 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Graph Attention Autoencoder for Attributed Networks using K-means Loss
Nov 24, 2023
Several natural phenomena and complex systems are often represented as networks. Discovering their community structure is a fundamental task for understanding these networks. Many algorithms have been proposed, but recently, Graph Neural Networks (GNN) have emerged as a compelling approach for enhancing this task.In this paper, we introduce a simple, efficient, and clustering-oriented model based on unsupervised \textbf{G}raph Attention \textbf{A}uto\textbf{E}ncoder for community detection in attributed networks (GAECO). The proposed model adeptly learns representations from both the network's topology and attribute information, simultaneously addressing dual objectives: reconstruction and community discovery. It places a particular emphasis on discovering compact communities by robustly minimizing clustering errors. The model employs k-means as an objective function and utilizes a multi-head Graph Attention Auto-Encoder for decoding the representations. Experiments conducted on three datasets of attributed networks show that our method surpasses state-of-the-art algorithms in terms of NMI and ARI. Additionally, our approach scales effectively with the size of the network, making it suitable for large-scale applications. The implications of our findings extend beyond biological network interpretation and social network analysis, where knowledge of the fundamental community structure is essential.
Next-gen traffic surveillance: AI-assisted mobile traffic violation detection system
Nov 24, 2023Road traffic accidents pose a significant global public health concern, leading to injuries, fatalities, and vehicle damage. Approximately 1,3 million people lose their lives daily due to traffic accidents [World Health Organization, 2022]. Addressing this issue requires accurate traffic law violation detection systems to ensure adherence to regulations. The integration of Artificial Intelligence algorithms, leveraging machine learning and computer vision, has facilitated the development of precise traffic rule enforcement. This paper illustrates how computer vision and machine learning enable the creation of robust algorithms for detecting various traffic violations. Our model, capable of identifying six common traffic infractions, detects red light violations, illegal use of breakdown lanes, violations of vehicle following distance, breaches of marked crosswalk laws, illegal parking, and parking on marked