 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SED: A Simple Encoder-Decoder for Open-Vocabulary Semantic Segmentation
Nov 27, 2023
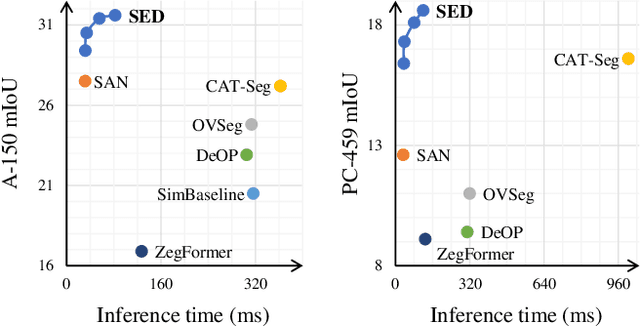
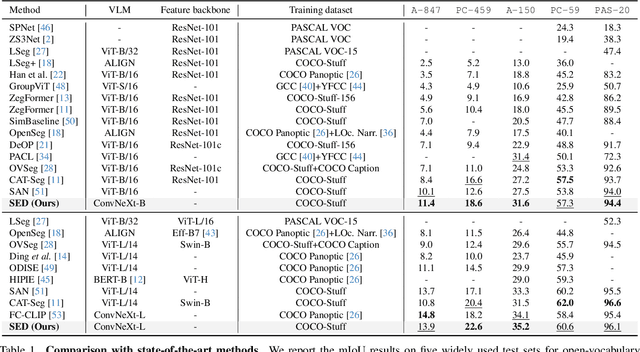
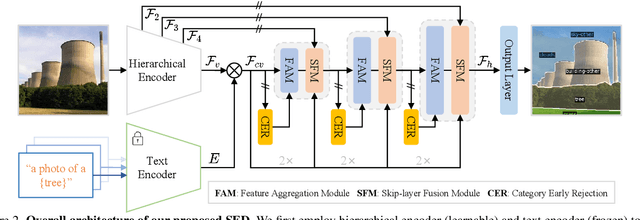
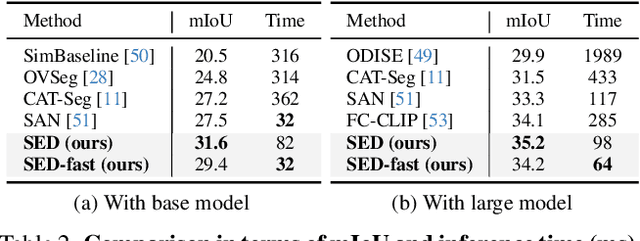
Open-vocabulary semantic segmentation strives to distinguish pixels into different semantic groups from an open set of categories. Most existing methods explore utilizing pre-trained vision-language models, in which the key is to adopt the image-level model for pixel-level segmentation task. In this paper, we propose a simple encoder-decoder, named SED, for open-vocabulary semantic segmentation, which comprises a hierarchical encoder-based cost map generation and a gradual fusion decoder with category early rejection. The hierarchical encoder-based cost map generation employs hierarchical backbone, instead of plain transformer, to predict pixel-level image-text cost map. Compared to plain transformer, hierarchical backbone better captures local spatial information and has linear computational complexity with respect to input size. Our gradual fusion decoder employs a top-down structure to combine cost map and the feature maps of different backbone levels for segmentation. To accelerate inference speed, we introduce a category early rejection scheme in the decoder that rejects many no-existing categories at the early layer of decoder, resulting in at most 4.7 times acceleration without accuracy degradation. Experiments are performed on multiple open-vocabulary semantic segmentation datasets, which demonstrates the efficacy of our SED method. When using ConvNeXt-B, our SED method achieves mIoU score of 31.6\% on ADE20K with 150 categories at 82 millisecond ($ms$) per image on a single A6000. We will release it at \url{https://github.com/xb534/SED.git}.
REACT: Recognize Every Action Everywhere All At Once
Nov 27, 2023Group Activity Recognition (GAR) is a fundamental problem in computer vision, with diverse applications in sports video analysis, video surveillance, and social scene understanding. Unlike conventional action recognition, GAR aims to classify the actions of a group of individuals as a whole, requiring a deep understanding of their interactions and spatiotemporal relationships. To address the challenges in GAR, we present REACT (\textbf{R}ecognize \textbf{E}very \textbf{Act}ion Everywhere All At Once), a novel architecture inspired by the transformer encoder-decoder model explicitly designed to model complex contextual relationships within videos, including multi-modality and spatio-temporal features. Our architecture features a cutting-edge Vision-Language Encoder block for integrated temporal, spatial, and multi-modal interaction modeling. This component efficiently encodes spatiotemporal interactions, even with sparsely sampled frames, and recovers essential local information. Our Action Decoder Block refines the joint understanding of text and video data, allowing us to precisely retrieve bounding boxes, enhancing the link between semantics and visual reality. At the core, our Actor Fusion Block orchestrates a fusion of actor-specific data and textual features, striking a balance between specificity and context. Our method outperforms state-of-the-art GAR approaches in extensive experiments, demonstrating superior accuracy in recognizing and understanding group activities. Our architecture's potential extends to diverse real-world applications, offering empirical evidence of its performance gains. This work significantly advances the field of group activity recognition, providing a robust framework for nuanced scene comprehension.
