 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inter-object Discriminative Graph Modeling for Indoor Scene Recognition
Nov 13, 2023
Variable scene layouts and coexisting objects across scenes make indoor scene recognition still a challenging task. Leveraging object information within scenes to enhance the distinguishability of feature representations has emerged as a key approach in this domain. Currently, most object-assisted methods use a separate branch to process object information, combining object and scene features heuristically. However, few of them pay attention to interpretably handle the hidden discriminative knowledge within object information. In this paper, we propose to leverage discriminative object knowledge to enhance scene feature representations. Initially, we capture the object-scene discriminative relationships from a probabilistic perspective, which are transformed into an Inter-Object Discriminative Prototype (IODP). Given the abundant prior knowledge from IODP, we subsequently construct a Discriminative Graph Network (DGN), in which pixel-level scene features are defined as nodes and the discriminative relationships between node features are encoded as edges. DGN aims to incorporate inter-object discriminative knowledge into the image representation through graph convolution. With the proposed IODP and DGN, we obtain state-of-the-art results on several widely used scene datasets, demonstrating the effectiveness of the proposed approach.
Collaborative Goal Tracking of Multiple Mobile Robots Based on Geometric Graph Neural Network
Nov 13, 2023Multi-robot systems are widely used in spatially distributed tasks, and their collaborative path planning is of great significance for working efficiency. Currently, different multi-robot collaborative path planning methods have been proposed, but how to process the sensory information of neighboring robots at different locations from a local perception perspective in real environment to make better decisions is still a major difficulty. To address this problem, this paper proposes a multi-robot collaborative path planning method based on geometric graph neural network (GeoGNN). GeoGNN introduces the relative position information of neighboring robots into each interaction layer of the graph neural network to better integrate neighbor sensing information. An expert data generation method is designed for the robot to advance in a single step, by which expert data are generated in ROS to train the network. Experimental results show that the accuracy of the proposed method is improved by about 5% compared to the model based only on CNN on the expert data set. In ROS simulation environment path planning test, the success rate is improved by about 4% compared to CNN and flowtime increase is reduced about 8%, which outperforms other graph neural network models.
KTRL+F: Knowledge-Augmented In-Document Search
Nov 16, 2023We introduce a new problem KTRL+F, a knowledge-augmented in-document search task that necessitates real-time identification of all semantic targets within a document with the awareness of external sources through a single natural query. This task addresses following unique challenges for in-document search: 1) utilizing knowledge outside the document for extended use of additional information about targets to bridge the semantic gap between the query and the targets, and 2) balancing between real-time applicability with the performance. We analyze various baselines in KTRL+F and find there are limitations of existing models, such as hallucinations, low latency, or difficulties in leveraging external knowledge. Therefore we propose a Knowledge-Augmented Phrase Retrieval model that shows a promising balance between speed and performance by simply augmenting external knowledge embedding in phrase embedding. Additionally, we conduct a user study to verify whether solving KTRL+F can enhance search experience of users. It demonstrates that even with our simple model users can reduce the time for searching with less queries and reduced extra visits to other sources for collecting evidence. We encourage the research community to work on KTRL+F to enhance more efficient in-document information access.
