 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Harnessing the Power of Prompt-based Techniques for Generating School-Level Questions using Large Language Models
Dec 02, 2023
Designing high-quality educational questions is a challenging and time-consuming task. In this work, we propose a novel approach that utilizes prompt-based techniques to generate descriptive and reasoning-based questions. However, current question-answering (QA) datasets are inadequate for conducting our experiments on prompt-based question generation (QG) in an educational setting. Therefore, we curate a new QG dataset called EduProbe for school-level subjects, by leveraging the rich content of NCERT textbooks. We carefully annotate this dataset as quadruples of 1) Context: a segment upon which the question is formed; 2) Long Prompt: a long textual cue for the question (i.e., a longer sequence of words or phrases, covering the main theme of the context); 3) Short Prompt: a short textual cue for the question (i.e., a condensed representation of the key information or focus of the context); 4) Question: a deep question that aligns with the context and is coherent with the prompts. We investigate several prompt-based QG methods by fine-tuning pre-trained transformer-based large language models (LLMs), namely PEGASUS, T5, MBART, and BART. Moreover, we explore the performance of two general-purpose pre-trained LLMs such as Text-Davinci-003 and GPT-3.5-Turbo without any further training. By performing automatic evaluation, we show that T5 (with long prompt) outperforms all other models, but still falls short of the human baseline. Under human evaluation criteria, TextDavinci-003 usually shows better results than other models under various prompt settings. Even in the case of human evaluation criteria, QG models mostly fall short of the human baseline. Our code and dataset are available at: https://github.com/my625/PromptQG
Telling Left from Right: Identifying Geometry-Aware Semantic Correspondence
Nov 28, 2023While pre-trained large-scale vision models have shown significant promise for semantic correspondence, their features often struggle to grasp the geometry and orientation of instances. This paper identifies the importance of being geometry-aware for semantic correspondence and reveals a limitation of the features of current foundation models under simple post-processing. We show that incorporating this information can markedly enhance semantic correspondence performance with simple but effective solutions in both zero-shot and supervised settings. We also construct a new challenging benchmark for semantic correspondence built from an existing animal pose estimation dataset, for both pre-training validating models. Our method achieves a PCK@0.10 score of 64.2 (zero-shot) and 85.6 (supervised) on the challenging SPair-71k dataset, outperforming the state-of-the-art by 4.3p and 11.0p absolute gains, respectively. Our code and datasets will be publicly available.
Creating Temporally Correlated High-Resolution Power Injection Profiles Using Physics-Aware GAN
Nov 22, 2023Traditional smart meter measurements lack the granularity needed for real-time decision-making. To address this practical problem, we create a generative adversarial networks (GAN) model that enforces temporal consistency on its high-resolution outputs via hard inequality constraints using a convex optimization layer. A unique feature of our GAN model is that it is trained solely on slow timescale aggregated power information obtained from historical smart meter data. The results demonstrate that the model can successfully create minutely interval temporally-correlated instantaneous power injection profiles from 15-minute average power consumption information. This innovative approach, emphasizing inter-neuron constraints, offers a promising avenue for improved high-speed state estimation in distribution systems and enhances the applicability of data-driven solutions for monitoring such systems.
Generative AI for Software Metadata: Overview of the Information Retrieval in Software Engineering Track at FIRE 2023
Oct 27, 2023The Information Retrieval in Software Engineering (IRSE) track aims to develop solutions for automated evaluation of code comments in a machine learning framework based on human and large language model generated labels. In this track, there is a binary classification task to classify comments as useful and not useful. The dataset consists of 9048 code comments and surrounding code snippet pairs extracted from open source github C based projects and an additional dataset generated individually by teams using large language models. Overall 56 experiments have been submitted by 17 teams from various universities and software companies. The submissions have been evaluated quantitatively using the F1-Score and qualitatively based on the type of features developed, the supervised learning model used and their corresponding hyper-parameters. The labels generated from large language models increase the bias in the prediction model but lead to less over-fitted results.
