 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-to-Text Bilingual Generation
Nov 24, 2023
This document illustrates the use of pyrealb for generating two parallel texts (English and French) from a single source of data. The data selection and text organisation processes are shared between the two languages. only language dependent word and phrasing choices are distinct processes. The realized texts thus convey identical information in both languages without the risk of being lost in translation. This is especially important in cases where strict and simultaneous bilingualism is required. We first present the types of applications targeted by this approach and how the pyrealb English and French realizer can be used for achieving this goal in a natural way. We describe an object-oriented organization to ensure a convenient realization in both languages. To illustrate the process, different types of applications are then briefly sketched with links to the source code. A brief comparison of the text generation is given with the output of an instance of a GPT.
Angular-Distance Based Channel Estimation for Holographic MIMO
Nov 26, 2023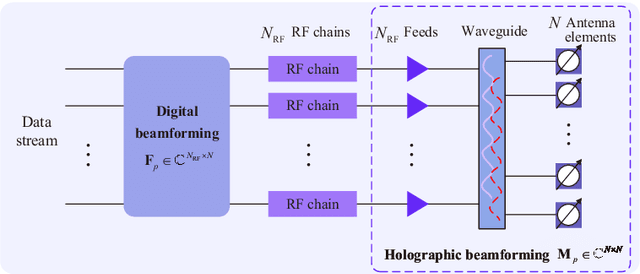
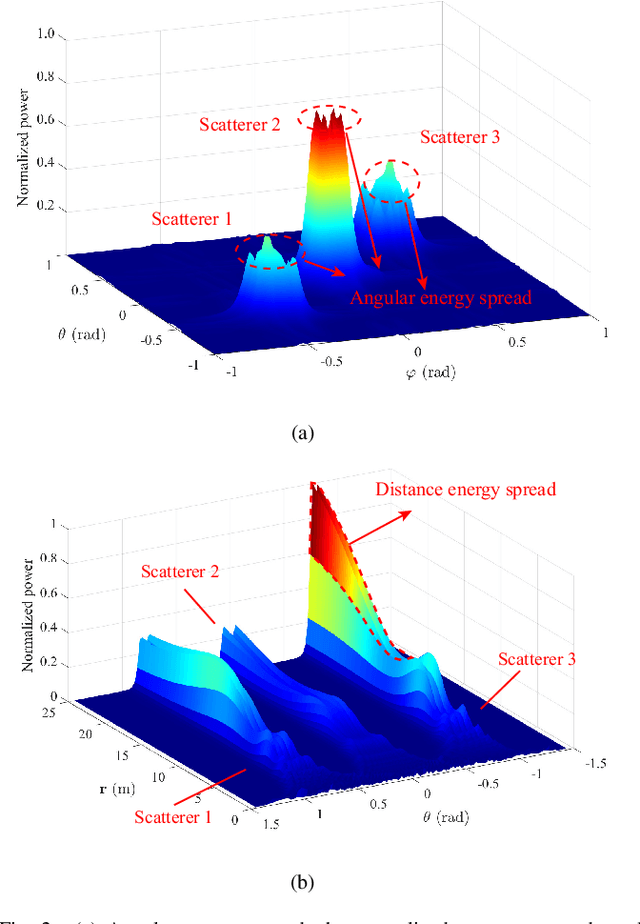
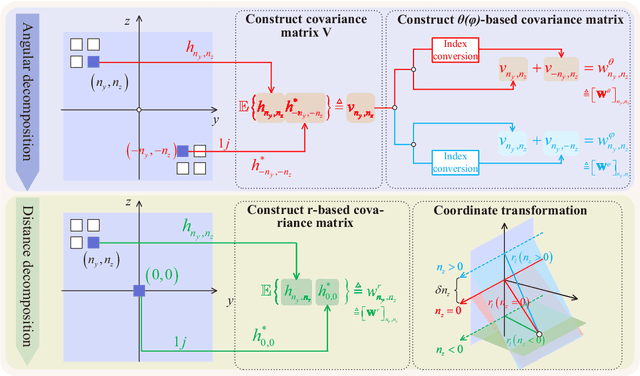
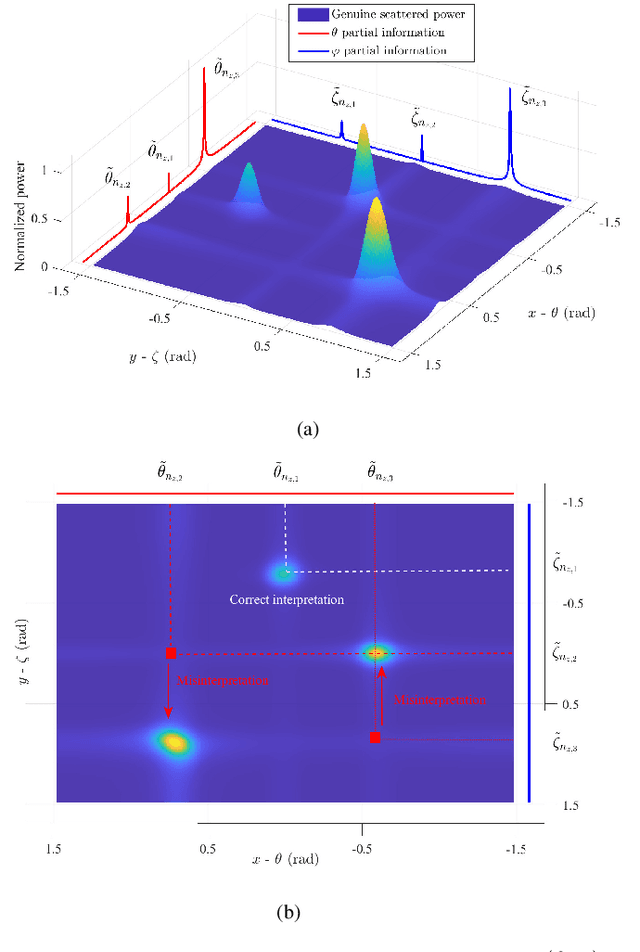
This paper investigates the channel estimation for holographic MIMO systems by unmasking their distinctions from the conventional one. Specifically, we elucidate that the channel estimation, subject to holographic MIMO's electromagnetically large antenna arrays, has to discriminate not only the angles of a user/scatterer but also its distance information, namely the three-dimensional (3D) azimuth and elevation angles plus the distance (AED) parameters. As the angular-domain representation fails to characterize the sparsity inherent in holographic MIMO channels, the tightly coupled 3D AED parameters are firstly decomposed for independently constructing their own covariance matrices. Then, the recovery of each individual parameter can be structured as a compressive sensing (CS) problem by harnessing the covariance matrix constructed. This pair of techniques contribute to a parametric decomposition and compressed deconstruction (DeRe) framework, along