crosswalks. Utilizing online traffic footage and a self-mounted on-dash camera, we apply the YOLOv5 algorithm's detection module to identify traffic agents such as cars, pedestrians, and traffic signs, and the strongSORT algorithm for continuous interframe tracking. Six discrete algorithms analyze agents' behavior and trajectory to detect violations. Subsequently, an Identification Module extracts vehicle ID information, such as the license plate, to generate violation notices sent to relevant authorities.
Efficient Open-world Reinforcement Learning via Knowledge Distillation and Autonomous Rule Discovery
Nov 24, 2023Deep reinforcement learning suffers from catastrophic forgetting and sample inefficiency making it less applicable to the ever-changing real world. However, the ability to use previously learned knowledge is essential for AI agents to quickly adapt to novelties. Often, certain spatial information observed by the agent in the previous interactions can be leveraged to infer task-specific rules. Inferred rules can then help the agent to avoid potentially dangerous situations in the previously unseen states and guide the learning process increasing agent's novelty adaptation speed. In this work, we propose a general framework that is applicable to deep reinforcement learning agents. Our framework provides the agent with an autonomous way to discover the task-specific rules in the novel environments and self-supervise it's learning. We provide a rule-driven deep Q-learning agent (RDQ) as one possible implementation of that framework. We show that RDQ successfully extracts task-specific rules as it interacts with the world and uses them to drastically increase its learning efficiency. In our experiments, we show that the RDQ agent is significantly more resilient to the novelties than the baseline agents, and is able to detect and adapt to novel situations faster.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Nov 24, 2023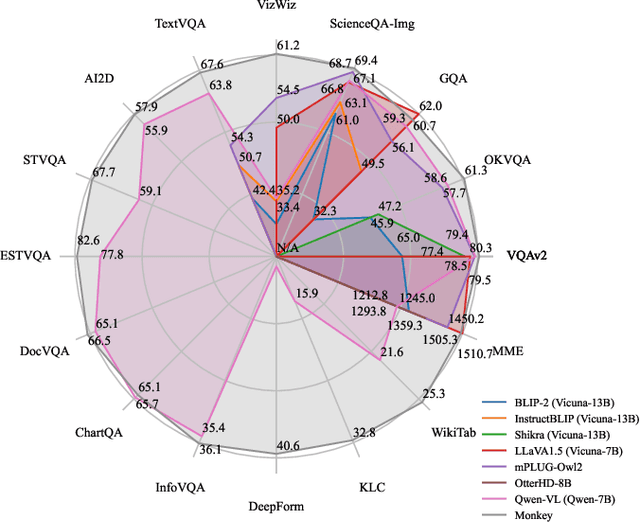
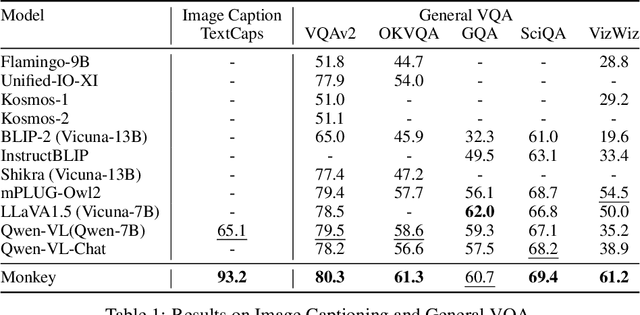
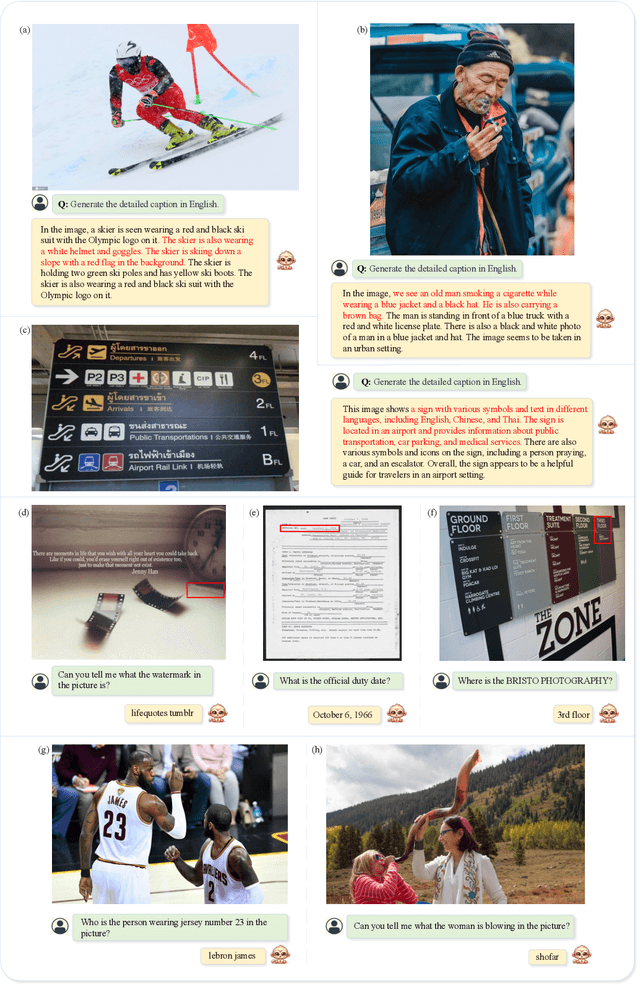
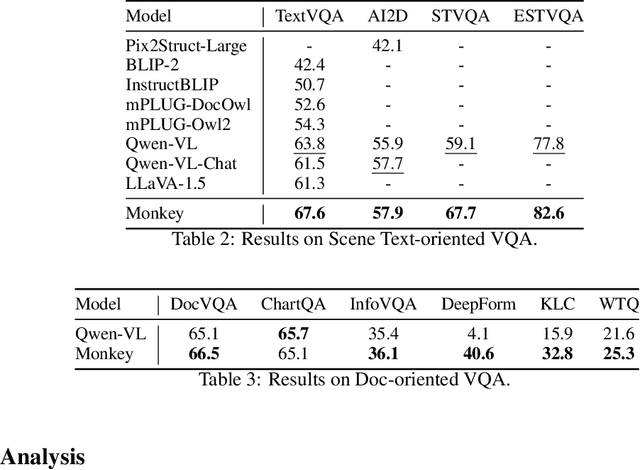
Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448x448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344x896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
Robust Tumor Segmentation with Hyperspectral Imaging and Graph Neural Networks
