 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023
As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
Automatic Time Signature Determination for New Scores Using Lyrics for Latent Rhythmic Structure
Nov 27, 2023There has recently been a sharp increase in interest in Artificial Intelligence-Generated Content (AIGC). Despite this, musical components such as time signatures have not been studied sufficiently to form an algorithmic determination approach for new compositions, especially lyrical songs. This is likely because of the neglect of musical details, which is critical for constructing a robust framework. Specifically, time signatures establish the fundamental rhythmic structure for almost all aspects of a song, including the phrases and notes. In this paper, we propose a novel approach that only uses lyrics as input to automatically generate a fitting time signature for lyrical songs and uncover the latent rhythmic structure utilizing explainable machine learning models. In particular, we devise multiple methods that are associated with discovering lyrical patterns and creating new features that simultaneously contain lyrical, rhythmic, and statistical information. In this approach, the best of our experimental results reveal a 97.6% F1 score and a 0.996 Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) score. In conclusion, our research directly generates time signatures from lyrics automatically for new scores utilizing machine learning, which is an innovative idea that approaches an understudied component of musicology and therefore contributes significantly to the future of Artificial Intelligence (AI) music generation.
Class-Adaptive Sampling Policy for Efficient Continual Learning
Nov 27, 2023Continual learning (CL) aims to acquire new knowledge while preserving information from previous experiences without forgetting. Though buffer-based methods (i.e., retaining samples from previous tasks) have achieved acceptable performance, determining how to allocate the buffer remains a critical challenge. Most recent research focuses on refining these methods but often fails to sufficiently consider the varying influence of samples on the learning process, and frequently overlooks the complexity of the classes/concepts being learned. Generally, these methods do not directly take into account the contribution of individual classes. However, our investigation indicates that more challenging classes necessitate preserving a larger number of samples compared to less challenging ones. To address this issue, we propose a novel method and policy named 'Class-Adaptive Sampling Policy' (CASP), which dynamically allocates storage space within the buffer. By utilizing concepts of class contribution and difficulty, CASP adaptively manages buffer space, allowing certain classes to occupy a larger portion of the buffer while reducing storage for others. This approach significantly improves the efficiency of knowledge retention and utilization. CASP provides a versatile solution to boost the performance and efficiency of CL. It meets the demand for dynamic buffer allocation, accommodating the varying contributions of different classes and their learning complexities over time.
Graph-Guided Reasoning for Multi-Hop Question Answering in Large Language Models
Nov 16, 2023Chain-of-Thought (CoT) prompting has boosted the multi-step reasoning capabilities of Large Language Models (LLMs) by generating a series of rationales before the final answer. We analyze the reasoning paths generated by CoT and find two issues in multi-step reasoning: (i) Generating rationales irrelevant to the question, (ii) Unable to compose subquestions or queries for generating/retrieving all the relevant information. To address them, we propose a graph-guided CoT prompting method, which guides the LLMs to reach the correct answer with graph representation/verification steps. Specifically, we first leverage LLMs to construct a "question/rationale graph" by using knowledge extraction prompting given the initial question and the rationales generated in the previous steps. Then, the graph verification step diagnoses the current rationale triplet by comparing it with the existing question/rationale graph to filter out irrelevant rationales and generate follow-up questions to obtain relevant information. Additionally, we generate CoT paths that exclude the extracted graph information to represent the context information missed from the graph extraction. Our graph-guided reasoning method shows superior performance compared to previous CoT prompting and the variants on multi-hop question answering benchmark datasets.
Analysing the Impact of Removing Infrequent Words on Topic Quality in LDA Models
Nov 24, 2023An initial procedure in text-as-data applications is text preprocessing. One of the typical steps, which can substantially facilitate computations, consists in removing infrequent words believed to provide limited information about the corpus. Despite popularity of vocabulary pruning, not many guidelines on how to implement it are available in the literature. The aim of the paper is to fill this gap by examining the effects of removing infrequent words for the quality of topics estimated using Latent Dirichlet Allocation. The analysis is based on Monte Carlo experiments taking into account different criteria for infrequent terms removal and various evaluation metrics. The results indicate that pruning is beneficial and that the share of vocabulary which might be eliminated can be quite considerable.
