 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PIE-NeRF: Physics-based Interactive Elastodynamics with NeRF
Nov 22, 2023
We show that physics-based simulations can be seamlessly integrated with NeRF to generate high-quality elastodynamics of real-world objects. Unlike existing methods, we discretize nonlinear hyperelasticity in a meshless way, obviating the necessity for intermediate auxiliary shape proxies like a tetrahedral mesh or voxel grid. A quadratic generalized moving least square (Q-GMLS) is employed to capture nonlinear dynamics and large deformation on the implicit model. Such meshless integration enables versatile simulations of complex and codimensional shapes. We adaptively place the least-square kernels according to the NeRF density field to significantly reduce the complexity of the nonlinear simulation. As a result, physically realistic animations can be conveniently synthesized using our method for a wide range of hyperelastic materials at an interactive rate. For more information, please visit our project page at https://fytalon.github.io/pienerf/.
Teach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
Scattering Vision Transformer: Spectral Mixing Matters
Nov 20, 2023Vision transformers have gained significant attention and achieved state-of-the-art performance in various computer vision tasks, including image classification, instance segmentation, and object detection. However, challenges remain in addressing attention complexity and effectively capturing fine-grained information within images. Existing solutions often resort to down-sampling operations, such as pooling, to reduce computational cost. Unfortunately, such operations are non-invertible and can result in information loss. In this paper, we present a novel approach called Scattering Vision Transformer (SVT) to tackle these challenges. SVT incorporates a spectrally scattering network that enables the capture of intricate image details. SVT overcomes the invertibility issue associated with down-sampling operations by separating low-frequency and high-frequency components. Furthermore, SVT introduces a unique spectral gating network utilizing Einstein multiplication for token and channel mixing, effectively reducing complexity. We show that SVT achieves state-of-the-art performance on the ImageNet dataset with a significant reduction in a number of parameters and FLOPS. SVT shows 2\% improvement over LiTv2 and iFormer. SVT-H-S reaches 84.2\% top-1 accuracy, while SVT-H-B reaches 85.2\% (state-of-art for base versions) and SVT-H-L reaches 85.7\% (again state-of-art for large versions). SVT also shows comparable results in other vision tasks such as instance segmentation. SVT also outperforms other transformers in transfer learning on standard datasets such as CIFAR10, CIFAR100, Oxford Flower, and Stanford Car datasets. The project page is available on this webpage.\url{https://badripatro.github.io/svt/}.
RetroDiff: Retrosynthesis as Multi-stage Distribution Interpolation
Nov 23, 2023Retrosynthesis poses a fundamental challenge in biopharmaceuticals, aiming to aid chemists in finding appropriate reactant molecules and synthetic pathways given determined product molecules. With the reactant and product represented as 2D graphs, retrosynthesis constitutes a conditional graph-to-graph generative task. Inspired by the recent advancements in discrete diffusion models for graph generation, we introduce Retrosynthesis Diffusion (RetroDiff), a novel diffusion-based method designed to address this problem. However, integrating a diffusion-based graph-to-graph framework while retaining essential chemical reaction template information presents a notable challenge. Our key innovation is to develop a multi-stage diffusion process. In this method, we decompose the retrosynthesis procedure to first sample external groups from the dummy distribution given products and then generate the external bonds to connect the products and generated groups. Interestingly, such a generation process is exactly the reverse of the widely adapted semi-template retrosynthesis procedure, i.e. from reaction center identification to synthon completion, which significantly reduces the error accumulation. Experimental results on the benchmark have demonstrated the superiority of our method over all other semi-template methods.