with a formulation of the maximum likelihood estimation for each parameter. Then, an efficient algorithm, namely DeRe-based variational Bayesian inference and message passing (DeRe-VM), is proposed for the sharp detection of the 3D AED parameters and the robust recovery of sparse channels. Finally, the proposed channel estimation regime is confirmed to be of great robustness in accommodating different channel conditions, regardless of the near-field and far-field contexts of a holographic MIMO system, as well as an improved performance in comparison to the state-of-the-art benchmarks.
Deep Refinement-Based Joint Source Channel Coding over Time-Varying Channels
Nov 26, 2023In recent developments, deep learning (DL)-based joint source-channel coding (JSCC) for wireless image transmission has made significant strides in performance enhancement. Nonetheless, the majority of existing DL-based JSCC methods are tailored for scenarios featuring stable channel conditions, notably a fixed signal-to-noise ratio (SNR). This specialization poses a limitation, as their performance tends to wane in practical scenarios marked by highly dynamic channels, given that a fixed SNR inadequately represents the dynamic nature of such channels. In response to this challenge, we introduce a novel solution, namely deep refinement-based JSCC (DRJSCC). This innovative method is designed to seamlessly adapt to channels exhibiting temporal variations. By leveraging instantaneous channel state information (CSI), we dynamically optimize the encoding strategy through re-encoding the channel symbols. This dynamic adjustment ensures that the encoding strategy consistently aligns with the varying channel conditions during the transmission process. Specifically, our approach begins with the division of encoded symbols into multiple blocks, which are transmitted progressively to the receiver. In the event of changing channel conditions, we propose a mechanism to re-encode the remaining blocks, allowing them to adapt to the current channel conditions. Experimental results show that the DRJSCC scheme achieves comparable performance to the other mainstream DL-based JSCC models in stable channel conditions, and also exhibits great robustness against time-varying channels.
