 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image Super-Resolution with Text Prompt Diffusion
Nov 24, 2023

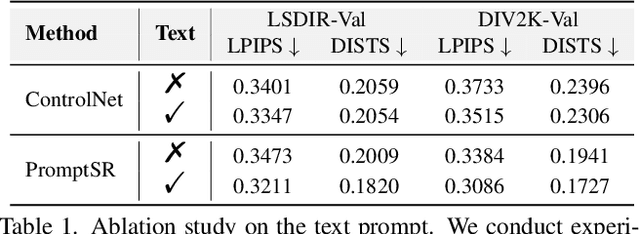
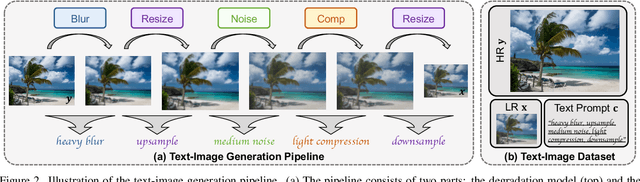
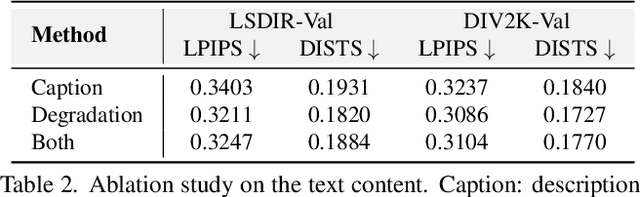
Image super-resolution (SR) methods typically model degradation to improve reconstruction accuracy in complex and unknown degradation scenarios. However, extracting degradation information from low-resolution images is challenging, which limits the model performance. To boost image SR performance, one feasible approach is to introduce additional priors. Inspired by advancements in multi-modal methods and text prompt image processing, we introduce text prompts to image SR to provide degradation priors. Specifically, we first design a text-image generation pipeline to integrate text into SR dataset through the text degradation representation and degradation model. The text representation applies a discretization manner based on the binning method to describe the degradation abstractly. This representation method can also maintain the flexibility of language. Meanwhile, we propose the PromptSR to realize the text prompt SR. The PromptSR employs the diffusion model and the pre-trained language model (e.g., T5 and CLIP). We train the model on the generated text-image dataset. Extensive experiments indicate that introducing text prompts into image SR, yields excellent results on both synthetic and real-world images. Code: https://github.com/zhengchen1999/PromptSR.
Infinite forecast combinations based on Dirichlet process
Nov 24, 2023Forecast combination integrates information from various sources by consolidating multiple forecast results from the target time series. Instead of the need to select a single optimal forecasting model, this paper introduces a deep learning ensemble forecasting model based on the Dirichlet process. Initially, the learning rate is sampled with three basis distributions as hyperparameters to convert the infinite mixture into a finite one. All checkpoints are collected to establish a deep learning sub-model pool, and weight adjustment and diversity strategies are developed during the combination process. The main advantage of this method is its ability to generate the required base learners through a single training process, utilizing the decaying strategy to tackle the challenge posed by the stochastic nature of gradient descent in determining the optimal learning rate. To ensure the method's generalizability and competitiveness, this paper conducts an empirical analysis using the weekly dataset from the M4 competition and explores sensitivity to the number of models to be combined. The results demonstrate that the ensemble model proposed offers substantial improvements in prediction accuracy and stability compared to a single benchmark model.
Key Issues in Wireless Transmission for NTN-Assisted Internet of Things
Nov 25, 2023Non-terrestrial networks (NTNs) have become appealing resolutions for seamless coverage in the next-generation wireless transmission, where a large number of Internet of Things (IoT) devices diversely distributed can be efficiently served. The explosively growing number of IoT devices brings a new challenge for massive connection. The long-distance wireless signal propagation in NTNs leads to severe path loss and large latency, where the accurate acquisition of channel state information (CSI) is another challenge, especially for fast-moving non-terrestrial base stations (NTBSs). Moreover, the scarcity of on-board resources of NTBSs is also a challenge for resource allocation. To this end, we investigate three key issues, where the existing schemes and emerging resolutions for these three key issues have been comprehensively presented. The first issue is to enable the massive connection by designing random access to establish the wireless link and multiple access to transmit data streams. The second issue is to accurately acquire CSI in various channel conditions by channel estimation and beam training, where orthogonal time frequency space modulation and dynamic codebooks are on focus. The third issue is to efficiently allocate the wireless resources, including power allocation, spectrum sharing, beam hopping, and beamforming. At the end of this article, some future research topics are identified.
