 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DOCMASTER: A Unified Platform for Annotation, Training, & Inference in Document Question-Answering
Mar 30, 2024
The application of natural language processing models to PDF documents is pivotal for various business applications yet the challenge of training models for this purpose persists in businesses due to specific hurdles. These include the complexity of working with PDF formats that necessitate parsing text and layout information for curating training data and the lack of privacy-preserving annotation tools. This paper introduces DOCMASTER, a unified platform designed for annotating PDF documents, model training, and inference, tailored to document question-answering. The annotation interface enables users to input questions and highlight text spans within the PDF file as answers, saving layout information and text spans accordingly. Furthermore, DOCMASTER supports both state-of-the-art layout-aware and text models for comprehensive training purposes. Importantly, as annotations, training, and inference occur on-device, it also safeguards privacy. The platform has been instrumental in driving several research prototypes concerning document analysis such as the AI assistant utilized by University of California San Diego's (UCSD) International Services and Engagement Office (ISEO) for processing a substantial volume of PDF documents.
Cooperative Communication Based Gradient Coding for Wireless Federated Learning
Mar 31, 2024We investigate wireless federated learning (FL) in the presence of stragglers, where the power-constrained wireless devices collaboratively train a global model on their local datasets %within a time constraint and transmit local model updates through fading channels. To tackle stragglers resulting from link disruptions without requiring accurate prior information on connectivity or dataset sharing, we propose a gradient coding (GC) scheme based on cooperative communication. Subsequently, we conduct an outage analysis of the proposed scheme, based on which we conduct the convergence analysis. The simulation results reveal the superiority of the proposed strategy in the presence of stragglers, especially in low signal-to-noise ratio (SNR) scenarios.
LexAbSumm: Aspect-based Summarization of Legal Decisions
Mar 31, 2024Legal professionals frequently encounter long legal judgments that hold critical insights for their work. While recent advances have led to automated summarization solutions for legal documents, they typically provide generic summaries, which may not meet the diverse information needs of users. To address this gap, we introduce LexAbSumm, a novel dataset designed for aspect-based summarization of legal case decisions, sourced from the European Court of Human Rights jurisdiction. We evaluate several abstractive summarization models tailored for longer documents on LexAbSumm, revealing a challenge in conditioning these models to produce aspect-specific summaries. We release LexAbSum to facilitate research in aspect-based summarization for legal domain.
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
Mar 15, 2024
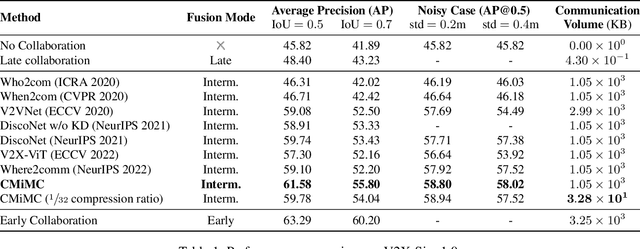
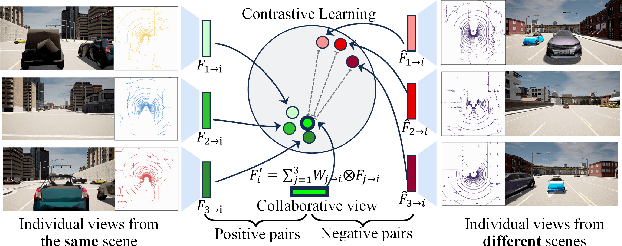
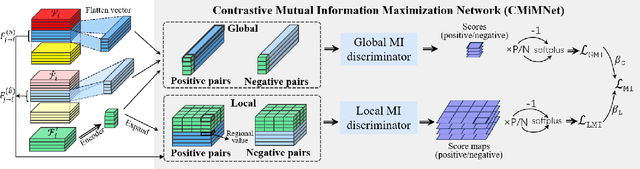
Multi-agent perception (MAP) allows autonomous systems to understand complex environments by interpreting data from multiple sources. This paper investigates intermediate collaboration for MAP with a specific focus on exploring "good" properties of collaborative view (i.e., post-collaboration feature) and its underlying relationship to individual views (i.e., pre-collaboration features), which were treated as an opaque procedure by most existing works. We propose a novel framework named CMiMC (Contrastive Mutual Information Maximization for Collaborative Perception) for intermediate collaboration. The core philosophy of CMiMC is to preserve discriminative information of individual views in the collaborative view by maximizing mutual information between pre- and post-collaboration features while enhancing the efficacy of collaborative