InfoDiffusion: Information Entropy Aware Diffusion Process for Non-Autoregressive Text Generation
Oct 18, 2023Diffusion models have garnered considerable interest in the field of text generation. Several studies have explored text diffusion models with different structures and applied them to various tasks, including named entity recognition and summarization. However, there exists a notable disparity between the "easy-first" text generation process of current diffusion models and the "keyword-first" natural text generation process of humans, which has received limited attention. To bridge this gap, we propose InfoDiffusion, a non-autoregressive text diffusion model. Our approach introduces a "keyinfo-first" generation strategy and incorporates a noise schedule based on the amount of text information. In addition, InfoDiffusion combines self-conditioning with a newly proposed partially noising model structure. Experimental results show that InfoDiffusion outperforms the baseline model in terms of generation quality and diversity, as well as exhibiting higher sampling efficiency.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Dec 01, 2023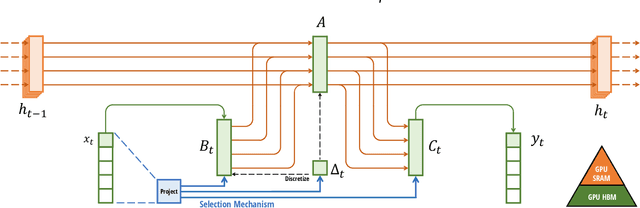
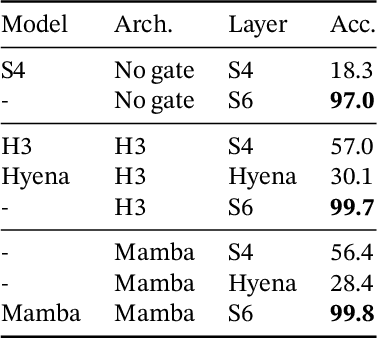
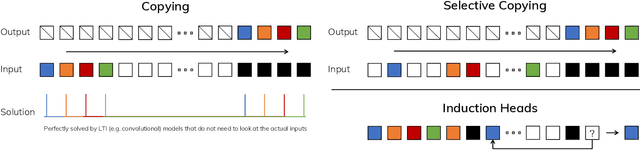
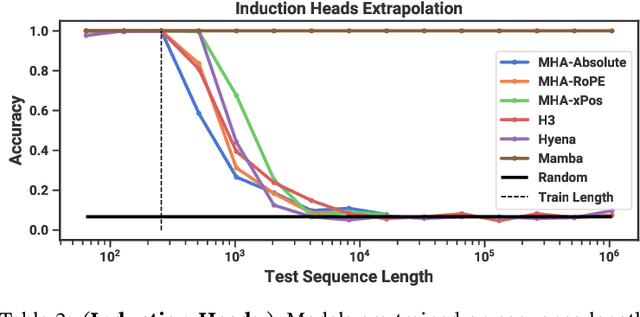
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$\times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Partition-based K-space Synthesis for Multi-contrast Parallel Imaging
Dec 01, 2023Multi-contrast magnetic resonance imaging is a significant and essential medical imaging technique.However, multi-contrast imaging has longer acquisition time and is easy to cause motion artifacts. In particular, the acquisition time for a T2-weighted image is prolonged due to its longer repetition time (TR). On the contrary, T1-weighted image has a shorter TR. Therefore,utilizing complementary information across T1 and T2-weighted image is a way to decrease the overall imaging time. Previous T1-assisted T2 reconstruction methods have mostly focused on image domain using whole-based image fusion approaches. The image domain reconstruction method has the defects of high computational complexity and limited flexibility. To address this issue, we propose a novel multi-contrast imaging method called partition-based k-space synthesis (PKS) which can achieve super reconstruction quality of T2-weighted image by feature fusion. Concretely, we first decompose fully-sampled T1 k-space data and under-sampled T2 k-space data into two sub-data, separately. Then two new objects are constructed by combining the two sub-T1/T2 data. After that, the two new objects as the whole data to realize the reconstruction of T2-weighted image. Finally, the objective T2 is synthesized by extracting the sub-T2 data of each part. Experimental results showed that our combined technique can achieve comparable or better results than using traditional k-space parallel imaging(SAKE) that processes each contrast independently.