Jam-ALT: A Formatting-Aware Lyrics Transcription Benchmark
Nov 23, 2023Current automatic lyrics transcription (ALT) benchmarks focus exclusively on word content and ignore the finer nuances of written lyrics including formatting and punctuation, which leads to a potential misalignment with the creative products of musicians and songwriters as well as listeners' experiences. For example, line breaks are important in conveying information about rhythm, emotional emphasis, rhyme, and high-level structure. To address this issue, we introduce Jam-ALT, a new lyrics transcription benchmark based on the JamendoLyrics dataset. Our contribution is twofold. Firstly, a complete revision of the transcripts, geared specifically towards ALT evaluation by following a newly created annotation guide that unifies the music industry's guidelines, covering aspects such as punctuation, line breaks, spelling, background vocals, and non-word sounds. Secondly, a suite of evaluation metrics designed, unlike the traditional word error rate, to capture such phenomena. We hope that the proposed benchmark contributes to the ALT task, enabling more precise and reliable assessments of transcription systems and enhancing the user experience in lyrics applications such as subtitle renderings for live captioning or karaoke.
Appearance-based gaze estimation enhanced with synthetic images using deep neural networks
Nov 23, 2023Human eye gaze estimation is an important cognitive ingredient for successful human-robot interaction, enabling the robot to read and predict human behavior. We approach this problem using artificial neural networks and build a modular system estimating gaze from separately cropped eyes, taking advantage of existing well-functioning components for face detection (RetinaFace) and head pose estimation (6DRepNet). Our proposed method does not require any special hardware or infrared filters but uses a standard notebook-builtin RGB camera, as often approached with appearance-based methods. Using the MetaHuman tool, we also generated a large synthetic dataset of more than 57,000 human faces and made it publicly available. The inclusion of this dataset (with eye gaze and head pose information) on top of the standard Columbia Gaze dataset into training the model led to better accuracy with a mean average error below two degrees in eye pitch and yaw directions, which compares favourably to related methods. We also verified the feasibility of our model by its preliminary testing in real-world setting using the builtin 4K camera in NICO semi-humanoid robot's eye.
HGCLIP: Exploring Vision-Language Models with Graph Representations for Hierarchical Understanding
Nov 23, 2023Object categories are typically organized into a multi-granularity taxonomic hierarchy. When classifying categories at different hierarchy levels, traditional uni-modal approaches focus primarily on image features, revealing limitations in complex scenarios. Recent studies integrating Vision-Language Models (VLMs) with class hierarchies have shown promise, yet they fall short of fully exploiting the hierarchical relationships. These efforts are constrained by their inability to perform effectively across varied granularity of categories. To tackle this issue, we propose a novel framework (HGCLIP) that effectively combines CLIP with a deeper exploitation of the Hierarchical class structure via Graph representation learning. We explore constructing the class hierarchy into a graph, with its nodes representing the textual or image features of each category. After passing through a graph encoder, the textual features incorporate hierarchical structure information, while the image features emphasize class-aware features derived from prototypes through the attention mechanism. Our approach demonstrates significant improvements on both generic and fine-grained visual recognition benchmarks. Our codes are fully available at https://github.com/richard-peng-xia/HGCLIP.
Evidential Active Recognition: Intelligent and Prudent Open-World Embodied Perception
Nov 23, 2023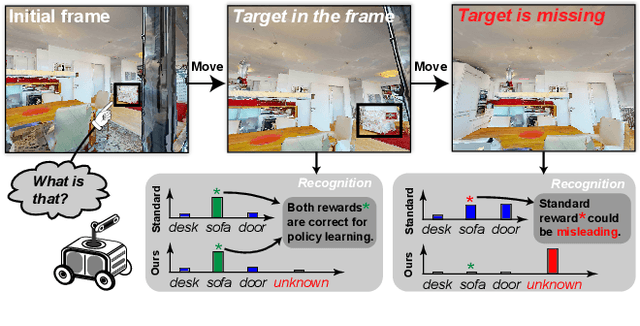