The Open Review-Based (ORB) dataset: Towards Automatic Assessment of Scientific Papers and Experiment Proposals in High-Energy Physics
Nov 29, 2023With the Open Science approach becoming important for research, the evolution towards open scientific-paper reviews is making an impact on the scientific community. However, there is a lack of publicly available resources for conducting research activities related to this subject, as only a limited number of journals and conferences currently allow access to their review process for interested parties. In this paper, we introduce the new comprehensive Open Review-Based dataset (ORB); it includes a curated list of more than 36,000 scientific papers with their more than 89,000 reviews and final decisions. We gather this information from two sources: the OpenReview.net and SciPost.org websites. However, given the volatile nature of this domain, the software infrastructure that we introduce to supplement the ORB dataset is designed to accommodate additional resources in the future. The ORB deliverables include (1) Python code (interfaces and implementations) to translate document data and metadata into a structured and high-level representation, (2) an ETL process (Extract, Transform, Load) to facilitate the automatic updates from defined sources and (3) data files representing the structured data. The paper presents our data architecture and an overview of the collected data along with relevant statistics. For illustration purposes, we also discuss preliminary Natural-Language-Processing-based experiments that aim to predict (1) papers' acceptance based on their textual embeddings, and (2) grading statistics inferred from embeddings as well. We believe ORB provides a valuable resource for researchers interested in open science and review, with our implementation easing the use of this data for further analysis and experimentation. We plan to update ORB as the field matures as well as introduce new resources even more fitted to dedicated scientific domains such as High-Energy Physics.
BiHRNet: A Binary high-resolution network for Human Pose Estimation
Nov 17, 2023Human Pose Estimation (HPE) plays a crucial role in computer vision applications. However, it is difficult to deploy state-of-the-art models on resouce-limited devices due to the high computational costs of the networks. In this work, a binary human pose estimator named BiHRNet(Binary HRNet) is proposed, whose weights and activations are expressed as $\pm$1. BiHRNet retains the keypoint extraction ability of HRNet, while using fewer computing resources by adapting binary neural network (BNN). In order to reduce the accuracy drop caused by network binarization, two categories of techniques are proposed in this work. For optimizing the training process for binary pose estimator, we propose a new loss function combining KL divergence loss with AWing loss, which makes the binary network obtain more comprehensive output distribution from its real-valued counterpart to reduce information loss caused by binarization. For designing more binarization-friendly structures, we propose a new information reconstruction bottleneck called IR Bottleneck to retain more information in the initial stage of the network. In addition, we also propose a multi-scale basic block called MS-Block for information retention. Our work has less computation cost with few precision drop. Experimental results demonstrate that BiHRNet achieves a PCKh of 87.9 on the MPII dataset, which outperforms all binary pose estimation networks. On the challenging of COCO dataset, the proposed method enables the binary neural network to achieve 70.8 mAP, which is better than most tested lightweight full-precision networks.
Mobile-Seed: Joint Semantic Segmentation and Boundary Detection for Mobile Robots
Nov 23, 2023Precise and rapid delineation of sharp boundaries and robust semantics is essential for numerous downstream robotic tasks, such as robot grasping and manipulation, real-time semantic mapping, and online sensor calibration performed on edge computing units. Although boundary detection and semantic segmentation are complementary tasks, most studies focus on lightweight models for semantic segmentation but overlook the critical role of boundary detection. In this work, we introduce Mobile-Seed, a lightweight, dual-task framework tailored for simultaneous semantic segmentation and boundary detection. Our framework features a two-stream encoder, an active fusion decoder (AFD) and a dual-task regularization approach. The encoder is divided into two pathways: one captures category-aware semantic information, while the other discerns boundaries from multi-scale features. The AFD module dynamically adapts the fusion of semantic and boundary information by learning channel-wise relationships, allowing for precise weight assignment of each channel. Furthermore, we introduce a regularization loss to mitigate the conflicts in dual-task learning and deep diversity supervision. Compared to existing methods, the proposed Mobile-Seed offers a lightweight framework to simultaneously improve semantic segmentation performance and accurately locate object boundaries. Experiments on the Cityscapes dataset have shown that Mobile-Seed achieves notable improvement over the state-of-the-art (SOTA) baseline by 2.2 percentage points (pp) in mIoU and 4.2 pp in mF-score, while maintaining an online inference speed of 23.9 frames-per-second (FPS) with 1024x2048 resolution input on an RTX 2080 Ti GPU. Additional experiments on CamVid and PASCAL Context datasets confirm our method's generalizability. Code and additional results are publicly available at https://whu-usi3dv.github.io/Mobile-Seed/.
