 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Pre-training and Prompt Learning for Recommendation
Nov 28, 2023
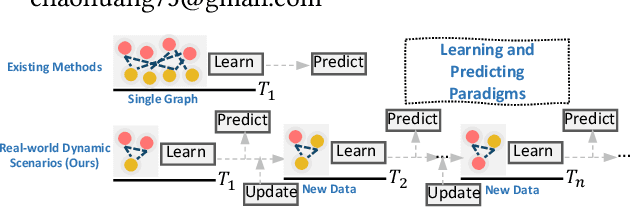
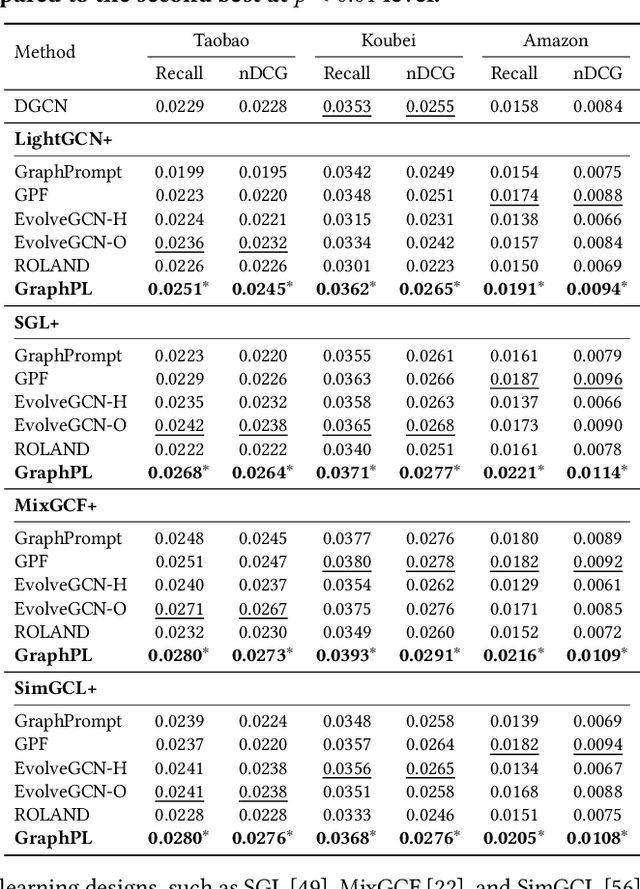
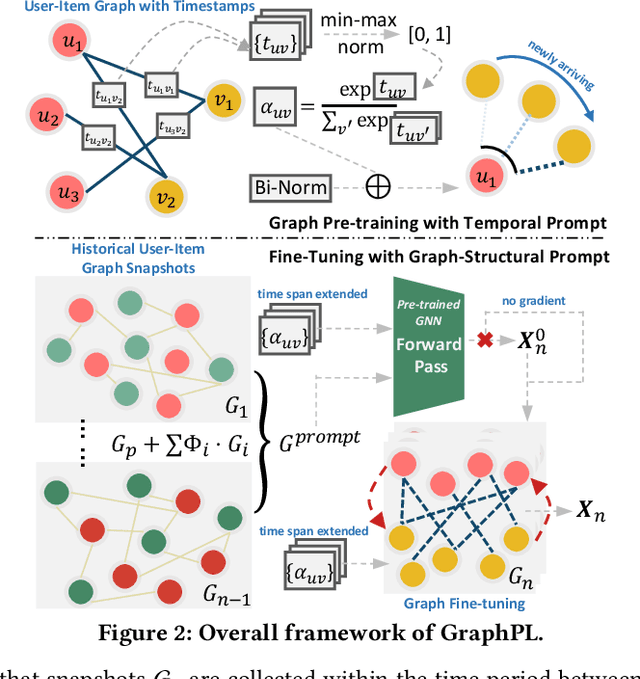
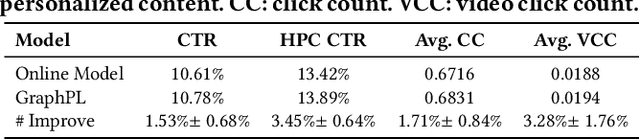
GNN-based recommenders have excelled in modeling intricate user-item interactions through multi-hop message passing. However, existing methods often overlook the dynamic nature of evolving user-item interactions, which impedes the adaption to changing user preferences and distribution shifts in newly arriving data. Thus, their scalability and performances in real-world dynamic environments are limited. In this study, we propose GraphPL, a framework that incorporates parameter-efficient and dynamic graph pre-training with prompt learning. This novel combination empowers GNNs to effectively capture both long-term user preferences and short-term behavior dynamics, enabling the delivery of accurate and timely recommendations. Our GraphPL framework addresses the challenge of evolving user preferences by seamlessly integrating a temporal prompt mechanism and a graph-structural prompt learning mechanism into the pre-trained GNN model. The temporal prompt mechanism encodes time information on user-item interaction, allowing the model to naturally capture temporal context, while the graph-structural prompt learning mechanism enables the transfer of pre-trained knowledge to adapt to behavior dynamics without the need for continuous incremental training. We further bring in a dynamic evaluation setting for recommendation to mimic real-world dynamic scenarios and bridge the offline-online gap to a better level. Our extensive experiments including a large-scale industrial deployment showcases the lightweight plug-in scalability of our GraphPL when integrated with various state-of-the-art recommenders, emphasizing the advantages of GraphPL in terms of effectiveness, robustness and efficiency.
