 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Received Signal and Channel Parameter Estimation in Molecular Communications
Nov 24, 2023
Molecular communication (MC) is a paradigm that employs molecules as information transmitters, hence, requiring unconventional transceivers and detection techniques for the Internet of Bio-Nano Things (IoBNT). In this study, we provide a novel MC model that incorporates a spherical transmitter and receiver with partial absorption. This model offers a more realistic representation than receiver architectures in literature, e.g. passive or entirely absorbing configurations. An optimization-based technique utilizing particle swarm optimization (PSO) is employed to accurately estimate the cumulative number of molecules received. This technique yields nearly constant correction parameters and demonstrates a significant improvement of 5 times in terms of root mean square error (RMSE). The estimated channel model provides an approximate analytical impulse response; hence, it is used for estimating channel parameters such as distance, diffusion coefficient, or a combination of both. We apply iterative maximum likelihood estimation (MLE) for the parameter estimation, which gives consistent errors compared to the estimated Cramer-Rao Lower Bound (CLRB).
Data-to-Text Bilingual Generation
Nov 24, 2023This document illustrates the use of pyrealb for generating two parallel texts (English and French) from a single source of data. The data selection and text organisation processes are shared between the two languages. only language dependent word and phrasing choices are distinct processes. The realized texts thus convey identical information in both languages without the risk of being lost in translation. This is especially important in cases where strict and simultaneous bilingualism is required. We first present the types of applications targeted by this approach and how the pyrealb English and French realizer can be used for achieving this goal in a natural way. We describe an object-oriented organization to ensure a convenient realization in both languages. To illustrate the process, different types of applications are then briefly sketched with links to the source code. A brief comparison of the text generation is given with the output of an instance of a GPT.
An Attention-Based Denoising Framework for Personality Detection in Social Media Texts
Nov 16, 2023In social media networks, users produce a large amount of text content anytime, providing researchers with a valuable approach to digging for personality-related information. Personality detection based on user-generated texts is a universal method that can be used to build user portraits. The presence of noise in social media texts hinders personality detection. However, previous studies have not fully addressed this challenge. Inspired by the scanning reading technique, we propose an attention-based information extraction mechanism (AIEM) for long texts, which is applied to quickly locate valuable pieces of information, and focus more attention on the deep semantics of key pieces. Then, we provide a novel attention-based denoising framework (ADF) for personality detection tasks and achieve state-of-the-art performance on two commonly used datasets. Notably, we obtain an average accuracy improvement of 10.2% on the gold standard Twitter-Myers-Briggs Type Indicator (Twitter-MBTI) dataset. We made our code publicly available on GitHub. We shed light on how AIEM works to magnify personality-related signals.
Deep Refinement-Based Joint Source Channel Coding over Time-Varying Channels
Nov 26, 2023In recent developments, deep learning (DL)-based joint source-channel coding (JSCC) for wireless image transmission has made significant strides in performance enhancement. Nonetheless, the majority of existing DL-based JSCC methods are tailored for scenarios featuring stable channel conditions, notably a fixed signal-to-noise ratio (SNR). This specialization poses a limitation, as their performance tends to wane in practical scenarios marked by highly dynamic channels, given that a fixed SNR inadequately represents the dynamic nature of such channels. In response to this challenge, we introduce a novel solution, namely deep refinement-based JSCC (DRJSCC). This innovative method is designed to seamlessly adapt to channels exhibiting temporal variations. By leveraging instantaneous channel state information (CSI), we dynamically optimize the encoding strategy through re-encoding the channel symbols. This dynamic adjustment ensures that the encoding strategy consistently aligns with the varying channel conditions during the transmission process. Specifically, our approach begins with the division of encoded symbols into multiple blocks, which are transmitted progressively to the receiver. In the event of changing channel conditions, we propose a mechanism to re-encode the remaining blocks, allowing them to adapt to the current channel conditions. Experimental results show that the DRJSCC scheme achieves comparable performance to the other mainstream DL-based JSCC models in stable channel conditions, and also exhibits great robustness against time-varying channels.