Multiscale information fusion for fault detection and localization of battery energy storage systems
Oct 17, 2023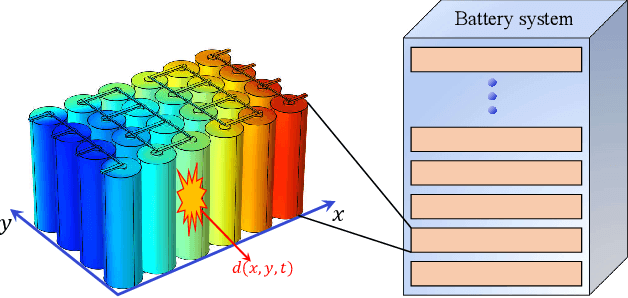
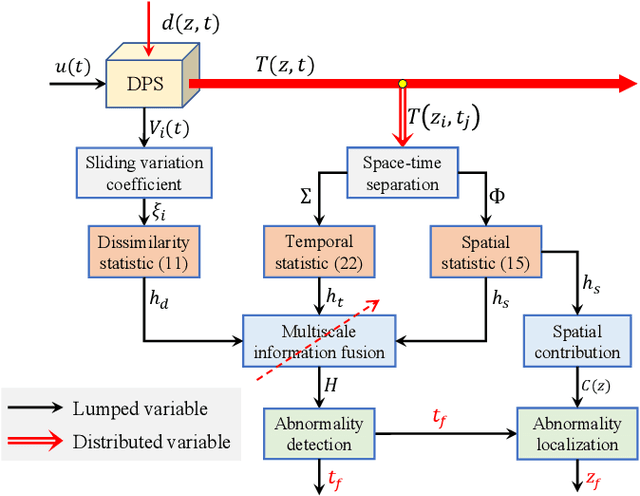
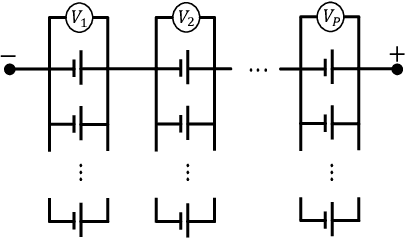

Battery energy storage system (BESS) has great potential to combat global warming. However, internal abnormalities in the BESS may develop into thermal runaway, causing serious safety incidents. In this study, the multiscale information fusion is proposed for thermal abnormality detection and localization in BESSs. We introduce the concept of dissimilarity entropy as a means to identify anomalies for lumped variables, whereas spatial and temporal entropy measures are presented for the detection of anomalies for distributed variables. Through appropriate parameter optimization, these three entropy functions are integrated into the comprehensive multiscale detection index, which outperforms traditional single-scale detection methods. The proposed multiscale statistic has good interpretability in terms of system energy concentration. Battery system internal short circuit (ISC) experiments have demonstrated that our proposed method can swiftly identify ISC abnormalities and accurately pinpoint the problematic battery cells.