Digital Twin Framework for Optimal and Autonomous Decision-Making in Cyber-Physical Systems: Enhancing Reliability and Adaptability in the Oil and Gas Industry
Nov 21, 2023The concept of creating a virtual copy of a complete Cyber-Physical System opens up numerous possibilities, including real-time assessments of the physical environment and continuous learning from the system to provide reliable and precise information. This process, known as the twinning process or the development of a digital twin (DT), has been widely adopted across various industries. However, challenges arise when considering the computational demands of implementing AI models, such as those employed in digital twins, in real-time information exchange scenarios. This work proposes a digital twin framework for optimal and autonomous decision-making applied to a gas-lift process in the oil and gas industry, focusing on enhancing the robustness and adaptability of the DT. The framework combines Bayesian inference, Monte Carlo simulations, transfer learning, online learning, and novel strategies to confer cognition to the DT, including model hyperdimensional reduction and cognitive tack. Consequently, creating a framework for efficient, reliable, and trustworthy DT identification was possible. The proposed approach addresses the current gap in the literature regarding integrating various learning techniques and uncertainty management in digital twin strategies. This digital twin framework aims to provide a reliable and efficient system capable of adapting to changing environments and incorporating prediction uncertainty, thus enhancing the overall decision-making process in complex, real-world scenarios. Additionally, this work lays the foundation for further developments in digital twins for process systems engineering, potentially fostering new advancements and applications across various industrial sectors.
Multiuser Beamforming for Partially-Connected Millimeter Wave Massive MIMO
Nov 25, 2023Multiuser beamforming is considered for partially-connected millimeter wave massive MIMO systems. Based on perfect channel state information (CSI), a low-complexity hybrid beamforming scheme that decouples the analog beamformer and the digital beamformer is proposed to maximize the sum-rate. The analog beamformer design is modeled as a phase alignment problem to harvest the array gain. Given the analog beamformer, the digital beamformer is designed by solving a weighted minimum mean squared error problem. Then based on imperfect CSI, an analog-only beamformer design scheme is proposed, where the design problem aims at maximizing the desired signal power on the current user and minimizing the power on the other users to mitigate the multiuser interference. The original problem is then transformed into a series of independent beam nulling subproblems, where an efficient iterative algorithm using the majorization-minimization framework is proposed to solve the subproblems. Simulation results show that, under perfect CSI, the proposed scheme achieves almost the same sum-rate performance as the existing schemes but with lower computational complexity; and under imperfect CSI, the proposed analog-only beamforming design scheme can effectively mitigate the multiuser interference.
CUCL: Codebook for Unsupervised Continual Learning
Nov 25, 2023The focus of this study is on Unsupervised Continual Learning (UCL), as it presents an alternative to Supervised Continual Learning which needs high-quality manual labeled data. The experiments under the UCL paradigm indicate a phenomenon where the results on the first few tasks are suboptimal. This phenomenon can render the model inappropriate for practical applications. To address this issue, after analyzing the phenomenon and identifying the lack of diversity as a vital factor, we propose a method named Codebook for Unsupervised Continual Learning (CUCL) which promotes the model to learn discriminative features to complete the class boundary. Specifically, we first introduce a Product Quantization to inject diversity into the representation and apply a cross quantized contrastive loss between the original representation and the quantized one to capture discriminative information. Then, based on the quantizer, we propose an effective Codebook Rehearsal to address catastrophic forgetting. This study involves conducting extensive experiments on CIFAR100, TinyImageNet, and MiniImageNet benchmark datasets. Our method significantly boosts the performances of supervised and unsupervised methods. For instance, on TinyImageNet, our method led to a relative improvement of 12.76% and 7% when compared with Simsiam and BYOL, respectively.
