 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Edge AI for Internet of Energy: Challenges and Perspectives
Nov 28, 2023
The digital landscape of the Internet of Energy (IoE) is on the brink of a revolutionary transformation with the integration of edge Artificial Intelligence (AI). This comprehensive review elucidates the promise and potential that edge AI holds for reshaping the IoE ecosystem. Commencing with a meticulously curated research methodology, the article delves into the myriad of edge AI techniques specifically tailored for IoE. The myriad benefits, spanning from reduced latency and real-time analytics to the pivotal aspects of information security, scalability, and cost-efficiency, underscore the indispensability of edge AI in modern IoE frameworks. As the narrative progresses, readers are acquainted with pragmatic applications and techniques, highlighting on-device computation, secure private inference methods, and the avant-garde paradigms of AI training on the edge. A critical analysis follows, offering a deep dive into the present challenges including security concerns, computational hurdles, and standardization issues. However, as the horizon of technology ever expands, the review culminates in a forward-looking perspective, envisaging the future symbiosis of 5G networks, federated edge AI, deep reinforcement learning, and more, painting a vibrant panorama of what the future beholds. For anyone vested in the domains of IoE and AI, this review offers both a foundation and a visionary lens, bridging the present realities with future possibilities.
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Nov 28, 2023In the realm of large multi-modal models (LMMs), efficient modality alignment is crucial yet often constrained by the scarcity of high-quality image-text data. To address this bottleneck, we introduce the ShareGPT4V dataset, a pioneering large-scale resource featuring 1.2 million highly descriptive captions, which surpasses existing datasets in diversity and information content, covering world knowledge, object properties, spatial relationships, and aesthetic evaluations. Specifically, ShareGPT4V originates from a curated 100K high-quality captions collected from advanced GPT4-Vision and has been expanded to 1.2M with a superb caption model trained on this subset. ShareGPT4V first demonstrates its effectiveness for the Supervised Fine-Tuning (SFT) phase, by substituting an equivalent quantity of detailed captions in existing SFT datasets with a subset of our high-quality captions, significantly enhancing the LMMs like LLaVA-7B, LLaVA-1.5-13B, and Qwen-VL-Chat-7B on the MME and MMBench benchmarks, with respective gains of 222.8/22.0/22.3 and 2.7/1.3/1.5. We further incorporate ShareGPT4V data into both the pre-training and SFT phases, obtaining ShareGPT4V-7B, a superior LMM based on a simple architecture that has remarkable performance across a majority of the multi-modal benchmarks. This project is available at https://ShareGPT4V.github.io to serve as a pivotal resource for advancing the LMMs community.
Improving Image Captioning via Predicting Structured Concepts
Nov 28, 2023Having the difficulty of solving the semantic gap between images and texts for the image captioning task, conventional studies in this area paid some attention to treating semantic concepts as a bridge between the two modalities and improved captioning performance accordingly. Although promising results on concept prediction were obtained, the aforementioned studies normally ignore the relationship among concepts, which relies on not only objects in the image, but also word dependencies in the text, so that offers a considerable potential for improving the process of generating good descriptions. In this paper, we propose a structured concept predictor (SCP) to predict concepts and their structures, then we integrate them into captioning, so as to enhance the contribution of visual signals in this task via concepts and further use their relations to distinguish cross-modal semantics for better description generation. Particularly, we design weighted graph convolutional networks (W-GCN) to depict concept relations driven by word dependencies, and then learns differentiated contributions from these concepts for following decoding process. Therefore, our approach captures potential relations among concepts and discriminatively learns different concepts, so that effectively facilitates image captioning with inherited information across modalities. Extensive experiments and their results demonstrate the effectiveness of our approach as well as each proposed module in this work.
