 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Submeter-level Land Cover Mapping of Japan
Nov 19, 2023
Deep learning has shown promising performance in submeter-level mapping tasks; however, the annotation cost of submeter-level imagery remains a challenge, especially when applied on a large scale. In this paper, we present the first submeter-level land cover mapping of Japan with eight classes, at a relatively low annotation cost. We introduce a human-in-the-loop deep learning framework leveraging OpenEarthMap, a recently introduced benchmark dataset for global submeter-level land cover mapping, with a U-Net model that achieves national-scale mapping with a small amount of additional labeled data. By adding a small amount of labeled data of areas or regions where a U-Net model trained on OpenEarthMap clearly failed and retraining the model, an overall accuracy of 80\% was achieved, which is a nearly 16 percentage point improvement after retraining. Using aerial imagery provided by the Geospatial Information Authority of Japan, we create land cover classification maps of eight classes for the entire country of Japan. Our framework, with its low annotation cost and high-accuracy mapping results, demonstrates the potential to contribute to the automatic updating of national-scale land cover mapping using submeter-level optical remote sensing data. The mapping results will be made publicly available.
NERIF: GPT-4V for Automatic Scoring of Drawn Models
Nov 21, 2023Scoring student-drawn models is time-consuming. Recently released GPT-4V provides a unique opportunity to advance scientific modeling practices by leveraging the powerful image processing capability. To test this ability specifically for automatic scoring, we developed a method NERIF (Notation-Enhanced Rubric Instruction for Few-shot Learning) employing instructional note and rubrics to prompt GPT-4V to score students' drawn models for science phenomena. We randomly selected a set of balanced data (N = 900) that includes student-drawn models for six modeling assessment tasks. Each model received a score from GPT-4V ranging at three levels: 'Beginning,' 'Developing,' or 'Proficient' according to scoring rubrics. GPT-4V scores were compared with human experts' scores to calculate scoring accuracy. Results show that GPT-4V's average scoring accuracy was mean =.51, SD = .037. Specifically, average scoring accuracy was .64 for the 'Beginning' class, .62 for the 'Developing' class, and .26 for the 'Proficient' class, indicating that more proficient models are more challenging to score. Further qualitative study reveals how GPT-4V retrieves information from image input, including problem context, example evaluations provided by human coders, and students' drawing models. We also uncovered how GPT-4V catches the characteristics of student-drawn models and narrates them in natural language. At last, we demonstrated how GPT-4V assigns scores to student-drawn models according to the given scoring rubric and instructional notes. Our findings suggest that the NERIF is an effective approach for employing GPT-4V to score drawn models. Even though there is space for GPT-4V to improve scoring accuracy, some mis-assigned scores seemed interpretable to experts. The results of this study show that utilizing GPT-4V for automatic scoring of student-drawn models is promising.
Implementation and Comparison of Methods to Extract Reliability KPIs out of Textual Wind Turbine Maintenance Work Orders
Nov 07, 2023Maintenance work orders are commonly used to document information about wind turbine operation and maintenance. This includes details about proactive and reactive wind turbine downtimes, such as preventative and corrective maintenance. However, the information contained in maintenance work orders is often unstructured and difficult to analyze, making it challenging for decision-makers to use this information for optimizing operation and maintenance. To address this issue, this work presents three different approaches to calculate reliability key performance indicators from maintenance work orders. The first approach involves manual labeling of the maintenance work orders by domain experts, using the schema defined in an industrial guideline to assign the label accordingly. The second approach involves the development of a model that automatically labels the maintenance work orders using text classification methods. The third technique uses an AI-assisted tagging tool to tag and structure the raw maintenance information contained in the maintenance work orders. The resulting calculated reliability key performance indicator of the first approach are used as a benchmark for comparison with the results of the second and third approaches. The quality and time spent are considered as criteria for evaluation. Overall, these three methods make extracting maintenance information from maintenance work orders more efficient, enable the assessment of reliability key performance indicators and therefore support the optimization of wind turbine operation and maintenance.