Characterizing Tradeoffs in Language Model Decoding with Informational Interpretations
Nov 16, 2023We propose a theoretical framework for formulating language model decoder algorithms with dynamic programming and information theory. With dynamic programming, we lift the design of decoder algorithms from the logit space to the action-state value function space, and show that the decoding algorithms are consequences of optimizing the action-state value functions. Each component in the action-state value function space has an information theoretical interpretation. With the lifting and interpretation, it becomes evident what the decoder algorithm is optimized for, and hence facilitating the arbitration of the tradeoffs in sensibleness, diversity, and attribution.
A Social-aware Gaussian Pre-trained Model for Effective Cold-start Recommendation
Nov 27, 2023The use of pre-training is an emerging technique to enhance a neural model's performance, which has been shown to be effective for many neural language models such as BERT. This technique has also been used to enhance the performance of recommender systems. In such recommender systems, pre-training models are used to learn a better initialisation for both users and items. However, recent existing pre-trained recommender systems tend to only incorporate the user interaction data at the pre-training stage, making it difficult to deliver good recommendations, especially when the interaction data is sparse. To alleviate this common data sparsity issue, we propose to pre-train the recommendation model not only with the interaction data but also with other available information such as the social relations among users, thereby providing the recommender system with a better initialisation compared with solely relying on the user interaction data. We propose a novel recommendation model, the Social-aware Gaussian Pre-trained model (SGP), which encodes the user social relations and interaction data at the pre-training stage in a Graph Neural Network (GNN). Afterwards, in the subsequent fine-tuning stage, our SGP model adopts a Gaussian Mixture Model (GMM) to factorise these pre-trained embeddings for further training, thereby benefiting the cold-start users from these pre-built social relations. Our extensive experiments on three public datasets show that, in comparison to 16 competitive baselines, our SGP model significantly outperforms the best baseline by upto 7.7% in terms of NDCG@10. In addition, we show that SGP permits to effectively alleviate the cold-start problem, especially when users newly register to the system through their friends' suggestions.
