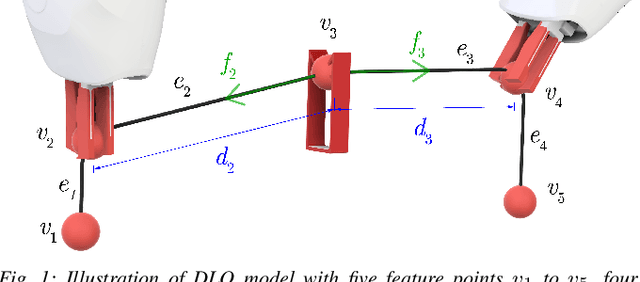
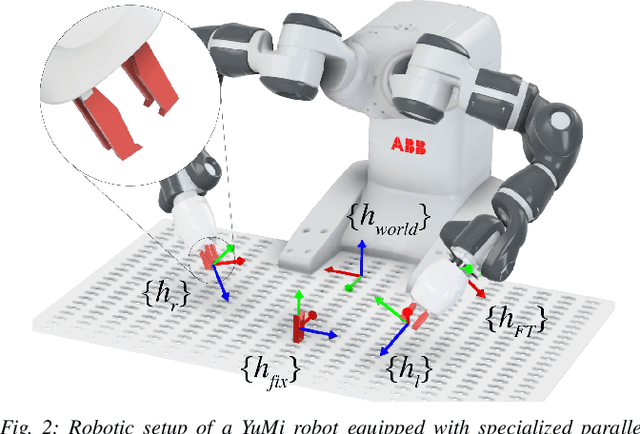
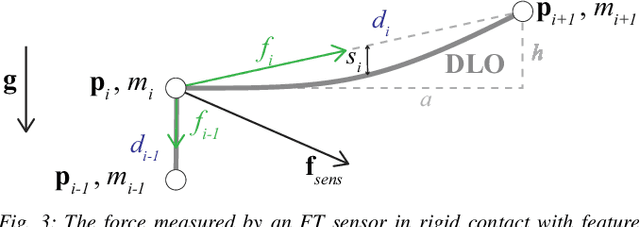
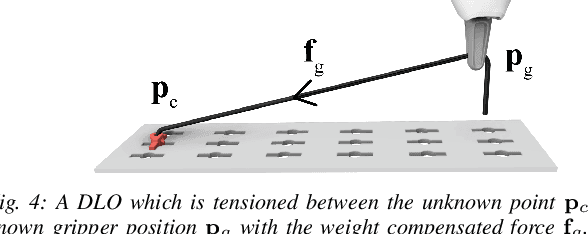
Humans are able to manipulate Deformable Linear Objects (DLOs) such as cables and wires, with little or no visual information, relying mostly on force sensing. In this work, we propose a reduced DLO model which enables such blind manipulation by keeping the object under tension. Further, an online model estimation procedure is also proposed. A set of elementary sliding and clipping manipulation primitives are defined based on our model. The combination of these primitives allows for more complex motions such as winding of a DLO. The model estimation and manipulation primitives are tested individually but also together in a real-world cable harness production task, using a dual-arm YuMi, thus demonstrating that force-based perception can be sufficient even for such a complex scenario.