views by minimizing the loss function of downstream tasks. In particular, we define multi-view mutual information (MVMI) for intermediate collaboration that evaluates correlations between collaborative views and individual views on both global and local scales. We establish CMiMNet based on multi-view contrastive learning to realize estimation and maximization of MVMI, which assists the training of a collaboration encoder for voxel-level feature fusion. We evaluate CMiMC on V2X-Sim 1.0, and it improves the SOTA average precision by 3.08% and 4.44% at 0.5 and 0.7 IoU (Intersection-over-Union) thresholds, respectively. In addition, CMiMC can reduce communication volume to 1/32 while achieving performance comparable to SOTA. Code and Appendix are released at https://github.com/77SWF/CMiMC.
Asymptotics of Language Model Alignment
Apr 02, 2024Let $p$ denote a generative language model. Let $r$ denote a reward model that returns a scalar that captures the degree at which a draw from $p$ is preferred. The goal of language model alignment is to alter $p$ to a new distribution $\phi$ that results in a higher expected reward while keeping $\phi$ close to $p.$ A popular alignment method is the KL-constrained reinforcement learning (RL), which chooses a distribution $\phi_\Delta$ that maximizes $E_{\phi_{\Delta}} r(y)$ subject to a relative entropy constraint $KL(\phi_\Delta || p) \leq \Delta.$ Another simple alignment method is best-of-$N$, where $N$ samples are drawn from $p$ and one with highest reward is selected. In this paper, we offer a closed-form characterization of the optimal KL-constrained RL solution. We demonstrate that any alignment method that achieves a comparable trade-off between KL divergence and reward must approximate the optimal KL-constrained RL solution in terms of relative entropy. To further analyze the properties of alignment methods, we introduce two simplifying assumptions: we let the language model be memoryless, and the reward model be linear. Although these assumptions may not reflect complex real-world scenarios, they enable a precise characterization of the asymptotic behavior of both the best-of-$N$ alignment, and the KL-constrained RL method, in terms of information-theoretic quantities. We prove that the reward of the optimal KL-constrained RL solution satisfies a large deviation principle, and we fully characterize its rate function. We also show that the rate of growth of the scaled cumulants of the reward is characterized by a proper Renyi cross entropy. Finally, we show that best-of-$N$ is asymptotically equivalent to KL-constrained RL solution by proving that their expected rewards are asymptotically equal, and concluding that the two distributions must be close in KL divergence.
Plaintext-Free Deep Learning for Privacy-Preserving Medical Image Analysis via Frequency Information Embedding
Mar 25, 2024In the fast-evolving field of medical image analysis, Deep Learning (DL)-based methods have achieved tremendous success. However, these methods require plaintext data for training and inference stages, raising privacy concerns, especially in the sensitive area of medical data. To tackle these concerns, this paper proposes a novel framework that uses surrogate images for analysis, eliminating the need for plaintext images. This approach is called Frequency-domain Exchange Style Fusion (FESF). The framework includes two main components: Image Hidden Module (IHM) and Image Quality Enhancement Module~(IQEM). The~IHM performs in the frequency domain, blending the features of plaintext medical images into host medical images, and then combines this with IQEM to improve and create surrogate images effectively. During the diagnostic model training process, only surrogate images are used, enabling anonymous analysis without any plaintext data during both training and inference stages. Extensive evaluations demonstrate that our framework effectively preserves the privacy of medical images and maintains diagnostic accuracy of DL models at a relatively high level, proving its effectiveness across various datasets and DL-based models.