Ultra-short-term multi-step wind speed prediction for wind farms based on adaptive noise reduction technology and temporal convolutional network
Nov 27, 2023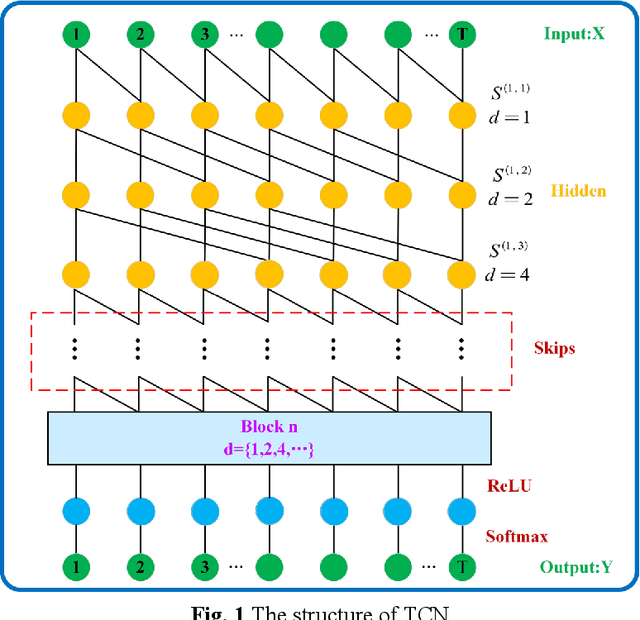
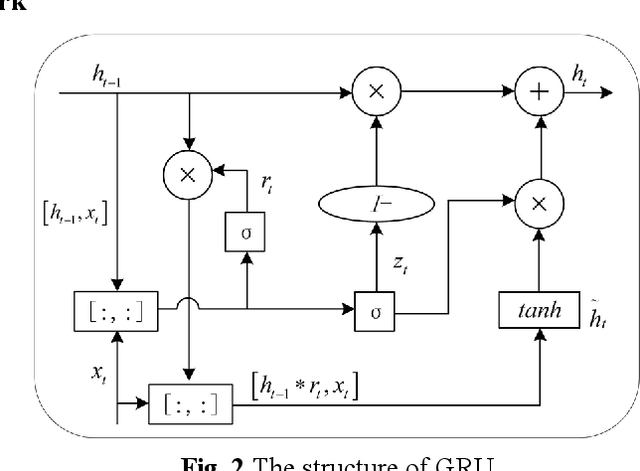

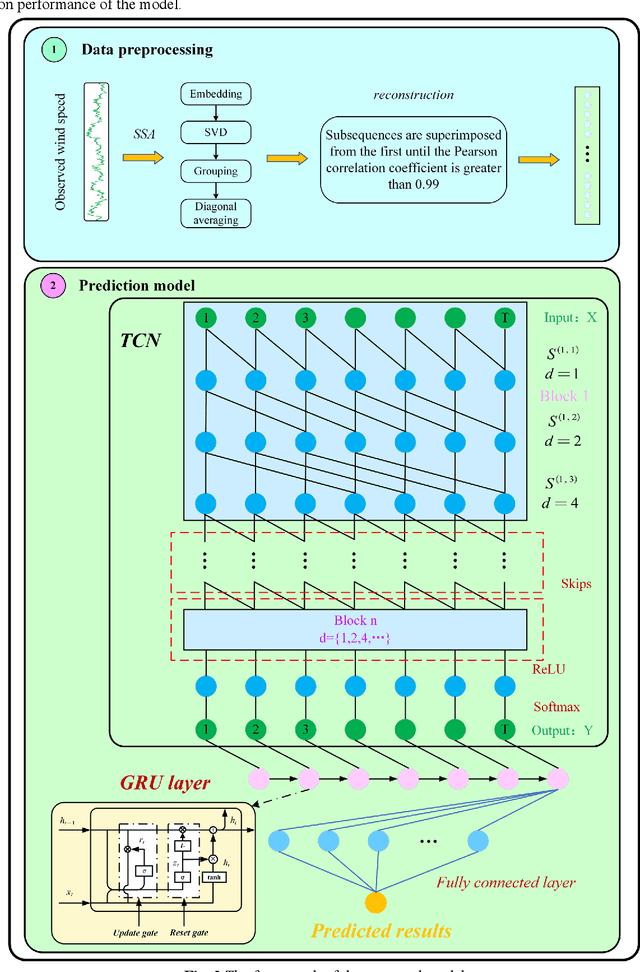
As an important clean and renewable kind of energy, wind power plays an important role in coping with energy crisis and environmental pollution. However, the volatility and intermittency of wind speed restrict the development of wind power. To improve the utilization of wind power, this study proposes a new wind speed prediction model based on data noise reduction technology, temporal convolutional network (TCN), and gated recurrent unit (GRU). Firstly, an adaptive data noise reduction algorithm P-SSA is proposed based on singular spectrum analysis (SSA) and Pearson correlation coefficient. The original wind speed is decomposed into multiple subsequences by SSA and then reconstructed. When the Pearson correlation coefficient between the reconstructed sequence and the original sequence is greater than 0.99, other noise subsequences are deleted to complete the data denoising. Then, the receptive field of the samples is expanded through the causal convolution and dilated convolution of TCN, and the characteristics of wind speed change are extracted. Then, the time feature information of the sequence is extracted by GRU, and then the wind speed is predicted to form the wind speed sequence prediction model of P-SSA-TCN-GRU. The proposed model was validated on three wind farms in Shandong Province. The experimental results show that the prediction performance of the proposed model is better than that of the traditional model and other models based on TCN, and the wind speed prediction of wind farms with high precision and strong stability is realized. The wind speed predictions of this model have the potential to become the data that support the operation and management of wind farms. The code is available at link.