Beyond Labels: Advancing Cluster Analysis with the Entropy of Distance Distribution (EDD)
Nov 28, 2023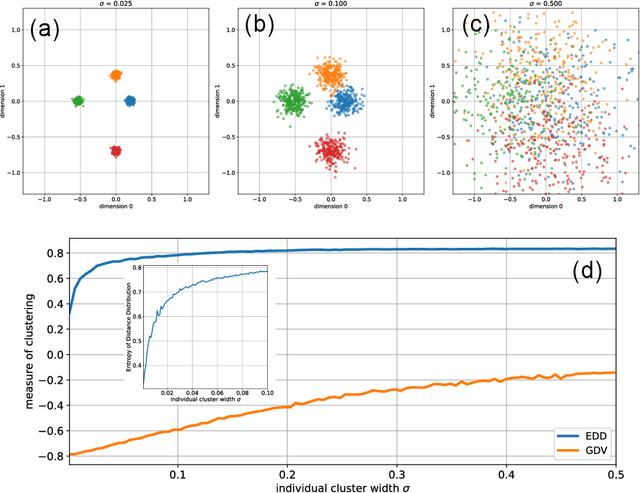
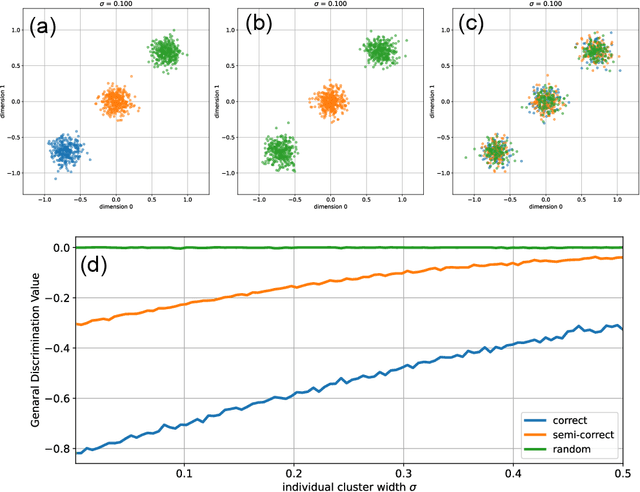
In the evolving landscape of data science, the accurate quantification of clustering in high-dimensional data sets remains a significant challenge, especially in the absence of predefined labels. This paper introduces a novel approach, the Entropy of Distance Distribution (EDD), which represents a paradigm shift in label-free clustering analysis. Traditional methods, reliant on discrete labels, often struggle to discern intricate cluster patterns in unlabeled data. EDD, however, leverages the characteristic differences in pairwise point-to-point distances to discern clustering tendencies, independent of data labeling. Our method employs the Shannon information entropy to quantify the 'peakedness' or 'flatness' of distance distributions in a data set. This entropy measure, normalized against its maximum value, effectively distinguishes between strongly clustered data (indicated by pronounced peaks in distance distribution) and more homogeneous, non-clustered data sets. This label-free quantification is resilient against global translations and permutations of data points, and with an additional dimension-wise z-scoring, it becomes invariant to data set scaling. We demonstrate the efficacy of EDD through a series of experiments involving two-dimensional data spaces with Gaussian cluster centers. Our findings reveal a monotonic increase in the EDD value with the widening of cluster widths, moving from well-separated to overlapping clusters. This behavior underscores the method's sensitivity and accuracy in detecting varying degrees of clustering. EDD's potential extends beyond conventional clustering analysis, offering a robust, scalable tool for unraveling complex data structures without reliance on pre-assigned labels.