Large Model Based Referring Camouflaged Object Detection
Nov 28, 2023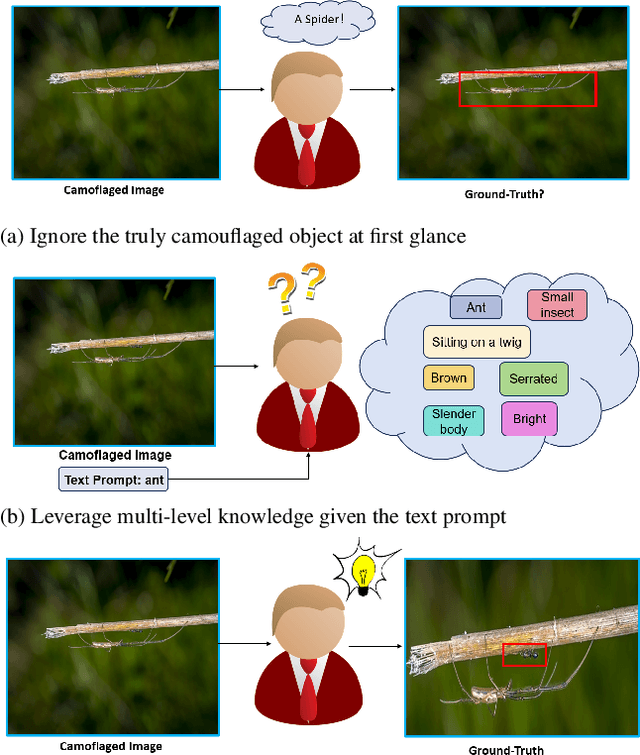
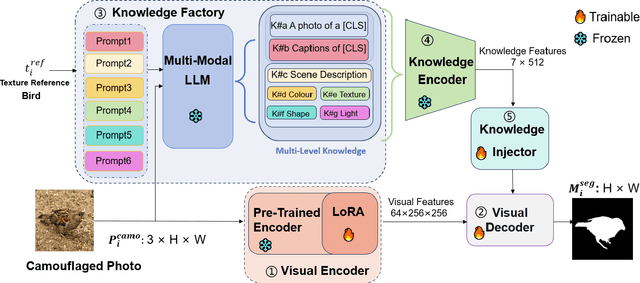

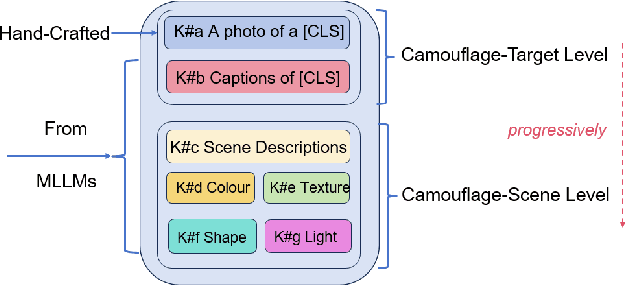
Referring camouflaged object detection (Ref-COD) is a recently-proposed problem aiming to segment out specified camouflaged objects matched with a textual or visual reference. This task involves two major challenges: the COD domain-specific perception and multimodal reference-image alignment. Our motivation is to make full use of the semantic intelligence and intrinsic knowledge of recent Multimodal Large Language Models (MLLMs) to decompose this complex task in a human-like way. As language is highly condensed and inductive, linguistic expression is the main media of human knowledge learning, and the transmission of knowledge information follows a multi-level progression from simplicity to complexity. In this paper, we propose a large-model-based Multi-Level Knowledge-Guided multimodal method for Ref-COD termed MLKG, where multi-level knowledge descriptions from MLLM are organized to guide the large vision model of segmentation to perceive the camouflage-targets and camouflage-scene progressively and meanwhile deeply align the textual references with camouflaged photos. To our knowledge, our contributions mainly include: (1) This is the first time that the MLLM knowledge is studied for Ref-COD and COD. (2) We, for the first time, propose decomposing Ref-COD into two main perspectives of perceiving the target and scene by integrating MLLM knowledge, and contribute a multi-level knowledge-guided method. (3) Our method achieves the state-of-the-art on the Ref-COD benchmark outperforming numerous strong competitors. Moreover, thanks to the injected rich knowledge, it demonstrates zero-shot generalization ability on uni-modal COD datasets. We will release our code soon.