UAV-Aided Lifelong Learning for AoI and Energy Optimization in Non-Stationary IoT Networks
Dec 01, 2023In this paper, a novel joint energy and age of information (AoI) optimization framework for IoT devices in a non-stationary environment is presented. In particular, IoT devices that are distributed in the real-world are required to efficiently utilize their computing resources so as to balance the freshness of their data and their energy consumption. To optimize the performance of IoT devices in such a dynamic setting, a novel lifelong reinforcement learning (RL) solution that enables IoT devices to continuously adapt their policies to each newly encountered environment is proposed. Given that IoT devices have limited energy and computing resources, an unmanned aerial vehicle (UAV) is leveraged to visit the IoT devices and update the policy of each device sequentially. As such, the UAV is exploited as a mobile learning agent that can learn a shared knowledge base with a feature base in its training phase, and feature sets of a zero-shot learning method in its testing phase, to generalize between the environments. To optimize the trajectory and flying velocity of the UAV, an actor-critic network is leveraged so as to minimize the UAV energy consumption. Simulation results show that the proposed lifelong RL solution can outperform the state-of-art benchmarks by enhancing the balanced cost of IoT devices by $8.3\%$ when incorporating warm-start policies for unseen environments. In addition, our solution achieves up to $49.38\%$ reduction in terms of energy consumption by the UAV in comparison to the random flying strategy.
Joint Antenna Selection and Power Allocation in Massive MIMO Systems with Cell Division Technique for MRT and ZF Precoding Schemes
Nov 26, 2023One of the most important challenges in the fifth generation (5G) of telecommunication systems is the efficiency of energy and spectrum. Massive multiple-input multiple-output (MIMO) systems have been proposed by researchers to resolve existing challenges. In the proposed system model of this paper, there is a base station (BS) around which several users and an eavesdropper (EVA) are evenly distributed. The information transmitted between BS and users is disrupted by an EVA, which highlights the importance of secure transfer. This paper analyzes secure energy efficiency (EE) of a massive MIMO system, and its purpose is to maximize the secure EE of the system. Several scenarios are considered to evaluate achieving the desired goal. To maximize the secure EE, selecting optimal number of antennas and cell division methods are employed. Each of these two methods is applied in a system with the maximum ratio transmission (MRT) and the zero forcing (ZF) precodings, and then the problem is solved. Maximum transmission power and minimum secure rate for users insert limitations to the optimization problem. Channel state information (CSI) is generally imperfect for users in any method, while CSI of the EVA is considered perfect as the worst case. Four iterative algorithms are designed to provide numerical assessments. The first algorithm calculates the optimal power of users without utilizing existing methods, the second one is related to the cell division method, the third one is based on the strategy of selecting optimal number of antennas, and forth one is based on a hybrid strategy.
Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning
Nov 29, 2023In this study, we are interested in imbuing robots with the capability of physically-grounded task planning. Recent advancements have shown that large language models (LLMs) possess extensive knowledge useful in robotic tasks, especially in reasoning and planning. However, LLMs are constrained by their lack of world grounding and dependence on external affordance models to perceive environmental information, which cannot jointly reason with LLMs. We argue that a task planner should be an inherently grounded, unified multimodal system. To this end, we introduce Robotic Vision-Language Planning (ViLa), a novel approach for long-horizon robotic planning that leverages vision-language models (VLMs) to generate a sequence of actionable steps. ViLa directly integrates perceptual data into its reasoning and planning process, enabling a profound understanding of commonsense knowledge in the visual world, including spatial layouts and object attributes. It also supports flexible multimodal goal specification and naturally incorporates visual feedback. Our extensive evaluation, conducted in both real-robot and simulated environments, demonstrates ViLa's superiority over existing LLM-based planners, highlighting its effectiveness in a wide array of open-world manipulation tasks.