Angular-Distance Based Channel Estimation for Holographic MIMO
Nov 26, 2023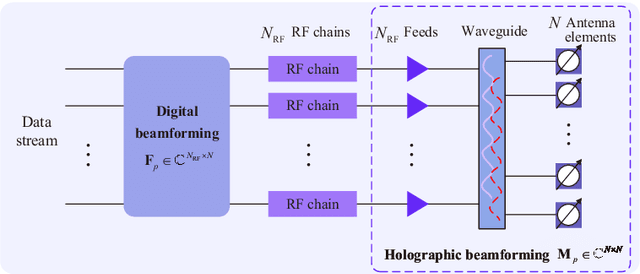
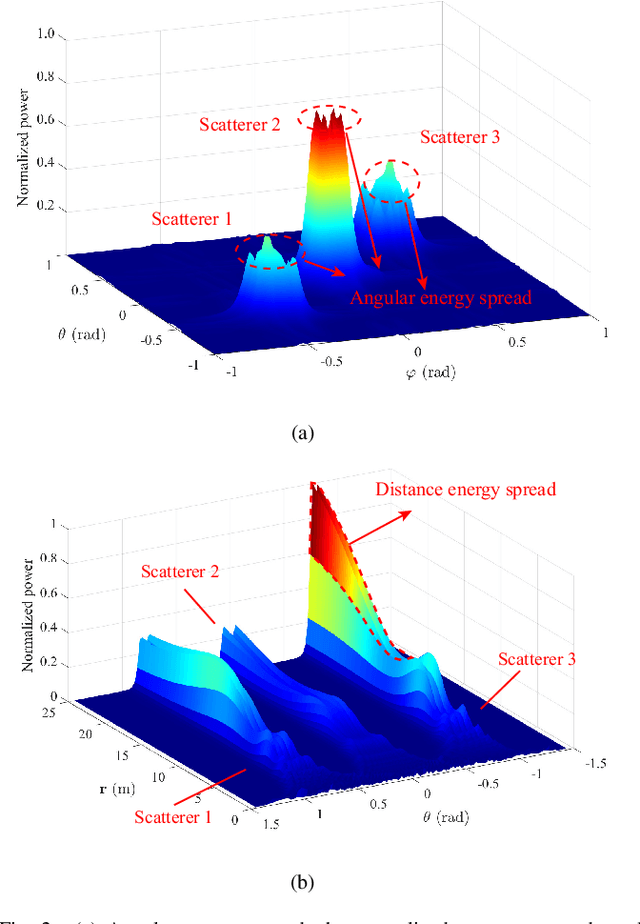
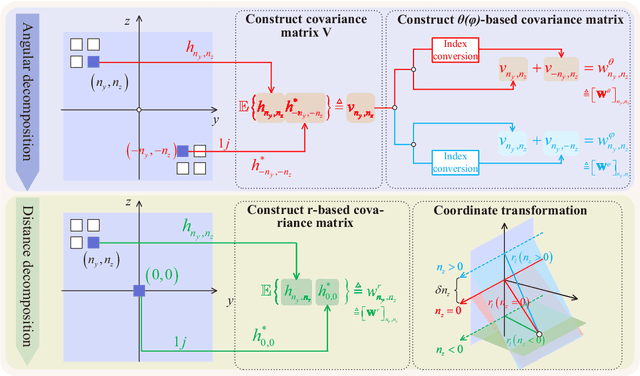
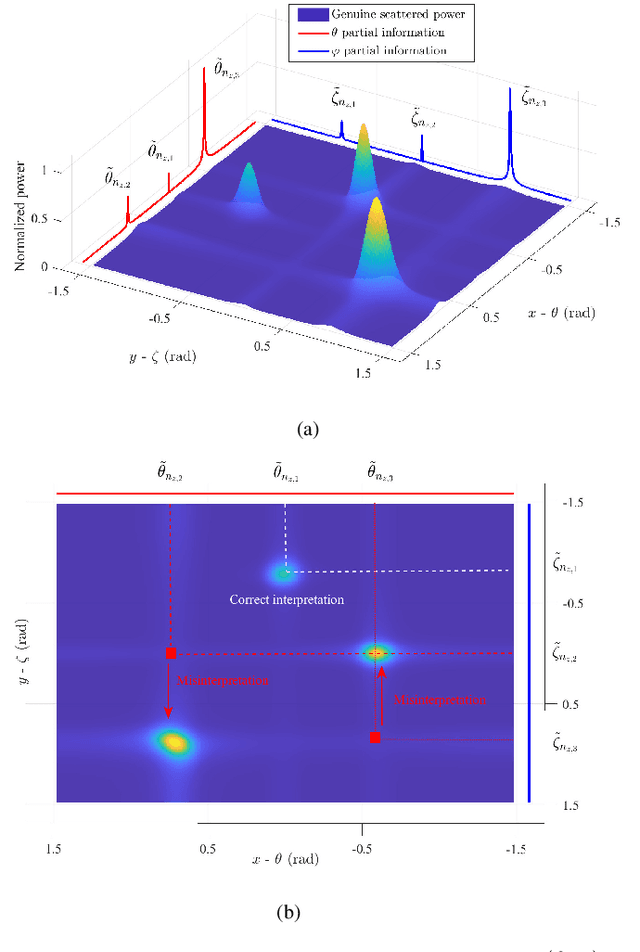
This paper investigates the channel estimation for holographic MIMO systems by unmasking their distinctions from the conventional one. Specifically, we elucidate that the channel estimation, subject to holographic MIMO's electromagnetically large antenna arrays, has to discriminate not only the angles of a user/scatterer but also its distance information, namely the three-dimensional (3D) azimuth and elevation angles plus the distance (AED) parameters. As the angular-domain representation fails to characterize the sparsity inherent in holographic MIMO channels, the tightly coupled 3D AED parameters are firstly decomposed for independently constructing their own covariance matrices. Then, the recovery of each individual parameter can be structured as a compressive sensing (CS) problem by harnessing the covariance matrix constructed. This pair of techniques contribute to a parametric decomposition and compressed deconstruction (DeRe) framework, along with a formulation of the maximum likelihood estimation for each parameter. Then, an efficient algorithm, namely DeRe-based variational Bayesian inference and message passing (DeRe-VM), is proposed for the sharp detection of the 3D AED parameters and the robust recovery of sparse channels. Finally, the proposed channel estimation regime is confirmed to be of great robustness in accommodating different channel conditions, regardless of the near-field and far-field contexts of a holographic MIMO system, as well as an improved performance in comparison to the state-of-the-art benchmarks.
CUCL: Codebook for Unsupervised Continual Learning
Nov 25, 2023The focus of this study is on Unsupervised Continual Learning (UCL), as it presents an alternative to Supervised Continual Learning which needs high-quality manual labeled data. The experiments under the UCL paradigm indicate a phenomenon where the results on the first few tasks are suboptimal. This phenomenon can render the model inappropriate for practical applications. To address this issue, after analyzing the phenomenon and