Nov 20, 2023Segmenting the boundary between tumor and healthy tissue during surgical cancer resection poses a significant challenge. In recent years, Hyperspectral Imaging (HSI) combined with Machine Learning (ML) has emerged as a promising solution. However, due to the extensive information contained within the spectral domain, most ML approaches primarily classify individual HSI (super-)pixels, or tiles, without taking into account their spatial context. In this paper, we propose an improved methodology that leverages the spatial context of tiles for more robust and smoother segmentation. To address the irregular shapes of tiles, we utilize Graph Neural Networks (GNNs) to propagate context information across neighboring regions. The features for each tile within the graph are extracted using a Convolutional Neural Network (CNN), which is trained simultaneously with the subsequent GNN. Moreover, we incorporate local image quality metrics into the loss function to enhance the training procedure's robustness against low-quality regions in the training images. We demonstrate the superiority of our proposed method using a clinical ex vivo dataset consisting of 51 HSI images from 30 patients. Despite the limited dataset, the GNN-based model significantly outperforms context-agnostic approaches, accurately distinguishing between healthy and tumor tissues, even in images from previously unseen patients. Furthermore, we show that our carefully designed loss function, accounting for local image quality, results in additional improvements. Our findings demonstrate that context-aware GNN algorithms can robustly find tumor demarcations on HSI images, ultimately contributing to better surgery success and patient outcome.
Exploring Semi-supervised Hierarchical Stacked Encoder for Legal Judgement Prediction
Nov 14, 2023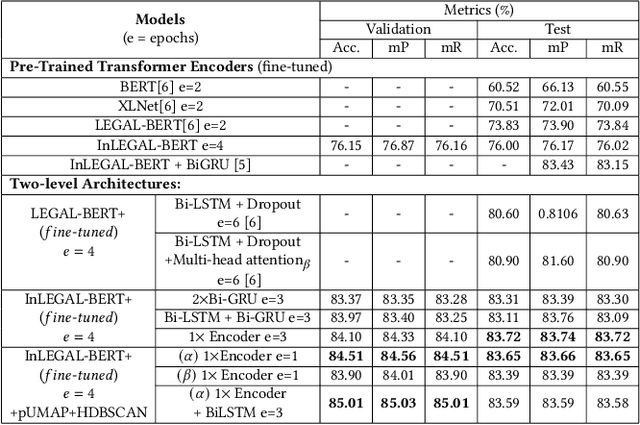
Predicting the judgment of a legal case from its unannotated case facts is a challenging task. The lengthy and non-uniform document structure poses an even greater challenge in extracting information for decision prediction. In this work, we explore and propose a two-level classification mechanism; both supervised and unsupervised; by using domain-specific pre-trained BERT to extract information from long documents in terms of sentence embeddings further processing with transformer encoder layer and use unsupervised clustering to extract hidden labels from these embeddings to better predict a judgment of a legal case. We conduct several experiments with this mechanism and see higher performance gains than the previously proposed methods on the ILDC dataset. Our experimental results also show the importance of domain-specific pre-training of Transformer Encoders in legal information processing.