DoubleAUG: Single-domain Generalized Object Detector in Urban via Color Perturbation and Dual-style Memory
Nov 22, 2023

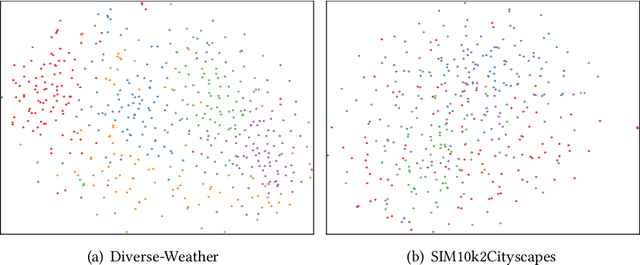
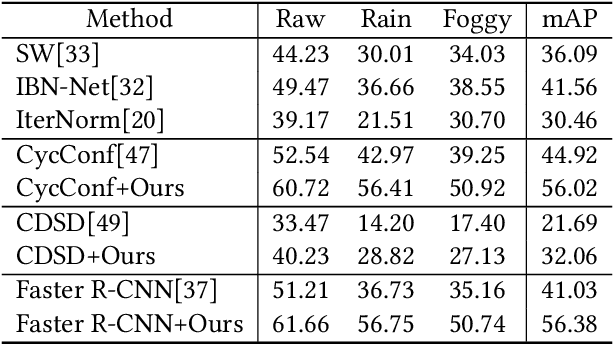
Object detection in urban scenarios is crucial for autonomous driving in intelligent traffic systems. However, unlike conventional object detection tasks, urban-scene images vary greatly in style. For example, images taken on sunny days differ significantly from those taken on rainy days. Therefore, models trained on sunny day images may not generalize well to rainy day images. In this paper, we aim to solve the single-domain generalizable object detection task in urban scenarios, meaning that a model trained on images from one weather condition should be able to perform well on images from any other weather conditions. To address this challenge, we propose a novel Double AUGmentation (DoubleAUG) method that includes image- and feature-level augmentation schemes. In the image-level augmentation, we consider the variation in color information across different weather conditions and propose a Color Perturbation (CP) method that randomly exchanges the RGB channels to generate various images. In the feature-level augmentation, we propose to utilize a Dual-Style Memory (DSM) to explore the diverse style information on the entire dataset, further enhancing the model's generalization capability. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art methods. Furthermore, ablation studies confirm the effectiveness of each module in our proposed method. Moreover, our method is plug-and-play and can be integrated into existing methods to further improve model performance.
Pi-DUAL: Using Privileged Information to Distinguish Clean from Noisy Labels
Oct 10, 2023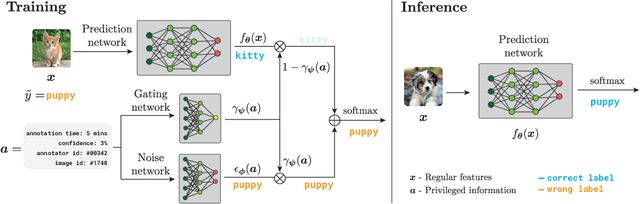

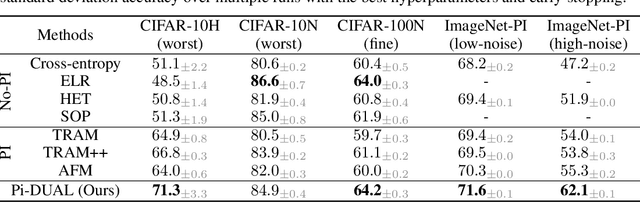
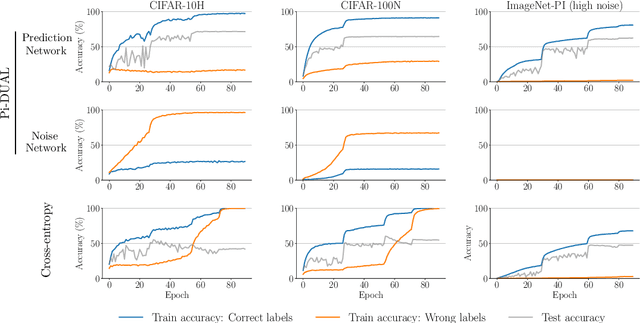
Label noise is a pervasive problem in deep learning that often compromises the generalization performance of trained models. Recently, leveraging privileged information (PI) -- information available only during training but not at test time -- has emerged as an effective approach to mitigate this issue. Yet, existing PI-based methods have failed to consistently outperform their no-PI counterparts in terms of preventing overfitting to label noise. To address this deficiency, we introduce Pi-DUAL, an architecture designed to harness PI to distinguish clean from wrong labels. Pi-DUAL decomposes the output logits into a prediction term, based on conventional input features, and a noise-fitting term influenced solely by PI. A gating mechanism steered by PI adaptively shifts focus between these terms, allowing the model to implicitly separate the learning paths of clean and wrong labels. Empirically, Pi-DUAL achieves significant performance improvements on key PI benchmarks (e.g., +6.8% on ImageNet-PI), establishing a new state-of-the-art test set accuracy. Additionally, Pi-DUAL is a potent method for identifying noisy samples post-training, outperforming other strong methods at this task. Overall, Pi-DUAL is a simple, scalable and practical approach for mitigating the effects of label noise in a variety of real-world scenarios with PI.