identifying the lack of diversity as a vital factor, we propose a method named Codebook for Unsupervised Continual Learning (CUCL) which promotes the model to learn discriminative features to complete the class boundary. Specifically, we first introduce a Product Quantization to inject diversity into the representation and apply a cross quantized contrastive loss between the original representation and the quantized one to capture discriminative information. Then, based on the quantizer, we propose an effective Codebook Rehearsal to address catastrophic forgetting. This study involves conducting extensive experiments on CIFAR100, TinyImageNet, and MiniImageNet benchmark datasets. Our method significantly boosts the performances of supervised and unsupervised methods. For instance, on TinyImageNet, our method led to a relative improvement of 12.76% and 7% when compared with Simsiam and BYOL, respectively.
Multiuser Beamforming for Partially-Connected Millimeter Wave Massive MIMO
Nov 25, 2023Multiuser beamforming is considered for partially-connected millimeter wave massive MIMO systems. Based on perfect channel state information (CSI), a low-complexity hybrid beamforming scheme that decouples the analog beamformer and the digital beamformer is proposed to maximize the sum-rate. The analog beamformer design is modeled as a phase alignment problem to harvest the array gain. Given the analog beamformer, the digital beamformer is designed by solving a weighted minimum mean squared error problem. Then based on imperfect CSI, an analog-only beamformer design scheme is proposed, where the design problem aims at maximizing the desired signal power on the current user and minimizing the power on the other users to mitigate the multiuser interference. The original problem is then transformed into a series of independent beam nulling subproblems, where an efficient iterative algorithm using the majorization-minimization framework is proposed to solve the subproblems. Simulation results show that, under perfect CSI, the proposed scheme achieves almost the same sum-rate performance as the existing schemes but with lower computational complexity; and under imperfect CSI, the proposed analog-only beamforming design scheme can effectively mitigate the multiuser interference.