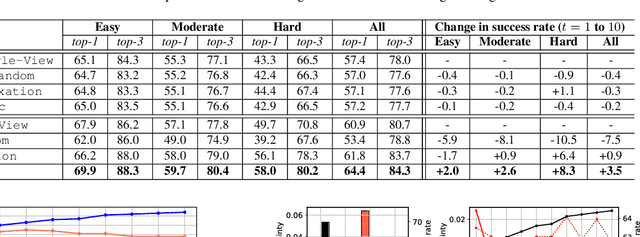
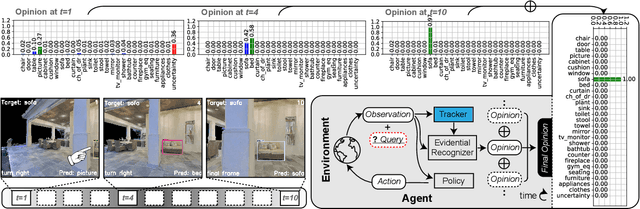
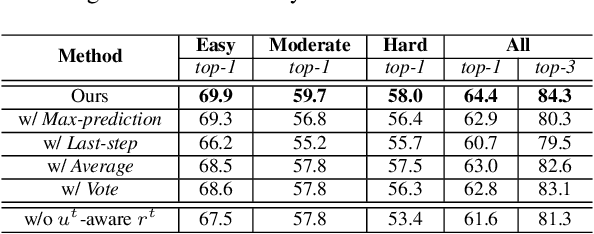
Active recognition enables robots to intelligently explore novel observations, thereby acquiring more information while circumventing undesired viewing conditions. Recent approaches favor learning policies from simulated or collected data, wherein appropriate actions are more frequently selected when the recognition is accurate. However, most recognition modules are developed under the closed-world assumption, which makes them ill-equipped to handle unexpected inputs, such as the absence of the target object in the current observation. To address this issue, we propose treating active recognition as a sequential evidence-gathering process, providing by-step uncertainty quantification and reliable prediction under the evidence combination theory. Additionally, the reward function developed in this paper effectively characterizes the merit of actions when operating in open-world environments. To evaluate the performance, we collect a dataset from an indoor simulator, encompassing various recognition challenges such as distance, occlusion levels, and visibility. Through a series of experiments on recognition and robustness analysis, we demonstrate the necessity of introducing uncertainties to active recognition and the superior performance of the proposed method.
GS-Pose: Category-Level Object Pose Estimation via Geometric and Semantic Correspondence
Nov 23, 2023Category-level pose estimation is a challenging task with many potential applications in computer vision and robotics. Recently, deep-learning-based approaches have made great progress, but are typically hindered by the need for large datasets of either pose-labelled real images or carefully tuned photorealistic simulators. This can be avoided by using only geometry inputs such as depth images to reduce the domain-gap but these approaches suffer from a lack of semantic information, which can be vital in the pose estimation problem. To resolve this conflict, we propose to utilize both geometric and semantic features obtained from a pre-trained foundation model.Our approach projects 2D features from this foundation model into 3D for a single object model per category, and then performs matching against this for new single view observations of unseen object instances with a trained matching network. This requires significantly less data to train than prior methods since the semantic features are robust to object texture and appearance. We demonstrate this with a rich evaluation, showing improved performance over prior methods with a fraction of the data required.
Scalable AI Generative Content for Vehicular Network Semantic Communication
Nov 23, 2023Perceiving vehicles in a driver's blind spot is vital for safe driving. The detection of potentially dangerous vehicles in these blind spots can benefit from vehicular network semantic communication technology. However, efficient semantic communication involves a trade-off between accuracy and delay, especially in bandwidth-limited situations. This paper unveils a scalable Artificial Intelligence Generated Content (AIGC) system that leverages an encoder-decoder architecture. This system converts images into textual representations and reconstructs them into quality-acceptable images, optimizing transmission for vehicular network semantic communication. Moreover, when bandwidth allows, auxiliary information is integrated. The encoder-decoder aims to maintain semantic equivalence with the original images across various tasks. Then the proposed approach employs reinforcement learning to enhance the reliability of the generated contents. Experimental results suggest that the proposed method surpasses the baseline in perceiving vehicles in blind spots and effectively compresses communication data. While this method is specifically designed for driving scenarios, this encoder-decoder architecture also holds potential for wide use across various semantic communication scenarios.