Analysis of Visual Features for Continuous Lipreading in Spanish
Nov 21, 2023During a conversation, our brain is responsible for combining information obtained from multiple senses in order to improve our ability to understand the message we are perceiving. Different studies have shown the importance of presenting visual information in these situations. Nevertheless, lipreading is a complex task whose objective is to interpret speech when audio is not available. By dispensing with a sense as crucial as hearing, it will be necessary to be aware of the challenge that this lack presents. In this paper, we propose an analysis of different speech visual features with the intention of identifying which of them is the best approach to capture the nature of lip movements for natural Spanish and, in this way, dealing with the automatic visual speech recognition task. In order to estimate our system, we present an audiovisual corpus compiled from a subset of the RTVE database, which has been used in the Albayz\'in evaluations. We employ a traditional system based on Hidden Markov Models with Gaussian Mixture Models. Results show that, although the task is difficult, in restricted conditions we obtain recognition results which determine that using eigenlips in combination with deep features is the best visual approach.
Trustworthy AI: Deciding What to Decide
Nov 21, 2023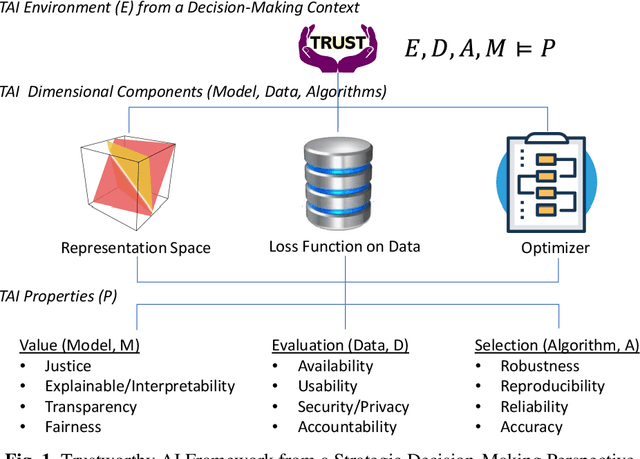


When engaging in strategic decision-making, we are frequently confronted with overwhelming information and data. The situation can be further complicated when certain pieces of evidence contradict each other or become paradoxical. The primary challenge is how to determine which information can be trusted when we adopt Artificial Intelligence (AI) systems for decision-making. This issue is known as deciding what to decide or Trustworthy AI. However, the AI system itself is often considered an opaque black box. We propose a new approach to address this issue by introducing a novel framework of Trustworthy AI (TAI) encompassing three crucial components of AI: representation space, loss function, and optimizer. Each component is loosely coupled with four TAI properties. Altogether, the framework consists of twelve TAI properties. We aim to use this framework to conduct the TAI experiments by quantitive and qualitative research methods to satisfy TAI properties for the decision-making context. The framework allows us to formulate an optimal prediction model trained by the given dataset for applying the strategic investment decision of credit default swaps (CDS) in the technology sector. Finally, we provide our view of the future direction of TAI research
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
Nov 26, 2023Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
An Intelligent-Detection Network for Handwritten Mathematical Expression Recognition
Nov 26, 2023

The use of artificial intelligence technology in education is growing rapidly, with increasing attention being paid to handwritten mathematical expression recognition (HMER) by researchers. However, many existing methods for HMER may fail to accurately read formulas with complex structures, as the attention results can be inaccurate due to illegible handwriting or large variations in writing styles. Our proposed Intelligent-Detection Network (IDN) for HMER differs from traditional encoder-decoder methods by utilizing object detection techniques. Specifically, we have developed an enhanced YOLOv7 network that can accurately detect both digital and symbolic objects. The detection results are then integrated into the bidirectional gated recurrent unit (BiGRU) and the baseline symbol relationship tree (BSRT) to determine the relationships between symbols and numbers. The experiments demonstrate that the proposed method outperforms those encoder-decoder networks in recognizing complex handwritten mathematical expressions. This is due to the precise detection of symbols and numbers. Our research has the potential to make valuable contributions to the field of HMER. This could be applied in various practical scenarios, such as assignment grading in schools and information entry of paper documents.
