 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Research on Joint Representation Learning Methods for Entity Neighborhood Information and Description Information
Sep 15, 2023
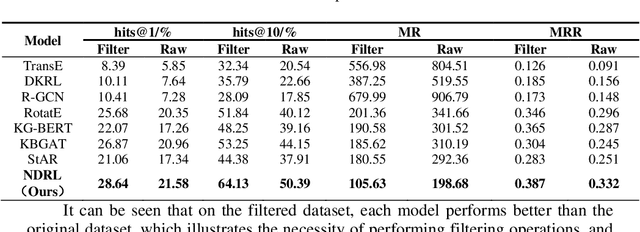
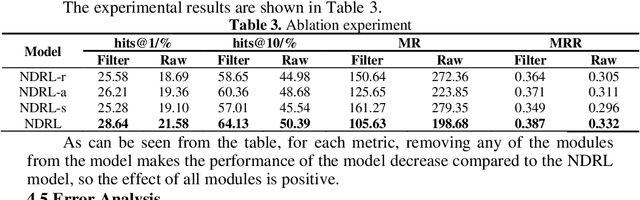
To address the issue of poor embedding performance in the knowledge graph of a programming design course, a joint represen-tation learning model that combines entity neighborhood infor-mation and description information is proposed. Firstly, a graph at-tention network is employed to obtain the features of entity neigh-boring nodes, incorporating relationship features to enrich the structural information. Next, the BERT-WWM model is utilized in conjunction with attention mechanisms to obtain the representation of entity description information. Finally, the final entity vector representation is obtained by combining the vector representations of entity neighborhood information and description information. Experimental results demonstrate that the proposed model achieves favorable performance on the knowledge graph dataset of the pro-gramming design course, outperforming other baseline models.
Benchmarking Large Language Model Volatility
Nov 26, 2023The impact of non-deterministic outputs from Large Language Models (LLMs) is not well examined for financial text understanding tasks. Through a compelling case study on investing in the US equity market via news sentiment analysis, we uncover substantial variability in sentence-level sentiment classification results, underscoring the innate volatility of LLM outputs. These uncertainties cascade downstream, leading to more significant variations in portfolio construction and return. While tweaking the temperature parameter in the language model decoder presents a potential remedy, it comes at the expense of stifled creativity. Similarly, while ensembling multiple outputs mitigates the effect of volatile outputs, it demands a notable computational investment. This work furnishes practitioners with invaluable insights for adeptly navigating uncertainty in the integration of LLMs into financial decision-making, particularly in scenarios dictated by non-deterministic information.
GCPV: Guided Concept Projection Vectors for the Explainable Inspection of CNN Feature Spaces
Nov 24, 2023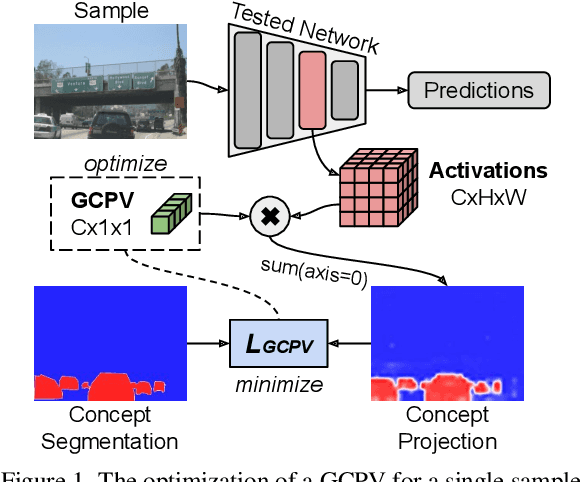

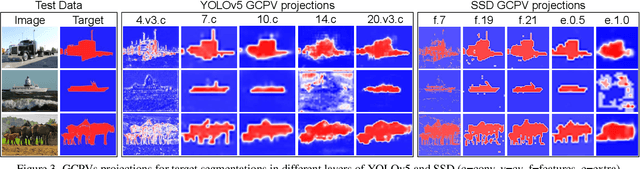

For debugging and verification of computer vision convolutional deep neural networks (CNNs) human inspection of the learned latent representations is imperative. Therefore, state-of-the-art eXplainable Artificial Intelligence (XAI) methods globally associate given natural language semantic concepts with representing vectors or regions in the CNN latent space supporting manual inspection. Yet, this approach comes with two major disadvantages: They are locally inaccurate when reconstructing a concept label and discard information about the distribution of concept instance representations. The latter, though, is of particular interest for debugging, like finding and understanding outliers, learned notions of sub-concepts, and concept confusion. Furthermore, current single-layer approaches neglect that information about a concept may be spread over the CNN depth. To overcome these shortcomings, we introduce the local-to-global Guided Concept Projection Vectors (GCPV) approach: It (1) generates local concept vectors that each precisely reconstruct a concept segmentation label, and then (2) generalizes these to global concept and even sub-concept vectors by means of hiearchical clustering. Our experiments on object detectors demonstrate improved performance compared to the state-of-the-art, the benefit of multi-layer concept vectors, and robustness against low-quality concept segmentation labels. Finally, we demonstrate that GCPVs can be applied to find root causes for confusion of concepts like bus and truck, and reveal interesting concept-level outliers. Thus, GCPVs pose a promising step towards interpretable model debugging and informed data improvement.
Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation
Nov 29, 2023Traditional 2D pose estimation models are limited by their category-specific design, making them suitable only for predefined object categories. This restriction becomes particularly challenging when dealing with novel objects due to the lack of relevant training data. To address this limitation, category-agnostic pose estimation (CAPE) was introduced. CAPE aims to enable keypoint localization for arbitrary object categories using a single model, requiring minimal support images with annotated keypoints. This approach not only enables object pose generation based on arbitrary keypoint definitions but also significantly reduces the associated costs, paving the way for versatile and adaptable pose estimation applications. We present a novel approach to CAPE that leverages the inherent geometrical relations between keypoints through a newly designed Graph Transformer Decoder. By capturing and incorporating this crucial structural information, our method enhances the accuracy of keypoint localization, marking a significant departure from conventional CAPE techniques that treat keypoints as isolated entities. We validate our approach on the MP-100 benchmark, a comprehensive dataset comprising over 20,000 images spanning more than 100 categories. Our method outperforms the prior state-of-the-art by substantial margins, achieving remarkable improvements of 2.16% and 1.82% under 1-shot and 5-shot settings, respectively. Furthermore, our method's end-to-end training demonstrates both scalability and efficiency compared to previous CAPE approaches.
Federated Online and Bandit Convex Optimization
Nov 29, 2023We study the problems of distributed online and bandit convex optimization against an adaptive adversary. We aim to minimize the average regret on $M$ machines working in parallel over $T$ rounds with $R$ intermittent communications. Assuming the underlying cost functions are convex and can be generated adaptively, our results show that collaboration is not beneficial when the machines have access to the first-order gradient information at the queried points. This is in contrast to the case for stochastic functions, where each machine samples the cost functions from a fixed distribution. Furthermore, we delve into the more challenging setting of federated online optimization with bandit (zeroth-order) feedback, where the machines can only access values of the cost functions at the queried points. The key finding here is identifying the high-dimensional regime where collaboration is beneficial and may even lead to a linear speedup in the number of machines. We further illustrate our findings through federated adversarial linear bandits by developing novel distributed single and two-point feedback algorithms. Our work is the first attempt towards a systematic understanding of federated online optimization with limited feedback, and it attains tight regret bounds in the intermittent communication setting for both first and zeroth-order feedback. Our results thus bridge the gap between stochastic and adaptive settings in federated online optimization.
Improving Stability during Upsampling -- on the Importance of Spatial Context
Nov 29, 2023State-of-the-art models for pixel-wise prediction tasks such as image restoration, image segmentation, or disparity estimation, involve several stages of data resampling, in which the resolution of feature maps is first reduced to aggregate information and then sequentially increased to generate a high-resolution output. Several previous works have investigated the effect of artifacts that are invoked during downsampling and diverse cures have been proposed that facilitate to improve prediction stability and even robustness for image classification. However, equally relevant, artifacts that arise during upsampling have been less discussed. This is significantly relevant as upsampling and downsampling approaches face fundamentally different challenges. While during downsampling, aliases and artifacts can be reduced by blurring feature maps, the emergence of fine details is crucial during upsampling. Blurring is therefore not an option and dedicated operations need to be considered. In this work, we are the first to explore the relevance of context during upsampling by employing convolutional upsampling operations with increasing kernel size while keeping the encoder unchanged. We find that increased kernel sizes can in general improve the prediction stability in tasks such as image restoration or image segmentation, while a block that allows for a combination of small-size kernels for fine details and large-size kernels for artifact removal and increased context yields the best results.