A Vision-Based Tactile Sensing System for Multimodal Contact Information Perception via Neural Network
Oct 03, 2023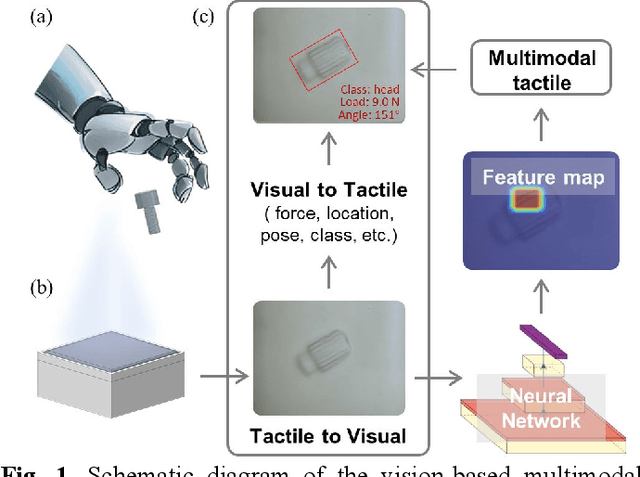
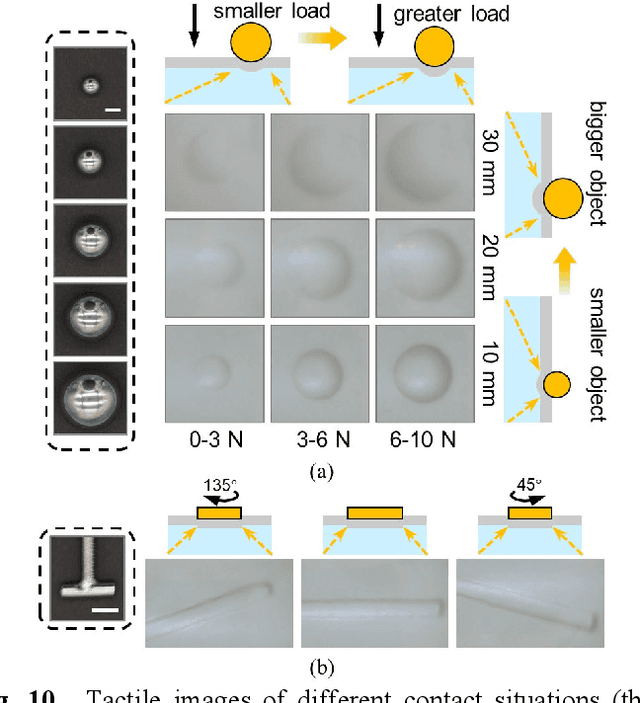
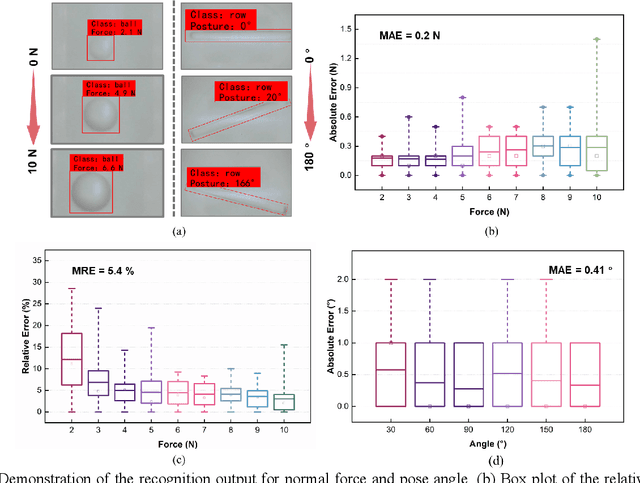
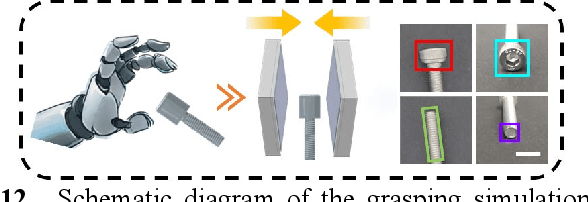
In general, robotic dexterous hands are equipped with various sensors for acquiring multimodal contact information such as position, force, and pose of the grasped object. This multi-sensor-based design adds complexity to the robotic system. In contrast, vision-based tactile sensors employ specialized optical designs to enable the extraction of tactile information across different modalities within a single system. Nonetheless, the decoupling design for different modalities in common systems is often independent. Therefore, as the dimensionality of tactile modalities increases, it poses more complex challenges in data processing and decoupling, thereby limiting its application to some extent. Here, we developed a multimodal sensing system based on a vision-based tactile sensor, which utilizes visual representations of tactile information to perceive the multimodal contact information of the grasped object. The visual representations contain extensive content that can be decoupled by a deep neural network to obtain multimodal contact information such as classification, position, posture, and force of the grasped object. The results show that the tactile sensing system can perceive multimodal tactile information using only one single sensor and without different data decoupling designs for different modal tactile information, which reduces the complexity of the tactile system and demonstrates the potential for multimodal tactile integration in various fields such as biomedicine, biology, and robotics.