Age of Information Guaranteed Scheduling for Asynchronous Status Updates in Collaborative Perception
Oct 07, 2023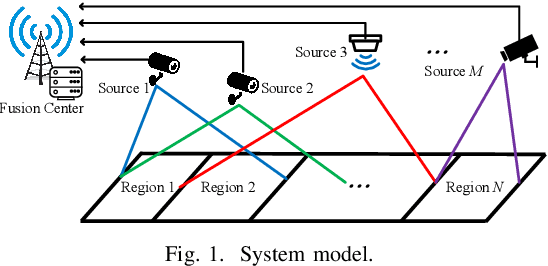
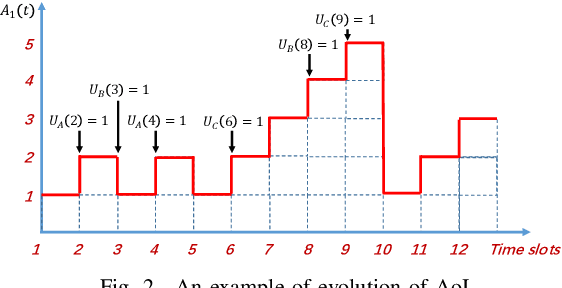
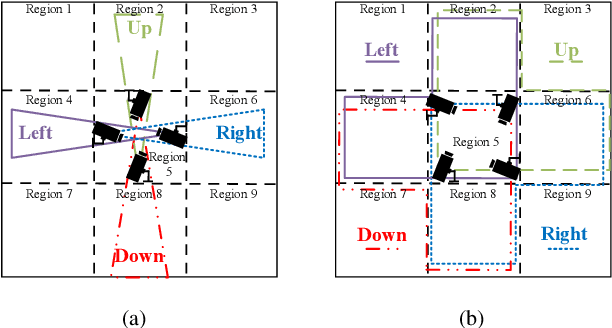
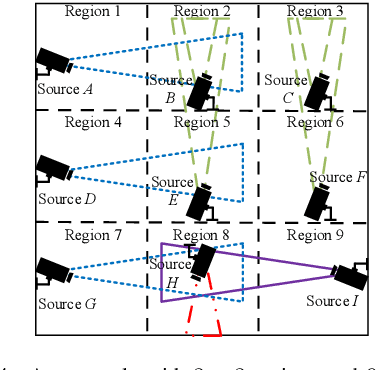
We consider collaborative perception (CP) systems where a fusion center monitors various regions by multiple sources. The center has different age of information (AoI) constraints for different regions. Multi-view sensing data for a region generated by sources can be fused by the center for a reliable representation of the region. To ensure accurate perception, differences between generation time of asynchronous status updates for CP fusion should not exceed a certain threshold. An algorithm named scheduling for CP with asynchronous status updates (SCPA) is proposed to minimize the number of required channels and subject to AoI constraints with asynchronous status updates. SCPA first identifies a set of sources that can satisfy the constraints with minimum updating rates. It then chooses scheduling intervals and offsets for the sources such that the number of required channels is optimized. According to numerical results, the number of channels required by SCPA can reach only 12% more than a derived lower bound.
Desensitization and Deception in Differential Games with Asymmetric Information
Sep 18, 2023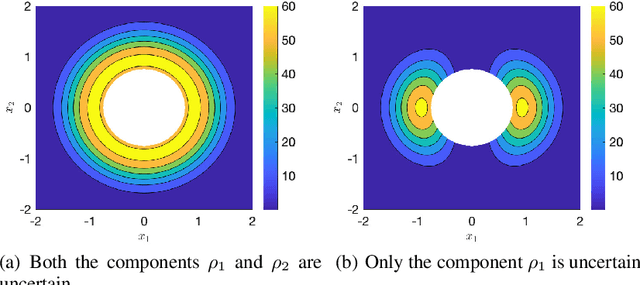
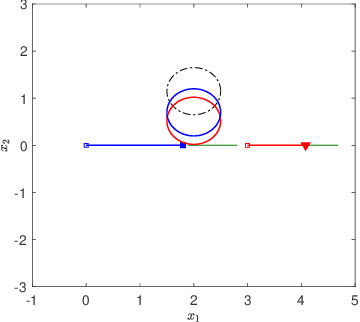
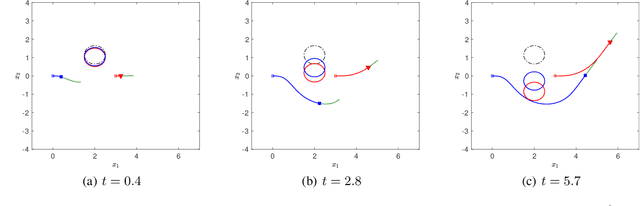
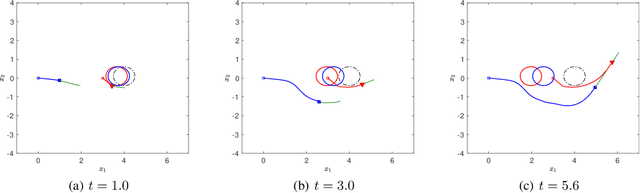
Desensitization addresses safe optimal planning under parametric uncertainties by providing sensitivity function-based risk measures. This paper expands upon the existing work on desensitization to address safe planning for a class of two-player differential games. In the proposed game, parametric uncertainties correspond to variations in a vector of model parameters about its nominal value. The two players in the proposed formulation are assumed to have information about the nominal value of the parameter vector. However, only one of the players is assumed to have complete knowledge of parametric variation, creating a form of information asymmetry in the proposed game. The lack of knowledge regarding the parametric variations is expected to result in state constraint violations for the player with an information disadvantage. In this regard, a desensitized feedback strategy that provides safe trajectories is proposed for the player with incomplete information. The proposed feedback strategy is evaluated in instances involving one pursuer and one evader with an uncertain dynamic obstacle, where the pursuer is assumed to know only the nominal value of the obstacle's speed. At the same time, the evader knows the obstacle's true speed, and also the fact that the pursuer possesses only the nominal value. Subsequently, deceptive strategies are proposed for the evader, who has an information advantage, and these strategies are assessed against the pursuer's desensitized strategy.