AnonPSI: An Anonymity Assessment Framework for PSI
Nov 29, 2023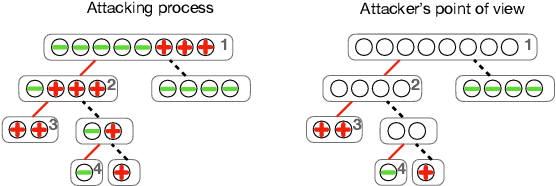
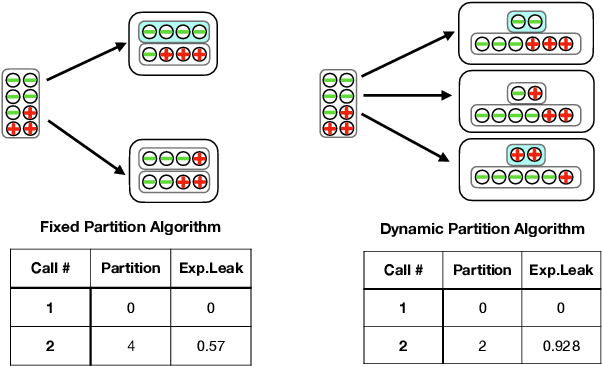
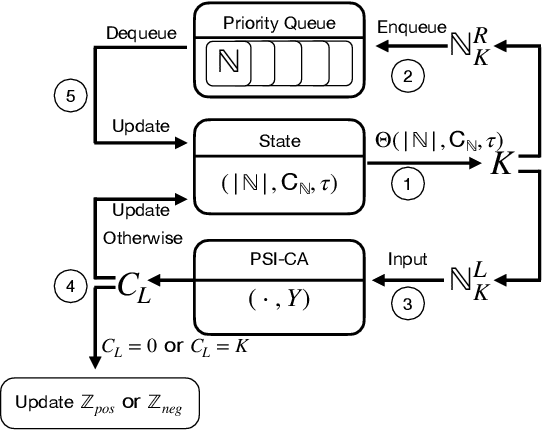
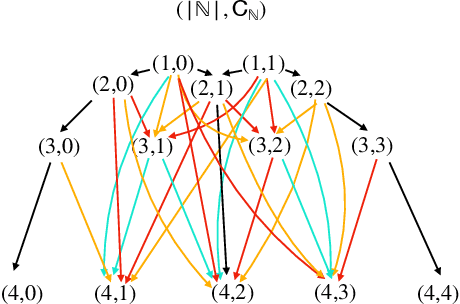
Private Set Intersection (PSI) is a widely used protocol that enables two parties to securely compute a function over the intersected part of their shared datasets and has been a significant research focus over the years. However, recent studies have highlighted its vulnerability to Set Membership Inference Attacks (SMIA), where an adversary might deduce an individual's membership by invoking multiple PSI protocols. This presents a considerable risk, even in the most stringent versions of PSI, which only return the cardinality of the intersection. This paper explores the evaluation of anonymity within the PSI context. Initially, we highlight the reasons why existing works fall short in measuring privacy leakage, and subsequently propose two attack strategies that address these deficiencies. Furthermore, we provide theoretical guarantees on the performance of our proposed methods. In addition to these, we illustrate how the integration of auxiliary information, such as the sum of payloads associated with members of the intersection (PSI-SUM), can enhance attack efficiency. We conducted a comprehensive performance evaluation of various attack strategies proposed utilizing two real datasets. Our findings indicate that the methods we propose markedly enhance attack efficiency when contrasted with previous research endeavors. {The effective attacking implies that depending solely on existing PSI protocols may not provide an adequate level of privacy assurance. It is recommended to combine privacy-enhancing technologies synergistically to enhance privacy protection even further.
Gene-MOE: A Sparsely-gated Framework for Pan-Cancer Genomic Analysis
Nov 29, 2023Analyzing the genomic information from the Pan-Cancer database can help us understand cancer-related factors and contribute to the cancer diagnosis and prognosis. However, existing computational methods and deep learning methods can not effectively find the deep correlations between tens of thousands of genes, which leads to precision loss. In this paper, we proposed a novel pretrained model called Gene-MOE to learn the general feature representations of the Pan-Cancer dataset and transfer the pretrained weights to the downstream tasks. The Gene-MOE fully exploits the mixture of expert (MOE) layers to learn rich feature representations of high-dimensional genes. At the same time, we build a mixture of attention expert (MOAE) model to learn the deep semantic relationships within genetic features. Finally, we proposed a new self-supervised pretraining strategy including loss function design, data enhancement, and optimization strategy to train the Gene-MOE and further improve the performance for the downstream analysis. We carried out cancer classification and survival analysis experiments based on the Gene-MOE. According to the survival analysis results on 14 cancer types, using Gene-MOE outperformed state-of-the-art models on 12 cancer types. According to the classification results, the total accuracy of the classification model for 33 cancer classifications reached 95.2\%. Through detailed feature analysis, we found the Gene-MOE model can learn rich feature representations of high-dimensional genes.
Understanding Self-Supervised Features for Learning Unsupervised Instance Segmentation
Nov 24, 2023Self-supervised learning (SSL) can be used to solve complex visual tasks without human labels. Self-supervised representations encode useful semantic information about images, and as a result, they have already been used for tasks such as unsupervised semantic segmentation. In this paper, we investigate self-supervised representations for instance segmentation without any manual annotations. We find that the features of different SSL methods vary in their level of instance-awareness. In particular, DINO features, which are known to be excellent semantic descriptors, lack behind MAE features in their sensitivity for separating instances.
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
Nov 28, 2023Lifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is https://lingtengqiu.github.io/RichDreamer/.