Emerging Drug Interaction Prediction Enabled by Flow-based Graph Neural Network with Biomedical Network
Nov 15, 2023Accurately predicting drug-drug interactions (DDI) for emerging drugs, which offer possibilities for treating and alleviating diseases, with computational methods can improve patient care and contribute to efficient drug development. However, many existing computational methods require large amounts of known DDI information, which is scarce for emerging drugs. In this paper, we propose EmerGNN, a graph neural network (GNN) that can effectively predict interactions for emerging drugs by leveraging the rich information in biomedical networks. EmerGNN learns pairwise representations of drugs by extracting the paths between drug pairs, propagating information from one drug to the other, and incorporating the relevant biomedical concepts on the paths. The different edges on the biomedical network are weighted to indicate the relevance for the target DDI prediction. Overall, EmerGNN has higher accuracy than existing approaches in predicting interactions for emerging drugs and can identify the most relevant information on the biomedical network.
Fine-grained Appearance Transfer with Diffusion Models
Nov 27, 2023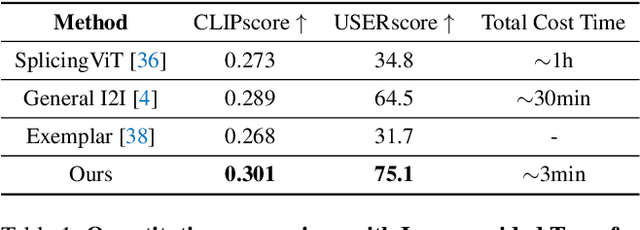

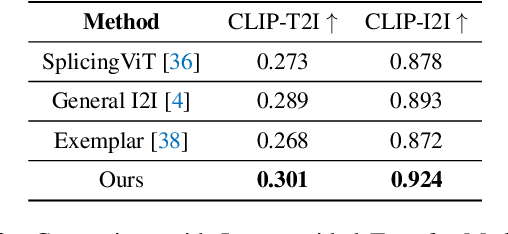
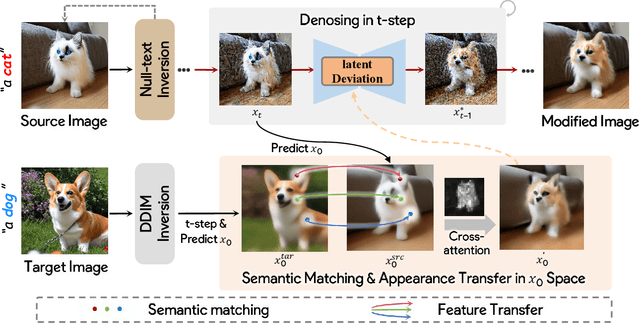
Image-to-image translation (I2I), and particularly its subfield of appearance transfer, which seeks to alter the visual appearance between images while maintaining structural coherence, presents formidable challenges. Despite significant advancements brought by diffusion models, achieving fine-grained transfer remains complex, particularly in terms of retaining detailed structural elements and ensuring information fidelity. This paper proposes an innovative framework designed to surmount these challenges by integrating various aspects of semantic matching, appearance transfer, and latent deviation. A pivotal aspect of our approach is the strategic use of the predicted $x_0$ space by diffusion models within the latent space of diffusion processes. This is identified as a crucial element for the precise and natural transfer of fine-grained details. Our framework exploits this space to accomplish semantic alignment between source and target images, facilitating mask-wise appearance transfer for improved feature acquisition. A significant advancement of our method is the seamless integration of these features into the latent space, enabling more nuanced latent deviations without necessitating extensive model retraining or fine-tuning. The effectiveness of our approach is demonstrated through extensive experiments, which showcase its ability to adeptly handle fine-grained appearance transfers across a wide range of categories and domains. We provide our code at https://github.com/babahui/Fine-grained-Appearance-Transfer