Transformer-QEC: Quantum Error Correction Code Decoding with Transferable Transformers
Nov 27, 2023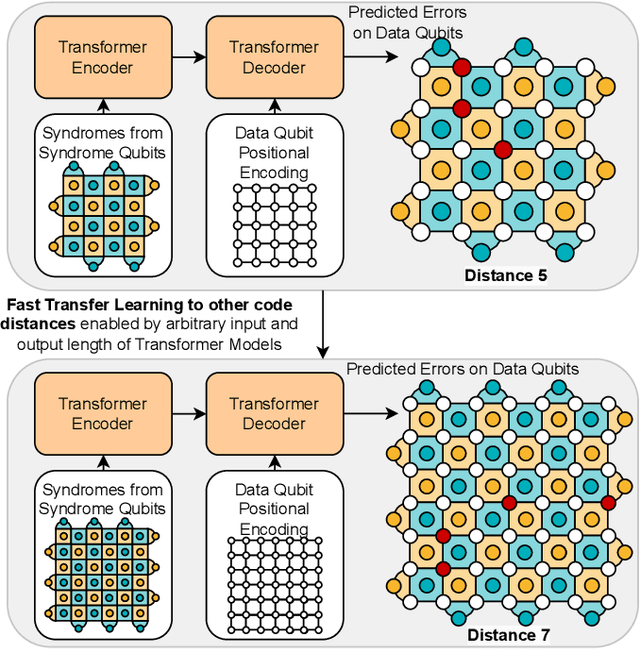
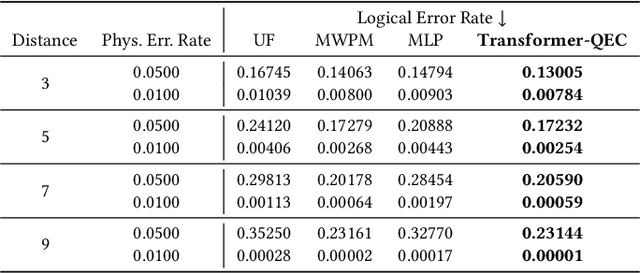
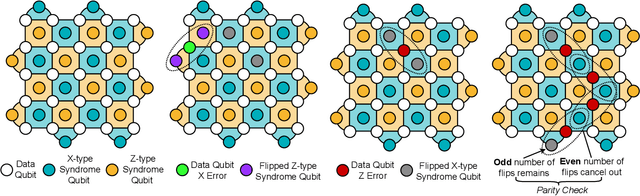
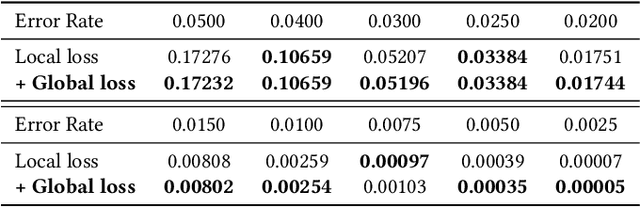
Quantum computing has the potential to solve problems that are intractable for classical systems, yet the high error rates in contemporary quantum devices often exceed tolerable limits for useful algorithm execution. Quantum Error Correction (QEC) mitigates this by employing redundancy, distributing quantum information across multiple data qubits and utilizing syndrome qubits to monitor their states for errors. The syndromes are subsequently interpreted by a decoding algorithm to identify and correct errors in the data qubits. This task is complex due to the multiplicity of error sources affecting both data and syndrome qubits as well as syndrome extraction operations. Additionally, identical syndromes can emanate from different error sources, necessitating a decoding algorithm that evaluates syndromes collectively. Although machine learning (ML) decoders such as multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs) have been proposed, they often focus on local syndrome regions and require retraining when adjusting for different code distances. We introduce a transformer-based QEC decoder which employs self-attention to achieve a global receptive field across all input syndromes. It incorporates a mixed loss training approach, combining both local physical error and global parity label losses. Moreover, the transformer architecture's inherent adaptability to variable-length inputs allows for efficient transfer learning, enabling the decoder to adapt to varying code distances without retraining. Evaluation on six code distances and ten different error configurations demonstrates that our model consistently outperforms non-ML decoders, such as Union Find (UF) and Minimum Weight Perfect Matching (MWPM), and other ML decoders, thereby achieving best logical error rates. Moreover, the transfer learning can save over 10x of training cost.