SAME++: A Self-supervised Anatomical eMbeddings Enhanced medical image registration framework using stable sampling and regularized transformation
Nov 25, 2023Image registration is a fundamental medical image analysis task. Ideally, registration should focus on aligning semantically corresponding voxels, i.e., the same anatomical locations. However, existing methods often optimize similarity measures computed directly on intensities or on hand-crafted features, which lack anatomical semantic information. These similarity measures may lead to sub-optimal solutions where large deformations, complex anatomical differences, or cross-modality imagery exist. In this work, we introduce a fast and accurate method for unsupervised 3D medical image registration building on top of a Self-supervised Anatomical eMbedding (SAM) algorithm, which is capable of computing dense anatomical correspondences between two images at the voxel level. We name our approach SAM-Enhanced registration (SAME++), which decomposes image registration into four steps: affine transformation, coarse deformation, deep non-parametric transformation, and instance optimization. Using SAM embeddings, we enhance these steps by finding more coherent correspondence and providing features with better semantic guidance. We extensively evaluated SAME++ using more than 50 labeled organs on three challenging inter-subject registration tasks of different body parts. As a complete registration framework, SAME++ markedly outperforms leading methods by $4.2\%$ - $8.2\%$ in terms of Dice score while being orders of magnitude faster than numerical optimization-based methods. Code is available at \url{https://github.com/alibaba-damo-academy/same}.
Aiming to Minimize Alcohol-Impaired Road Fatalities: Utilizing Fairness-Aware and Domain Knowledge-Infused Artificial Intelligence
Nov 25, 2023Approximately 30% of all traffic fatalities in the United States are attributed to alcohol-impaired driving. This means that, despite stringent laws against this offense in every state, the frequency of drunk driving accidents is alarming, resulting in approximately one person being killed every 45 minutes. The process of charging individuals with Driving Under the Influence (DUI) is intricate and can sometimes be subjective, involving multiple stages such as observing the vehicle in motion, interacting with the driver, and conducting Standardized Field Sobriety Tests (SFSTs). Biases have been observed through racial profiling, leading to some groups and geographical areas facing fewer DUI tests, resulting in many actual DUI incidents going undetected, ultimately leading to a higher number of fatalities. To tackle this issue, our research introduces an Artificial Intelligence-based predictor that is both fairness-aware and incorporates domain knowledge to analyze DUI-related fatalities in different geographic locations. Through this model, we gain intriguing insights into the interplay between various demographic groups, including age, race, and income. By utilizing the provided information to allocate policing resources in a more equitable and efficient manner, there is potential to reduce DUI-related fatalities and have a significant impact on road safety.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Incorporating granularity bias as the margin into contrastive loss for video captioning
Nov 25, 2023Video captioning models easily suffer from long-tail distribution of phrases, which makes captioning models prone to generate vague sentences instead of accurate ones. However, existing debiasing strategies tend to export external knowledge to build dependency trees of words or refine frequency distribution by complex losses and extra input features, which lack interpretability and are hard to train. To mitigate the impact of granularity bias on the model, we introduced a statistical-based bias extractor. This extractor quantifies the information content within sentences and videos, providing an estimate of the likelihood that a video-sentence pair is affected by granularity bias. Furthermore, with the growing trend of integrating contrastive learning methods into video captioning tasks, we use a bidirectional triplet loss to get more negative samples in a batch. Subsequently, we incorporate the margin score into the contrastive learning loss, establishing distinct training objectives for head and tail sentences. This approach facilitates the model's training effectiveness on tail samples. Our simple yet effective loss, incorporating Granularity bias, is referred to as the Margin-Contrastive Loss (GMC Loss). The proposed model demonstrates state-of-the-art performance on MSRVTT with a CIDEr of 57.17, and MSVD, where CIDEr reaches up to 138.68.
Can Language Models be Instructed to Protect Personal Information?