A Grouping-based Scheduler for Efficient Channel Utilization under Age of Information Constraints
Oct 07, 2023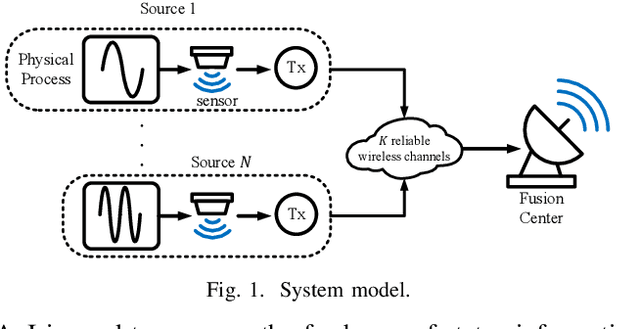
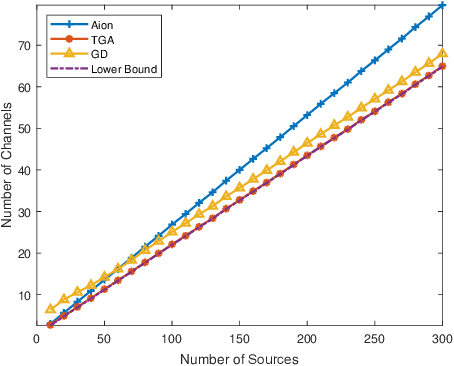
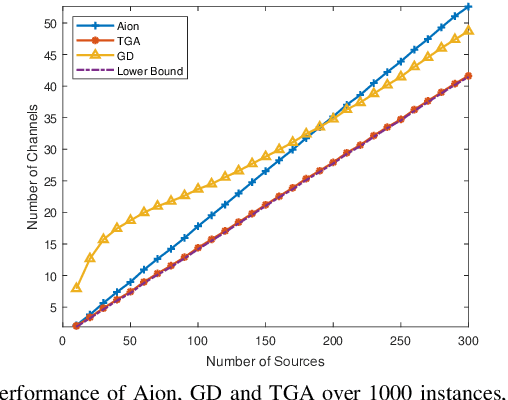
We consider a status information updating system where a fusion center collects the status information from a large number of sources and each of them has its own age of information (AoI) constraints. A novel grouping-based scheduler is proposed to solve this complex large-scale problem by dividing the sources into different scheduling groups. The problem is then transformed into deriving the optimal grouping scheme. A two-step grouping algorithm (TGA) is proposed: 1) Given AoI constraints, we first identify the sources with harmonic AoI constraints, then design a fast grouping method and an optimal scheduler for these sources. Under harmonic AoI constraints, each constraint is divisible by the smallest one and the sum of reciprocals of the constraints with the same value is divisible by the reciprocal of the smallest one. 2) For the other sources without such a special property, we pack the sources which can be scheduled together with minimum update rates into the same group. Simulations show the channel usage of the proposed TGA is significantly reduced as compared to a recent work and is 0.42% larger than a derived lower bound when the number of sources is large.
Dynamic Spatio-Temporal Summarization using Information Based Fusion
Oct 02, 2023In the era of burgeoning data generation, managing and storing large-scale time-varying datasets poses significant challenges. With the rise of supercomputing capabilities, the volume of data produced has soared, intensifying storage and I/O overheads. To address this issue, we propose a dynamic spatio-temporal data summarization technique that identifies informative features in key timesteps and fuses less informative ones. This approach minimizes storage requirements while preserving data dynamics. Unlike existing methods, our method retains both raw and summarized timesteps, ensuring a comprehensive view of information changes over time. We utilize information-theoretic measures to guide the fusion process, resulting in a visual representation that captures essential data patterns. We demonstrate the versatility of our technique across diverse datasets, encompassing particle-based flow simulations, security and surveillance applications, and biological cell interactions within the immune system. Our research significantly contributes to the realm of data management, introducing enhanced efficiency and deeper insights across diverse multidisciplinary domains. We provide a streamlined approach for handling massive datasets that can be applied to in situ analysis as well as post hoc analysis. This not only addresses the escalating challenges of data storage and I/O overheads but also unlocks the potential for informed decision-making. Our method empowers researchers and experts to explore essential temporal dynamics while minimizing storage requirements, thereby fostering a more effective and intuitive understanding of complex data behaviors.