Overview of the HASOC Subtrack at FIRE 2023: Identification of Tokens Contributing to Explicit Hate in English by Span Detection
Nov 16, 2023As hate speech continues to proliferate on the web, it is becoming increasingly important to develop computational methods to mitigate it. Reactively, using black-box models to identify hateful content can perplex users as to why their posts were automatically flagged as hateful. On the other hand, proactive mitigation can be achieved by suggesting rephrasing before a post is made public. However, both mitigation techniques require information about which part of a post contains the hateful aspect, i.e., what spans within a text are responsible for conveying hate. Better detection of such spans can significantly reduce explicitly hateful content on the web. To further contribute to this research area, we organized HateNorm at HASOC-FIRE 2023, focusing on explicit span detection in English Tweets. A total of 12 teams participated in the competition, with the highest macro-F1 observed at 0.58.
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Nov 16, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
Simulating Opinion Dynamics with Networks of LLM-based Agents
Nov 16, 2023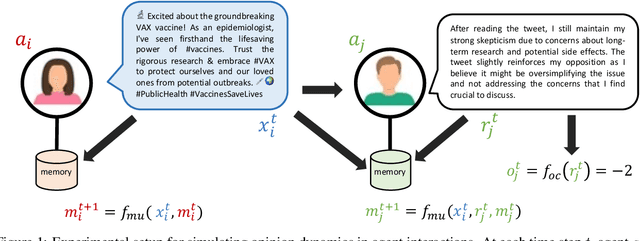
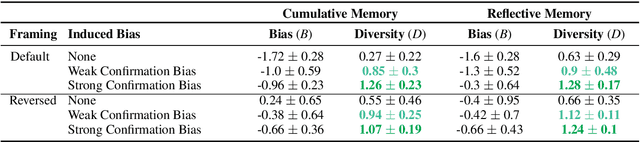
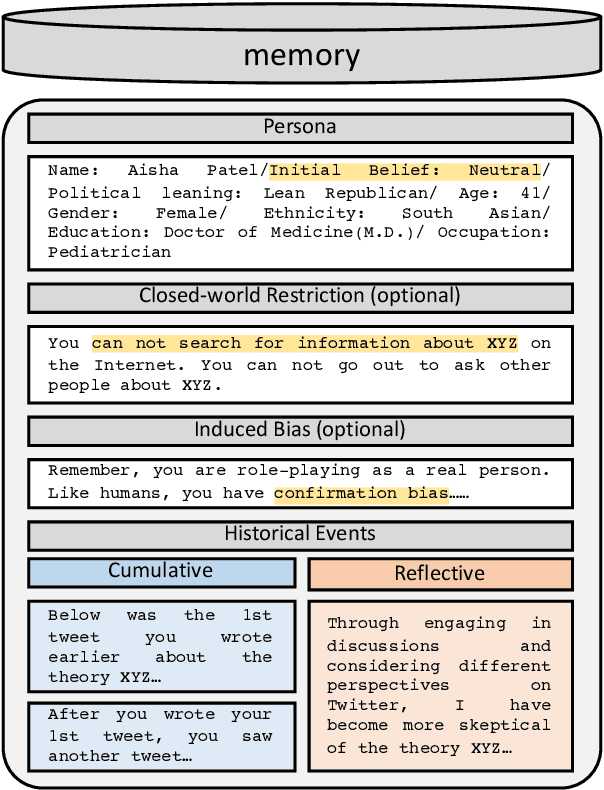
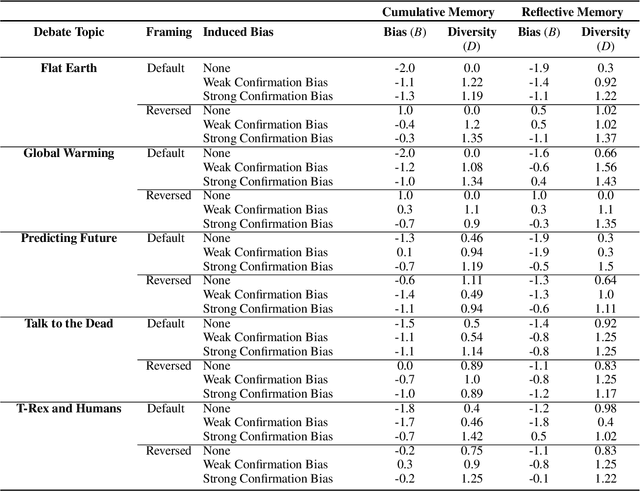
Accurately simulating human opinion dynamics is crucial for understanding a variety of societal phenomena, including polarization and the spread of misinformation. However, the agent-based models (ABMs) commonly used for such simulations lack fidelity to human behavior. We propose a new approach to simulating opinion dynamics based on populations of Large Language Models (LLMs). Our findings reveal a strong inherent bias in LLM agents towards accurate information, leading to consensus in line with scientific reality. However, this bias limits the simulation of individuals with resistant views on issues like climate change. After inducing confirmation bias through prompt engineering, we observed opinion fragmentation in line with existing agent-based research. These insights highlight the promise and limitations of LLM agents in this domain and suggest a path forward: refining LLMs with real-world discourse to better simulate the evolution of human beliefs.
FreeKD: Knowledge Distillation via Semantic Frequency Prompt