A Model-Agnostic Graph Neural Network for Integrating Local and Global Information
Oct 02, 2023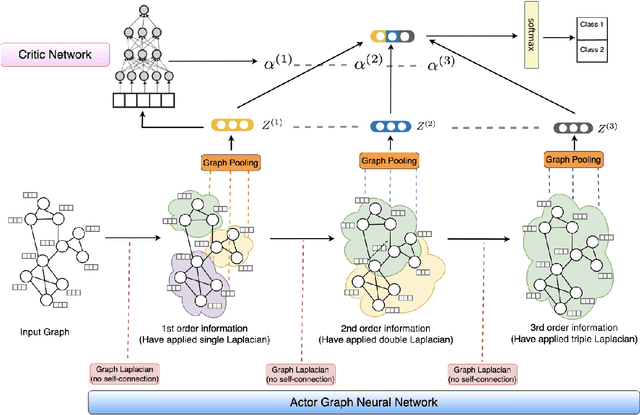
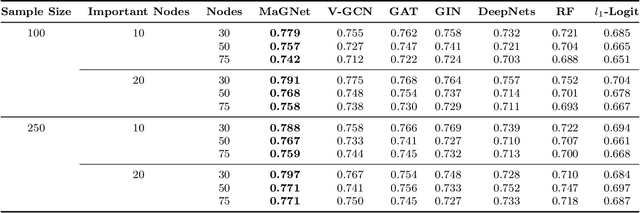
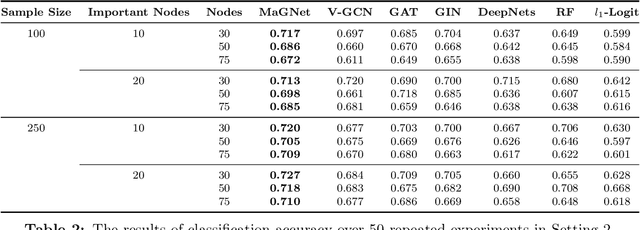
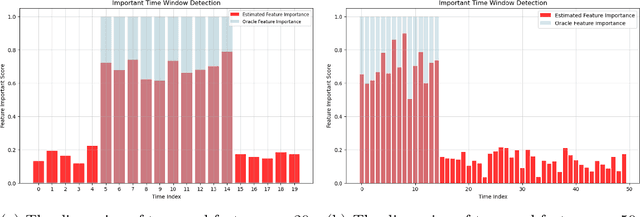
Graph Neural Networks (GNNs) have achieved promising performance in a variety of graph-focused tasks. Despite their success, existing GNNs suffer from two significant limitations: a lack of interpretability in results due to their black-box nature, and an inability to learn representations of varying orders. To tackle these issues, we propose a novel Model-agnostic Graph Neural Network (MaGNet) framework, which is able to sequentially integrate information of various orders, extract knowledge from high-order neighbors, and provide meaningful and interpretable results by identifying influential compact graph structures. In particular, MaGNet consists of two components: an estimation model for the latent representation of complex relationships under graph topology, and an interpretation model that identifies influential nodes, edges, and important node features. Theoretically, we establish the generalization error bound for MaGNet via empirical Rademacher complexity, and showcase its power to represent layer-wise neighborhood mixing. We conduct comprehensive numerical studies using simulated data to demonstrate the superior performance of MaGNet in comparison to several state-of-the-art alternatives. Furthermore, we apply MaGNet to a real-world case study aimed at extracting task-critical information from brain activity data, thereby highlighting its effectiveness in advancing scientific research.
Data-driven project planning: An integrated network learning and constraint relaxation approach in favor of scheduling
Nov 20, 2023Our focus is on projects, i.e., business processes, which are emerging as the economic drivers of our times. Differently from day-to-day operational processes that do not require detailed planning, a project requires planning and resource-constrained scheduling for coordinating resources across sub- or related projects and organizations. A planner in charge of project planning has to select a set of activities to perform, determine their precedence constraints, and schedule them according to temporal project constraints. We suggest a data-driven project planning approach for classes of projects such as infrastructure building and information systems development projects. A project network is first learned from historical records. The discovered network relaxes temporal constraints embedded in individual projects, thus uncovering where planning and scheduling flexibility can be exploited for greater benefit. Then, the network, which contains multiple project plan variations, from which one has to be selected, is enriched by identifying decision rules and frequent paths. The planner can rely on the project network for: 1) decoding a project variation such that it forms a new project plan, and 2) applying resource-constrained project scheduling procedures to determine the project's schedule and resource allocation. Using two real-world project datasets, we show that the suggested approach may provide the planner with significant flexibility (up to a 26% reduction of the critical path of a real project) to adjust the project plan and schedule. We believe that the proposed approach can play an important part in supporting decision making towards automated data-driven project planning.