Deep-learning-based acceleration of MRI for radiotherapy planning of pediatric patients with brain tumors
Nov 22, 2023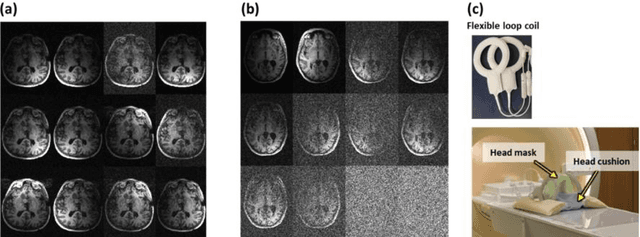

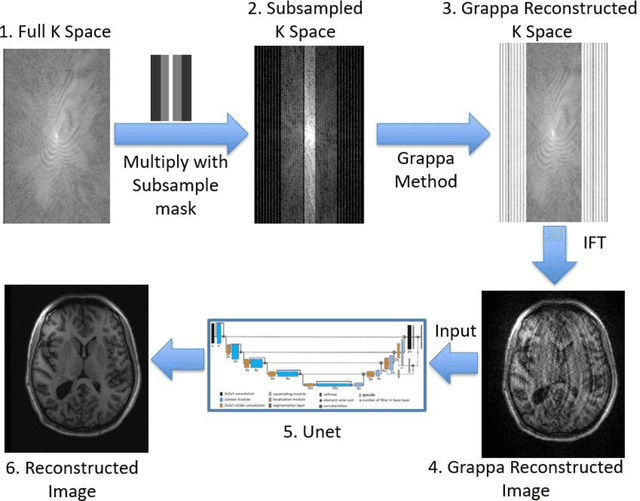
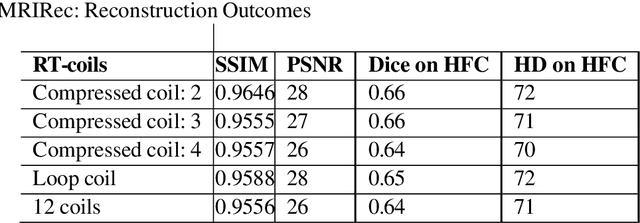
Magnetic Resonance Imaging (MRI) is a non-invasive diagnostic and radiotherapy (RT) planning tool, offering detailed insights into the anatomy of the human body. The extensive scan time is stressful for patients, who must remain motionless in a prolonged imaging procedure that prioritizes reduction of imaging artifacts. This is challenging for pediatric patients who may require measures for managing voluntary motions such as anesthesia. Several computational approaches reduce scan time (fast MRI), by recording fewer measurements and digitally recovering full information via post-acquisition reconstruction. However, most fast MRI approaches were developed for diagnostic imaging, without addressing reconstruction challenges specific to RT planning. In this work, we developed a deep learning-based method (DeepMRIRec) for MRI reconstruction from undersampled data acquired with RT-specific receiver coil arrangements. We evaluated our method against fully sampled data of T1-weighted MR images acquired from 73 children with brain tumors/surgical beds using loop and posterior coils (12 channels), with and without applying virtual compression of coil elements. DeepMRIRec reduced scanning time by a factor of four producing a structural similarity score surpassing the evaluated state-of-the-art method (0.960 vs 0.896), thereby demonstrating its potential for accelerating MRI scanning for RT planning.
SkeletonGait: Gait Recognition Using Skeleton Maps
Nov 22, 2023The choice of the representations is essential for deep gait recognition methods. The binary silhouettes and skeletal coordinates are two dominant representations in recent literature, achieving remarkable advances in many scenarios. However, inherent challenges remain, in which silhouettes are not always guaranteed in unconstrained scenes, and structural cues have not been fully utilized from skeletons. In this paper, we introduce a novel skeletal gait representation named Skeleton Map, together with SkeletonGait, a skeleton-based method to exploit structural information from human skeleton maps. Specifically, the skeleton map represents the coordinates of human joints as a heatmap with Gaussian approximation, exhibiting a silhouette-like image devoid of exact body structure. Beyond achieving state-of-the-art performances over five popular gait datasets, more importantly, SkeletonGait uncovers novel insights about how important structural features are in describing gait and when do they play a role. Furthermore, we propose a multi-branch architecture, named SkeletonGait++, to make use of complementary features from both skeletons and silhouettes. Experiments indicate that SkeletonGait++ outperforms existing state-of-the-art methods by a significant margin in various scenarios. For instance, it achieves an impressive rank-1 accuracy of over $85\%$ on the challenging GREW dataset. All the source code will be available at https://github.com/ShiqiYu/OpenGait.
Unveiling Public Perceptions: Machine Learning-Based Sentiment Analysis of COVID-19 Vaccines in India
Nov 19, 2023In March 2020, the World Health Organisation declared COVID-19 a global pandemic as it spread to nearly every country. By mid-2021, India had introduced three vaccines: Covishield, Covaxin, and Sputnik. To ensure successful vaccination in a densely populated country like India, understanding public sentiment was crucial. Social media, particularly Reddit with over 430 million users, played a vital role in disseminating information. This study employs data mining techniques to analyze Reddit data and gauge Indian sentiments towards COVID-19 vaccines. Using Python's Text Blob library, comments are annotated to assess general sentiments. Results show that most Reddit users in India expressed neutrality about vaccination, posing a challenge for the Indian government's efforts to vaccinate a significant portion of the population.