Logical Discrete Graphical Models Must Supplement Large Language Models for Information Synthesis
Mar 14, 2024Given the emergent reasoning abilities of large language models, information retrieval is becoming more complex. Rather than just retrieve a document, modern information retrieval systems advertise that they can synthesize an answer based on potentially many different documents, conflicting data sources, and using reasoning. We review recent literature and argue that the large language model has crucial flaws that prevent it from on its own ever constituting general intelligence, or answering general information synthesis requests. This review shows that the following are problems for large language models: hallucinations, complex reasoning, planning under uncertainty, and complex calculations. We outline how logical discrete graphical models can solve all of these problems, and outline a method of training a logical discrete model from unlabeled text.
Generate then Retrieve: Conversational Response Retrieval Using LLMs as Answer and Query Generators
Mar 28, 2024CIS is a prominent area in IR that focuses on developing interactive knowledge assistants. These systems must adeptly comprehend the user's information requirements within the conversational context and retrieve the relevant information. To this aim, the existing approaches model the user's information needs with one query called rewritten query and use this query for passage retrieval. In this paper, we propose three different methods for generating multiple queries to enhance the retrieval. In these methods, we leverage the capabilities of large language models (LLMs) in understanding the user's information need and generating an appropriate response, to generate multiple queries. We implement and evaluate the proposed models utilizing various LLMs including GPT-4 and Llama-2 chat in zero-shot and few-shot settings. In addition, we propose a new benchmark for TREC iKAT based on gpt 3.5 judgments. Our experiments reveal the effectiveness of our proposed models on the TREC iKAT dataset.
CuSINeS: Curriculum-driven Structure Induced Negative Sampling for Statutory Article Retrieval
Mar 31, 2024In this paper, we introduce CuSINeS, a negative sampling approach to enhance the performance of Statutory Article Retrieval (SAR). CuSINeS offers three key contributions. Firstly, it employs a curriculum-based negative sampling strategy guiding the model to focus on easier negatives initially and progressively tackle more difficult ones. Secondly, it leverages the hierarchical and sequential information derived from the structural organization of statutes to evaluate the difficulty of samples. Lastly, it introduces a dynamic semantic difficulty assessment using the being-trained model itself, surpassing conventional static methods like BM25, adapting the negatives to the model's evolving competence. Experimental results on a real-world expert-annotated SAR dataset validate the effectiveness of CuSINeS across four different baselines, demonstrating its versatility.
Explainable AI Integrated Feature Engineering for Wildfire Prediction
Apr 01, 2024Wildfires present intricate challenges for prediction, necessitating the use of sophisticated machine learning techniques for effective modeling\cite{jain2020review}. In our research, we conducted a thorough assessment of various machine learning algorithms for both classification and regression tasks relevant to predicting wildfires. We found that for classifying different types or stages of wildfires, the XGBoost model outperformed others in terms of accuracy and robustness. Meanwhile, the Random Forest regression model showed superior results in predicting the extent of wildfire-affected areas, excelling in both prediction error and explained variance. Additionally, we developed a hybrid neural network model that integrates numerical data and image information for simultaneous classification and regression. To gain deeper insights into the decision-making processes of these models and identify key contributing features, we utilized eXplainable Artificial Intelligence (XAI) techniques, including TreeSHAP, LIME, Partial Dependence Plots (PDP), and Gradient-weighted Class Activation Mapping (Grad-CAM). These interpretability tools shed light on the significance and interplay of various features, highlighting the complex factors influencing wildfire predictions. Our study not only demonstrates the effectiveness of specific machine learning models in wildfire-related tasks but also underscores the critical role of model transparency and interpretability in environmental science applications.