Federated Knowledge Graph Completion via Latent Embedding Sharing and Tensor Factorization
Nov 17, 2023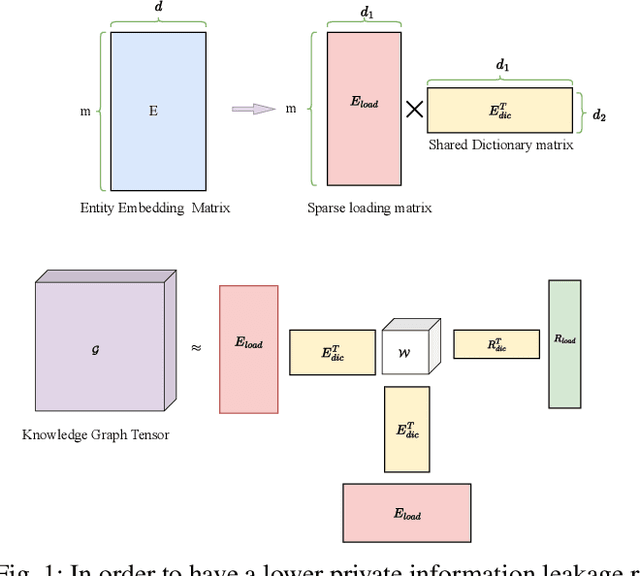
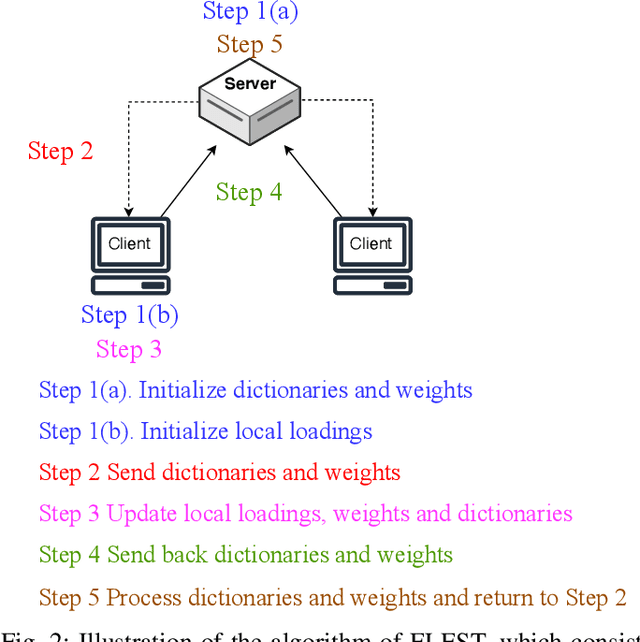
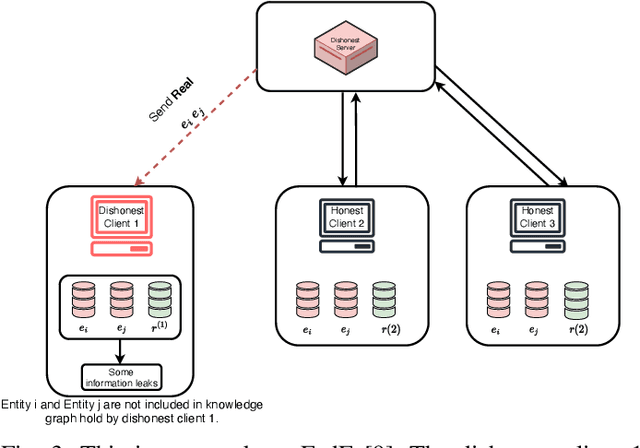

Knowledge graphs (KGs), which consist of triples, are inherently incomplete and always require completion procedure to predict missing triples. In real-world scenarios, KGs are distributed across clients, complicating completion tasks due to privacy restrictions. Many frameworks have been proposed to address the issue of federated knowledge graph completion. However, the existing frameworks, including FedE, FedR, and FEKG, have certain limitations. = FedE poses a risk of information leakage, FedR's optimization efficacy diminishes when there is minimal overlap among relations, and FKGE suffers from computational costs and mode collapse issues. To address these issues, we propose a novel method, i.e., Federated Latent Embedding Sharing Tensor factorization (FLEST), which is a novel approach using federated tensor factorization for KG completion. FLEST decompose the embedding matrix and enables sharing of latent dictionary embeddings to lower privacy risks. Empirical results demonstrate FLEST's effectiveness and efficiency, offering a balanced solution between performance and privacy. FLEST expands the application of federated tensor factorization in KG completion tasks.