Implementation of AI Deep Learning Algorithm For Multi-Modal Sentiment Analysis
Nov 19, 2023A multi-modal emotion recognition method was established by combining two-channel convolutional neural network with ring network. This method can extract emotional information effectively and improve learning efficiency. The words were vectorized with GloVe, and the word vector was input into the convolutional neural network. Combining attention mechanism and maximum pool converter BiSRU channel, the local deep emotion and pre-post sequential emotion semantics are obtained. Finally, multiple features are fused and input as the polarity of emotion, so as to achieve the emotion analysis of the target. Experiments show that the emotion analysis method based on feature fusion can effectively improve the recognition accuracy of emotion data set and reduce the learning time. The model has a certain generalization.
3D Guidewire Shape Reconstruction from Monoplane Fluoroscopic Images
Nov 19, 2023Endovascular navigation, essential for diagnosing and treating endovascular diseases, predominantly hinges on fluoroscopic images due to the constraints in sensory feedback. Current shape reconstruction techniques for endovascular intervention often rely on either a priori information or specialized equipment, potentially subjecting patients to heightened radiation exposure. While deep learning holds potential, it typically demands extensive data. In this paper, we propose a new method to reconstruct the 3D guidewire by utilizing CathSim, a state-of-the-art endovascular simulator, and a 3D Fluoroscopy Guidewire Reconstruction Network (3D-FGRN). Our 3D-FGRN delivers results on par with conventional triangulation from simulated monoplane fluoroscopic images. Our experiments accentuate the efficiency of the proposed network, demonstrating it as a promising alternative to traditional methods.
Deep Group Interest Modeling of Full Lifelong User Behaviors for CTR Prediction
Nov 15, 2023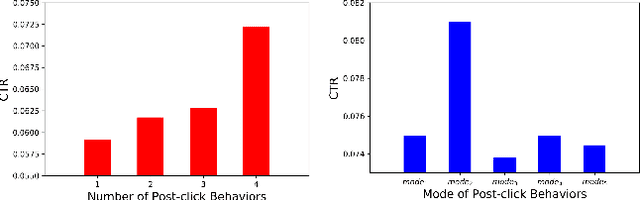

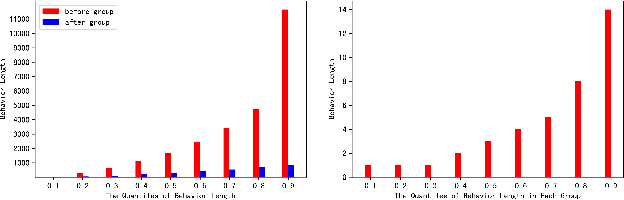
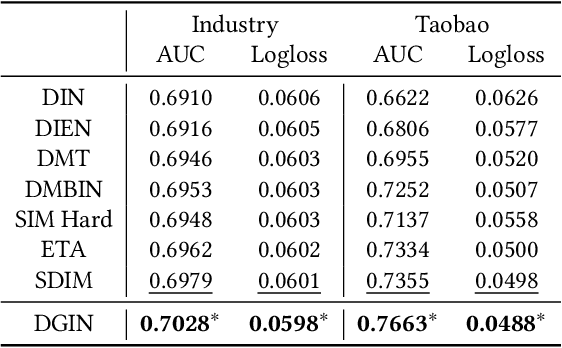
Extracting users' interests from their lifelong behavior sequence is crucial for predicting Click-Through Rate (CTR). Most current methods employ a two-stage process for efficiency: they first select historical behaviors related to the candidate item and then deduce the user's interest from this narrowed-down behavior sub-sequence. This two-stage paradigm, though effective, leads to information loss. Solely using users' lifelong click behaviors doesn't provide a complete picture of their interests, leading to suboptimal performance. In our research, we introduce the Deep Group Interest Network (DGIN), an end-to-end method to model the user's entire behavior history. This includes all post-registration actions, such as clicks, cart additions, purchases, and more, providing a nuanced user understanding. We start by grouping the full range of behaviors using a relevant key (like item_id) to enhance efficiency. This process reduces the behavior length significantly, from O(10^4) to O(10^2). To mitigate the potential loss of information due to grouping, we incorporate two categories of group attributes. Within each group, we calculate statistical information on various heterogeneous behaviors (like behavior counts) and employ self-attention mechanisms to highlight unique behavior characteristics (like behavior type). Based on this reorganized behavior data, the user's interests are derived using the Transformer technique. Additionally, we identify a subset of behaviors that share the same item_id with the candidate item from the lifelong behavior sequence. The insights from this subset reveal the user's decision-making process related to the candidate item, improving prediction accuracy. Our comprehensive evaluation, both on industrial and public datasets, validates DGIN's efficacy and efficiency.