The Analysis and Extraction of Structure from Organizational Charts
Nov 16, 2023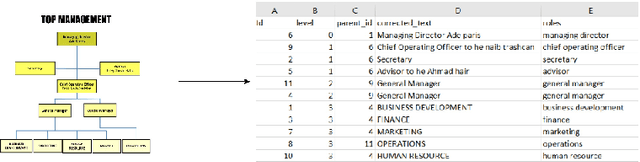
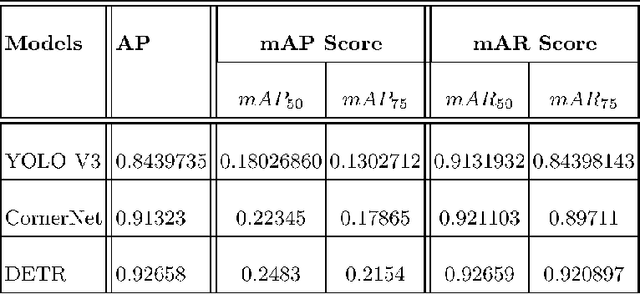
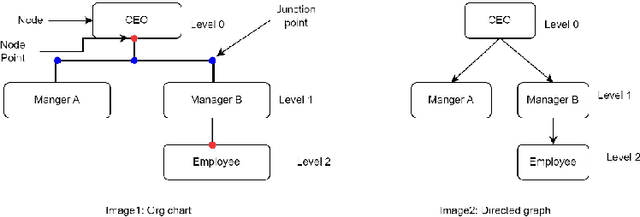
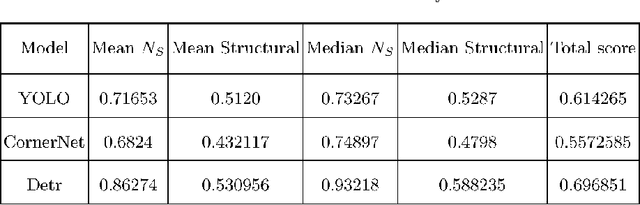
Organizational charts, also known as org charts, are critical representations of an organization's structure and the hierarchical relationships between its components and positions. However, manually extracting information from org charts can be error-prone and time-consuming. To solve this, we present an automated and end-to-end approach that uses computer vision, deep learning, and natural language processing techniques. Additionally, we propose a metric to evaluate the completeness and hierarchical accuracy of the extracted information. This approach has the potential to improve organizational restructuring and resource utilization by providing a clear and concise representation of the organizational structure. Our study lays a foundation for further research on the topic of hierarchical chart analysis.
InfoCL: Alleviating Catastrophic Forgetting in Continual Text Classification from An Information Theoretic Perspective
Oct 10, 2023
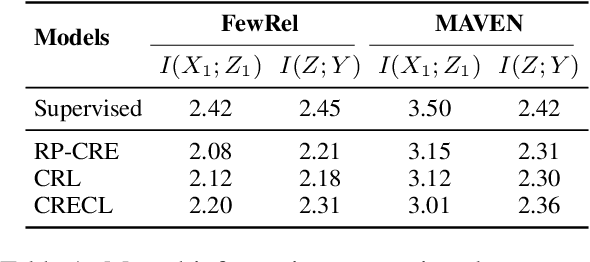
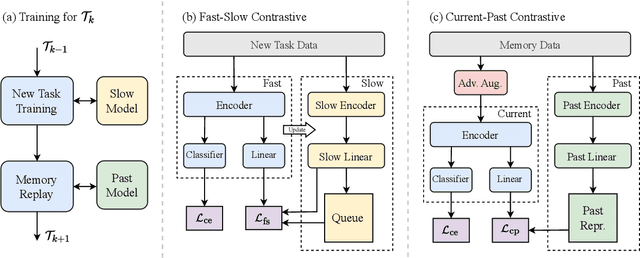
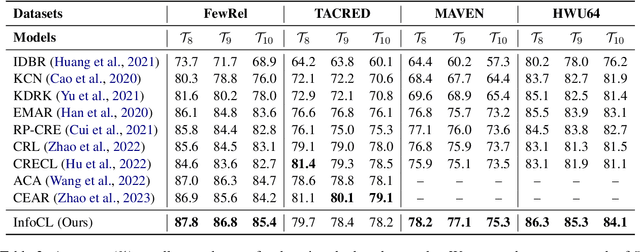
Continual learning (CL) aims to constantly learn new knowledge over time while avoiding catastrophic forgetting on old tasks. We focus on continual text classification under the class-incremental setting. Recent CL studies have identified the severe performance decrease on analogous classes as a key factor for catastrophic forgetting. In this paper, through an in-depth exploration of the representation learning process in CL, we discover that the compression effect of the information bottleneck leads to confusion on analogous classes. To enable the model learn more sufficient representations, we propose a novel replay-based continual text classification method, InfoCL. Our approach utilizes fast-slow and current-past contrastive learning to perform mutual information maximization and better recover the previously learned representations. In addition, InfoCL incorporates an adversarial memory augmentation strategy to alleviate the overfitting problem of replay. Experimental results demonstrate that InfoCL effectively mitigates forgetting and achieves state-of-the-art performance on three text classification tasks. The code is publicly available at https://github.com/Yifan-Song793/InfoCL.
Benchmarking Machine Learning Models for Quantum Error Correction