Enhancing Cross-domain Click-Through Rate Prediction via Explicit Feature Augmentation
Nov 30, 2023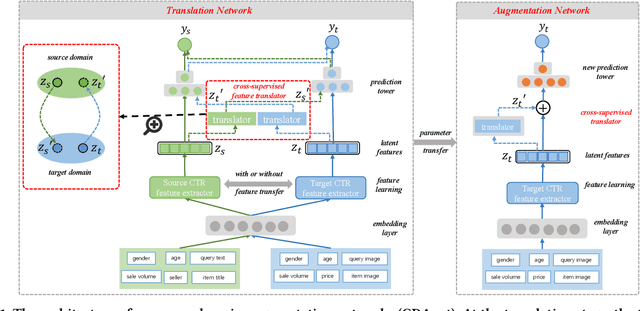
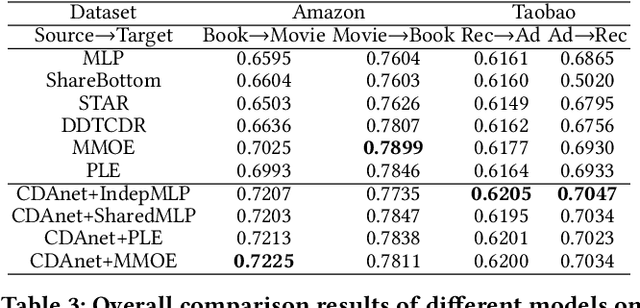
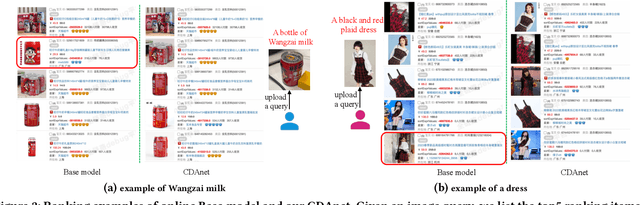

Cross-domain CTR (CDCTR) prediction is an important research topic that studies how to leverage meaningful data from a related domain to help CTR prediction in target domain. Most existing CDCTR works design implicit ways to transfer knowledge across domains such as parameter-sharing that regularizes the model training in target domain. More effectively, recent researchers propose explicit techniques to extract user interest knowledge and transfer this knowledge to target domain. However, the proposed method mainly faces two issues: 1) it usually requires a super domain, i.e. an extremely large source domain, to cover most users or items of target domain, and 2) the extracted user interest knowledge is static no matter what the context is in target domain. These limitations motivate us to develop a more flexible and efficient technique to explicitly transfer knowledge. In this work, we propose a cross-domain augmentation network (CDAnet) being able to perform explicit knowledge transfer between two domains. Specifically, CDAnet contains a designed translation network and an augmentation network which are trained sequentially. The translation network computes latent features from two domains and learns meaningful cross-domain knowledge of each input in target domain by using a designed cross-supervised feature translator. Later the augmentation network employs the explicit cross-domain knowledge as augmented information to boost the target domain CTR prediction. Through extensive experiments on two public benchmarks and one industrial production dataset, we show CDAnet can learn meaningful translated features and largely improve the performance of CTR prediction. CDAnet has been conducted online A/B test in image2product retrieval at Taobao app, bringing an absolute 0.11 point CTR improvement, a relative 0.64% deal growth and a relative 1.26% GMV increase.
Text Sanitization Beyond Specific Domains: Zero-Shot Redaction & Substitution with Large Language Models
Nov 16, 2023In the context of information systems, text sanitization techniques are used to identify and remove sensitive data to comply with security and regulatory requirements. Even though many methods for privacy preservation have been proposed, most of them are focused on the detection of entities from specific domains (e.g., credit card numbers, social security numbers), lacking generality and requiring customization for each desirable domain. Moreover, removing words is, in general, a drastic measure, as it can degrade text coherence and contextual information. Less severe measures include substituting a word for a safe alternative, yet it can be challenging to automatically find meaningful substitutions. We present a zero-shot text sanitization technique that detects and substitutes potentially sensitive information using Large Language Models. Our evaluation shows that our method excels at protecting privacy while maintaining text coherence and contextual information, preserving data utility for downstream tasks.