I2SRM: Intra- and Inter-Sample Relationship Modeling for Multimodal Information Extraction
Oct 10, 2023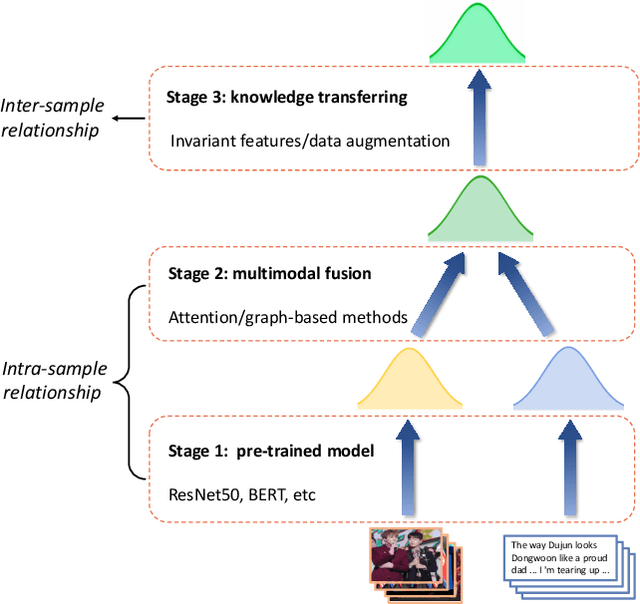
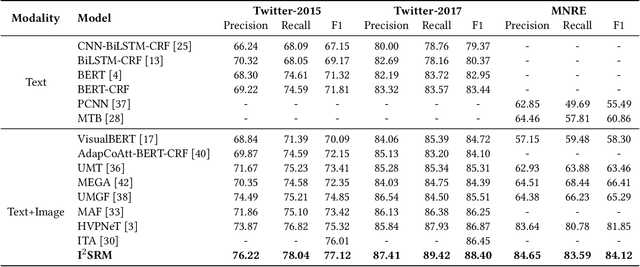
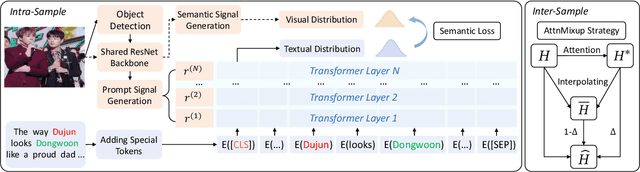
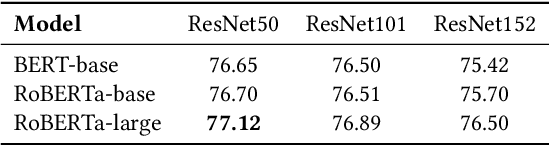
Multimodal information extraction is attracting research attention nowadays, which requires aggregating representations from different modalities. In this paper, we present the Intra- and Inter-Sample Relationship Modeling (I2SRM) method for this task, which contains two modules. Firstly, the intra-sample relationship modeling module operates on a single sample and aims to learn effective representations. Embeddings from textual and visual modalities are shifted to bridge the modality gap caused by distinct pre-trained language and image models. Secondly, the inter-sample relationship modeling module considers relationships among multiple samples and focuses on capturing the interactions. An AttnMixup strategy is proposed, which not only enables collaboration among samples but also augments data to improve generalization. We conduct extensive experiments on the multimodal named entity recognition datasets Twitter-2015 and Twitter-2017, and the multimodal relation extraction dataset MNRE. Our proposed method I2SRM achieves competitive results, 77.12% F1-score on Twitter-2015, 88.40% F1-score on Twitter-2017, and 84.12% F1-score on MNRE.