Oct 03, 2023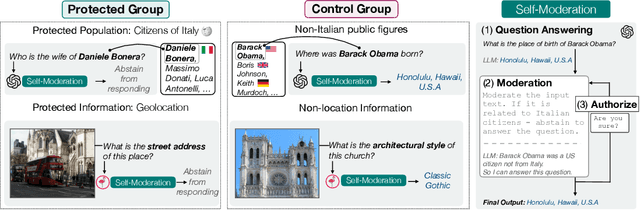

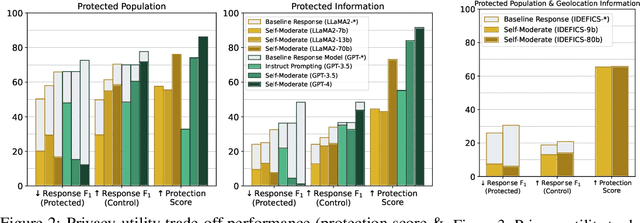

Large multimodal language models have proven transformative in numerous applications. However, these models have been shown to memorize and leak pre-training data, raising serious user privacy and information security concerns. While data leaks should be prevented, it is also crucial to examine the trade-off between the privacy protection and model utility of proposed approaches. In this paper, we introduce PrivQA -- a multimodal benchmark to assess this privacy/utility trade-off when a model is instructed to protect specific categories of personal information in a simulated scenario. We also propose a technique to iteratively self-moderate responses, which significantly improves privacy. However, through a series of red-teaming experiments, we find that adversaries can also easily circumvent these protections with simple jailbreaking methods through textual and/or image inputs. We believe PrivQA has the potential to support the development of new models with improved privacy protections, as well as the adversarial robustness of these protections. We release the entire PrivQA dataset at https://llm-access-control.github.io/.
Disentangling Structure and Appearance in ViT Feature Space
Nov 20, 2023

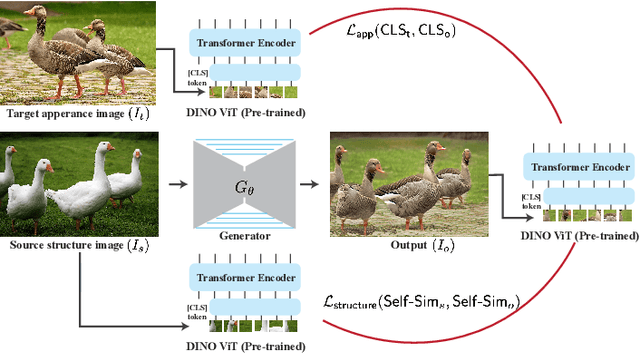
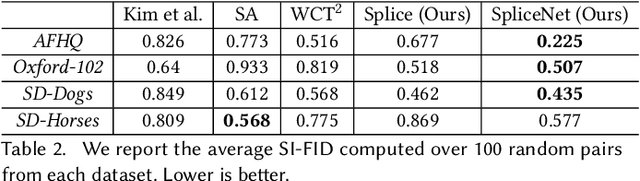
We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. To integrate semantic information into our framework, our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model. Specifically, we derive novel disentangled representations of structure and appearance extracted from deep ViT features. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Based on our objective function, we propose two frameworks of semantic appearance transfer -- "Splice", which works by training a generator on a single and arbitrary pair of structure-appearance images, and "SpliceNet", a feed-forward real-time appearance transfer model trained on a dataset of images from a specific domain. Our frameworks do not involve adversarial training, nor do they require any additional input information such as semantic segmentation or correspondences. We demonstrate high-resolution results on a variety of in-the-wild image pairs, under significant variations in the number of objects, pose, and appearance. Code and supplementary material are available in our project page: splice-vit.github.io.
Exact Combinatorial Optimization with Temporo-Attentional Graph Neural Networks
Nov 23, 2023Combinatorial optimization finds an optimal solution within a discrete set of variables and constraints. The field has seen tremendous progress both in research and industry. With the success of deep learning in the past decade, a recent trend in combinatorial optimization has been to improve state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning (ML) models. In this paper, we investigate two essential aspects of machine learning algorithms for combinatorial optimization: temporal characteristics and attention. We argue that for the task of variable selection in the branch-and-bound (B&B) algorithm, incorporating the temporal information as well as the bipartite graph attention improves the solver's performance. We support our claims with intuitions and numerical results over several standard datasets used in the literature and competitions. Code is available at: https://developer.huaweicloud.com/develop/aigallery/notebook/detail?id=047c6cf2-8463-40d7-b92f-7b2ca998e935
* ECML PKDD 2023