Nov 18, 2023Quantum Error Correction (QEC) is one of the fundamental problems in quantum computer systems, which aims to detect and correct errors in the data qubits within quantum computers. Due to the presence of unreliable data qubits in existing quantum computers, implementing quantum error correction is a critical step when establishing a stable quantum computer system. Recently, machine learning (ML)-based approaches have been proposed to address this challenge. However, they lack a thorough understanding of quantum error correction. To bridge this research gap, we provide a new perspective to understand machine learning-based QEC in this paper. We find that syndromes in the ancilla qubits result from errors on connected data qubits, and distant ancilla qubits can provide auxiliary information to rule out some incorrect predictions for the data qubits. Therefore, to detect errors in data qubits, we must consider the information present in the long-range ancilla qubits. To the best of our knowledge, machine learning is less explored in the dependency relationship of QEC. To fill the blank, we curate a machine learning benchmark to assess the capacity to capture long-range dependencies for quantum error correction. To provide a comprehensive evaluation, we evaluate seven state-of-the-art deep learning algorithms spanning diverse neural network architectures, such as convolutional neural networks, graph neural networks, and graph transformers. Our exhaustive experiments reveal an enlightening trend: By enlarging the receptive field to exploit information from distant ancilla qubits, the accuracy of QEC significantly improves. For instance, U-Net can improve CNN by a margin of about 50%. Finally, we provide a comprehensive analysis that could inspire future research in this field. We will release the code when the paper is published.
3D-GOI: 3D GAN Omni-Inversion for Multifaceted and Multi-object Editing
Nov 18, 2023The current GAN inversion methods typically can only edit the appearance and shape of a single object and background while overlooking spatial information. In this work, we propose a 3D editing framework, 3D-GOI, to enable multifaceted editing of affine information (scale, translation, and rotation) on multiple objects. 3D-GOI realizes the complex editing function by inverting the abundance of attribute codes (object shape/appearance/scale/rotation/translation, background shape/appearance, and camera pose) controlled by GIRAFFE, a renowned 3D GAN. Accurately inverting all the codes is challenging, 3D-GOI solves this challenge following three main steps. First, we segment the objects and the background in a multi-object image. Second, we use a custom Neural Inversion Encoder to obtain coarse codes of each object. Finally, we use a round-robin optimization algorithm to get precise codes to reconstruct the image. To the best of our knowledge, 3D-GOI is the first framework to enable multifaceted editing on multiple objects. Both qualitative and quantitative experiments demonstrate that 3D-GOI holds immense potential for flexible, multifaceted editing in complex multi-object scenes.