Mastering the Task of Open Information Extraction with Large Language Models and Consistent Reasoning Environment
Oct 16, 2023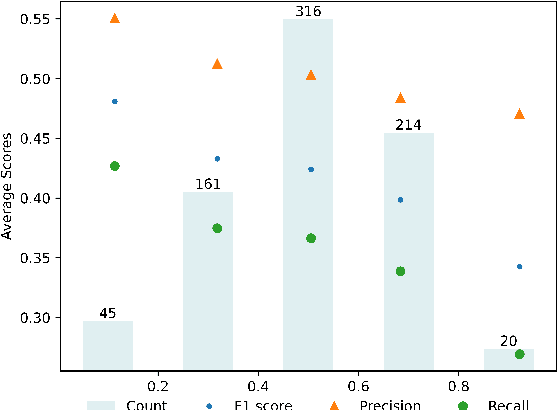
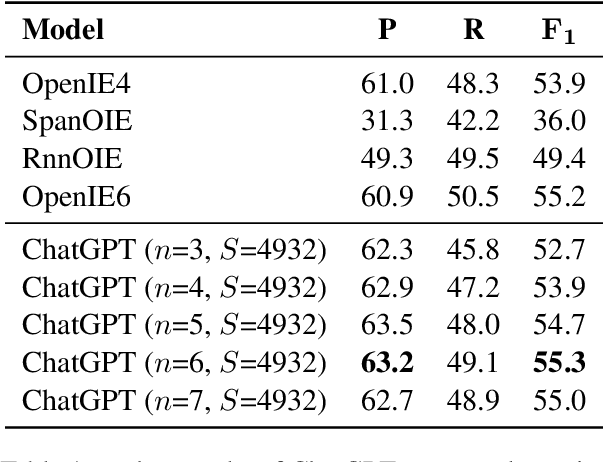
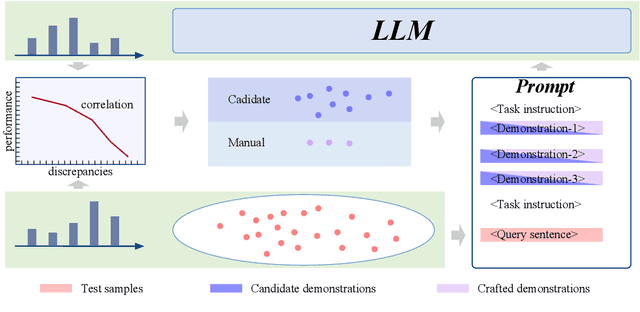

Open Information Extraction (OIE) aims to extract objective structured knowledge from natural texts, which has attracted growing attention to build dedicated models with human experience. As the large language models (LLMs) have exhibited remarkable in-context learning capabilities, a question arises as to whether the task of OIE can be effectively tackled with this paradigm? In this paper, we explore solving the OIE problem by constructing an appropriate reasoning environment for LLMs. Specifically, we first propose a method to effectively estimate the discrepancy of syntactic distribution between a LLM and test samples, which can serve as correlation evidence for preparing positive demonstrations. Upon the evidence, we introduce a simple yet effective mechanism to establish the reasoning environment for LLMs on specific tasks. Without bells and whistles, experimental results on the standard CaRB benchmark demonstrate that our $6$-shot approach outperforms state-of-the-art supervised method, achieving an $55.3$ $F_1$ score. Further experiments on TACRED and ACE05 show that our method can naturally generalize to other information extraction tasks, resulting in improvements of $5.7$ and $6.8$ $F_1$ scores, respectively.
Uncertainty Quantification in Neural-Network Based Pain Intensity Estimation
Nov 29, 2023Improper pain management can lead to severe physical or mental consequences, including suffering, and an increased risk of opioid dependency. Assessing the presence and severity of pain is imperative to prevent such outcomes and determine the appropriate intervention. However, the evaluation of pain intensity is challenging because different individuals experience pain differently. To overcome this, researchers have employed machine learning models to evaluate pain intensity objectively. However, these efforts have primarily focused on point estimation of pain, disregarding the inherent uncertainty and variability present in the data and model. Consequently, the point estimates provide only partial information for clinical decision-making. This study presents a neural network-based method for objective pain interval estimation, incorporating uncertainty quantification. This work explores three algorithms: the bootstrap method, lower and upper bound estimation (LossL) optimized by genetic algorithm, and modified lower and upper bound estimation (LossS) optimized by gradient descent algorithm. Our empirical results reveal that LossS outperforms the other two by providing a narrower prediction interval. As LossS outperforms, we assessed its performance in three different scenarios for pain assessment: (1) a generalized approach (single model for the entire population), (2) a personalized approach (separate model for each individual), and (3) a hybrid approach (separate model for each cluster of individuals). Our findings demonstrate the hybrid approach's superior performance, with notable practicality in clinical contexts. It has the potential to be a valuable tool for clinicians, enabling objective pain intensity assessment while taking uncertainty into account. This capability is crucial in facilitating effective pain management and reducing the risks associated with improper treatment.