Supervised structure learning
Nov 17, 2023This paper concerns structure learning or discovery of discrete generative models. It focuses on Bayesian model selection and the assimilation of training data or content, with a special emphasis on the order in which data are ingested. A key move - in the ensuing schemes - is to place priors on the selection of models, based upon expected free energy. In this setting, expected free energy reduces to a constrained mutual information, where the constraints inherit from priors over outcomes (i.e., preferred outcomes). The resulting scheme is first used to perform image classification on the MNIST dataset to illustrate the basic idea, and then tested on a more challenging problem of discovering models with dynamics, using a simple sprite-based visual disentanglement paradigm and the Tower of Hanoi (cf., blocks world) problem. In these examples, generative models are constructed autodidactically to recover (i.e., disentangle) the factorial structure of latent states - and their characteristic paths or dynamics.
A Comparative Analysis of Retrievability and PageRank Measures
Nov 17, 2023The accessibility of documents within a collection holds a pivotal role in Information Retrieval, signifying the ease of locating specific content in a collection of documents. This accessibility can be achieved via two distinct avenues. The first is through some retrieval model using a keyword or other feature-based search, and the other is where a document can be navigated using links associated with them, if available. Metrics such as PageRank, Hub, and Authority illuminate the pathways through which documents can be discovered within the network of content while the concept of Retrievability is used to quantify the ease with which a document can be found by a retrieval model. In this paper, we compare these two perspectives, PageRank and retrievability, as they quantify the importance and discoverability of content in a corpus. Through empirical experimentation on benchmark datasets, we demonstrate a subtle similarity between retrievability and PageRank particularly distinguishable for larger datasets.
Towards Pragmatic Awareness in Question Answering: A Case Study in Maternal and Infant Health
Nov 16, 2023Questions posed by information-seeking users often contain implicit false or potentially harmful assumptions. In a high-risk domain such as maternal and infant health, a question-answering system must recognize these pragmatic constraints and go beyond simply answering user questions, examining them in context to respond helpfully. To achieve this, we study pragmatic inferences made when mothers ask questions about pregnancy and infant care. Some of the inferences in these questions evade detection by existing methods, risking the possibility of QA systems failing to address them which can have dangerous health and policy implications. We explore the viability of detecting inferences from questions using large language models and illustrate that informing existing QA pipelines with pragmatic inferences produces responses that can mitigate the propagation of harmful beliefs.
MARformer: An Efficient Metal Artifact Reduction Transformer for Dental CBCT Images
Nov 16, 2023Cone Beam Computed Tomography (CBCT) plays a key role in dental diagnosis and surgery. However, the metal teeth implants could bring annoying metal artifacts during the CBCT imaging process, interfering diagnosis and downstream processing such as tooth segmentation. In this paper, we develop an efficient Transformer to perform metal artifacts reduction (MAR) from dental CBCT images. The proposed MAR Transformer (MARformer) reduces computation complexity in the multihead self-attention by a new Dimension-Reduced Self-Attention (DRSA) module, based on that the CBCT images have globally similar structure. A Patch-wise Perceptive Feed Forward Network (P2FFN) is also proposed to perceive local image information for fine-grained restoration. Experimental results on CBCT images with synthetic and real-world metal artifacts show that our MARformer is efficient and outperforms previous MAR methods and two restoration Transformers.