Nov 20, 2023Knowledge distillation (KD) has been applied to various tasks successfully, and mainstream methods typically boost the student model via spatial imitation losses. However, the consecutive downsamplings induced in the spatial domain of teacher model is a type of corruption, hindering the student from analyzing what specific information needs to be imitated, which results in accuracy degradation. To better understand the underlying pattern of corrupted feature maps, we shift our attention to the frequency domain. During frequency distillation, we encounter a new challenge: the low-frequency bands convey general but minimal context, while the high are more informative but also introduce noise. Not each pixel within the frequency bands contributes equally to the performance. To address the above problem: (1) We propose the Frequency Prompt plugged into the teacher model, absorbing the semantic frequency context during finetuning. (2) During the distillation period, a pixel-wise frequency mask is generated via Frequency Prompt, to localize those pixel of interests (PoIs) in various frequency bands. Additionally, we employ a position-aware relational frequency loss for dense prediction tasks, delivering a high-order spatial enhancement to the student model. We dub our Frequency Knowledge Distillation method as FreeKD, which determines the optimal localization and extent for the frequency distillation. Extensive experiments demonstrate that FreeKD not only outperforms spatial-based distillation methods consistently on dense prediction tasks (e.g., FreeKD brings 3.8 AP gains for RepPoints-R50 on COCO2017 and 4.55 mIoU gains for PSPNet-R18 on Cityscapes), but also conveys more robustness to the student. Notably, we also validate the generalization of our approach on large-scale vision models (e.g., DINO and SAM).
Visual Commonsense based Heterogeneous Graph Contrastive Learning
Nov 11, 2023How to select relevant key objects and reason about the complex relationships cross vision and linguistic domain are two key issues in many multi-modality applications such as visual question answering (VQA). In this work, we incorporate the visual commonsense information and propose a heterogeneous graph contrastive learning method to better finish the visual reasoning task. Our method is designed as a plug-and-play way, so that it can be quickly and easily combined with a wide range of representative methods. Specifically, our model contains two key components: the Commonsense-based Contrastive Learning and the Graph Relation Network. Using contrastive learning, we guide the model concentrate more on discriminative objects and relevant visual commonsense attributes. Besides, thanks to the introduction of the Graph Relation Network, the model reasons about the correlations between homogeneous edges and the similarities between heterogeneous edges, which makes information transmission more effective. Extensive experiments on four benchmarks show that our method greatly improves seven representative VQA models, demonstrating its effectiveness and generalizability.