Domain Knowledge Injection in Bayesian Search for New Materials
Nov 26, 2023
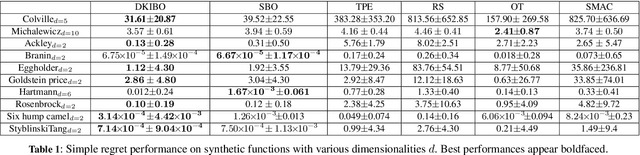
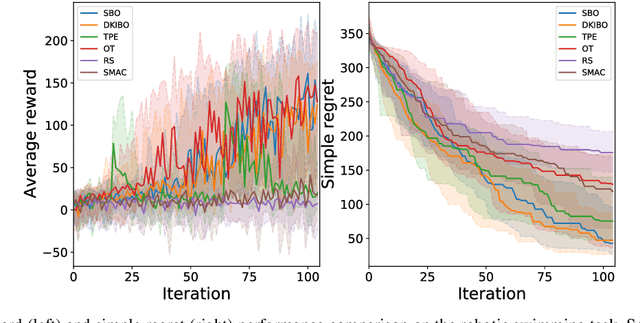
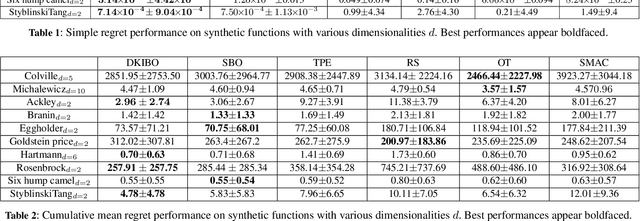
In this paper we propose DKIBO, a Bayesian optimization (BO) algorithm that accommodates domain knowledge to tune exploration in the search space. Bayesian optimization has recently emerged as a sample-efficient optimizer for many intractable scientific problems. While various existing BO frameworks allow the input of prior beliefs to accelerate the search by narrowing down the space, incorporating such knowledge is not always straightforward and can often introduce bias and lead to poor performance. Here we propose a simple approach to incorporate structural knowledge in the acquisition function by utilizing an additional deterministic surrogate model to enrich the approximation power of the Gaussian process. This is suitably chosen according to structural information of the problem at hand and acts a corrective term towards a better-informed sampling. We empirically demonstrate the practical utility of the proposed method by successfully injecting domain knowledge in a materials design task. We further validate our method's performance on different experimental settings and ablation analyses.
* 8 pages, 5 figures, published in ECAI23
Leveraging Unlabeled Data for 3D Medical Image Segmentation through Self-Supervised Contrastive Learning
Nov 21, 2023Current 3D semi-supervised segmentation methods face significant challenges such as limited consideration of contextual information and the inability to generate reliable pseudo-labels for effective unsupervised data use. To address these challenges, we introduce two distinct subnetworks designed to explore and exploit the discrepancies between them, ultimately correcting the erroneous prediction results. More specifically, we identify regions of inconsistent predictions and initiate a targeted verification training process. This procedure strategically fine-tunes and harmonizes the predictions of the subnetworks, leading to enhanced utilization of contextual information. Furthermore, to adaptively fine-tune the network's representational capacity and reduce prediction uncertainty, we employ a self-supervised contrastive learning paradigm. For this, we use the network's confidence to distinguish between reliable and unreliable predictions. The model is then trained to effectively minimize unreliable predictions. Our experimental results for organ segmentation, obtained from clinical MRI and CT scans, demonstrate the effectiveness of our approach when compared to state-of-the-art methods. The codebase is accessible on \href{https://github.com/xmindflow/SSL-contrastive}{GitHub}.
AR Visualization System for Ship Detection and Recognition Based on AI
Nov 21, 2023Augmented reality technology has been widely used in industrial design interaction, exhibition guide, information retrieval and other fields. The combination of artificial intelligence and augmented reality technology has also become a future development trend. This project is an AR visualization system for ship detection and recognition based on AI, which mainly includes three parts: artificial intelligence module, Unity development module and Hololens2AR module. This project is based on R3Det algorithm to complete the detection and recognition of ships in remote sensing images. The recognition rate of model detection trained on RTX 2080Ti can reach 96%. Then, the 3D model of the ship is obtained by ship categories and information and generated in the virtual scene. At the same time, voice module and UI interaction module are added. Finally, we completed the deployment of the project on Hololens2 through MRTK. The system realizes the fusion of computer vision and augmented reality technology, which maps the results of object detection to the AR field, and makes a brave step toward the future technological trend and intelligent application.