Enigma: Privacy-Preserving Execution of QAOA on Untrusted Quantum Computers
Nov 22, 2023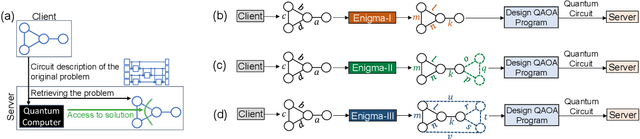
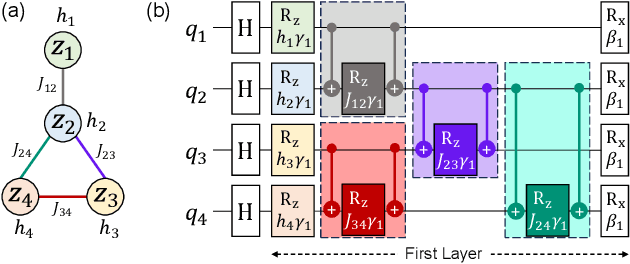
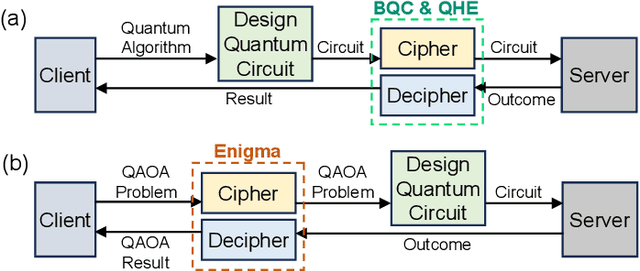
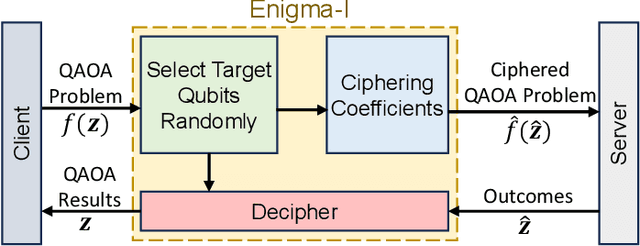
Quantum computers can solve problems that are beyond the capabilities of conventional computers. As quantum computers are expensive and hard to maintain, the typical model for performing quantum computation is to send the circuit to a quantum cloud provider. This leads to privacy concerns for commercial entities as an untrusted server can learn protected information from the provided circuit. Current proposals for Secure Quantum Computing (SQC) either rely on emerging technologies (such as quantum networks) or incur prohibitive overheads (for Quantum Homomorphic Encryption). The goal of our paper is to enable low-cost privacy-preserving quantum computation that can be used with current systems. We propose Enigma, a suite of privacy-preserving schemes specifically designed for the Quantum Approximate Optimization Algorithm (QAOA). Unlike previous SQC techniques that obfuscate quantum circuits, Enigma transforms the input problem of QAOA, such that the resulting circuit and the outcomes are unintelligible to the server. We introduce three variants of Enigma. Enigma-I protects the coefficients of QAOA using random phase flipping and fudging of values. Enigma-II protects the nodes of the graph by introducing decoy qubits, which are indistinguishable from primary ones. Enigma-III protects the edge information of the graph by modifying the graph such that each node has an identical number of connections. For all variants of Enigma, we demonstrate that we can still obtain the solution for the original problem. We evaluate Enigma using IBM quantum devices and show that the privacy improvements of Enigma come at only a small reduction in fidelity (1%-13%).
Speech-Based Blood Pressure Estimation with Enhanced Optimization and Incremental Clustering
Nov 25, 2023Blood Pressure (BP) estimation plays a pivotal role in diagnosing various health conditions, highlighting the need for innovative approaches to overcome conventional measurement challenges. Leveraging machine learning and speech signals, this study investigates accurate BP estimation with a focus on preprocessing, feature extraction, and real-time applications. An advanced clustering-based strategy, incorporating the k-means algorithm and the proposed Fact-Finding Instructor optimization algorithm, is introduced to enhance accuracy. The combined outcome of these clustering techniques enables robust BP estimation. Moreover, extending beyond these insights, this study delves into the dynamic realm of contemporary digital content consumption. Platforms like YouTube have emerged as influential spaces, presenting an array of videos that evoke diverse emotions. From heartwarming and amusing content to intense narratives, YouTube captures a spectrum of human experiences, influencing information access and emotional engagement. Within this context, this research investigates the interplay between YouTube videos and physiological responses, particularly Blood Pressure (BP) levels. By integrating advanced BP estimation techniques with the emotional dimensions of YouTube videos, this study enriches our understanding of how modern media environments intersect with health implications.
CalibFormer: A Transformer-based Automatic LiDAR-Camera Calibration Network
Nov 26, 2023The fusion of LiDARs and cameras has been increasingly adopted in autonomous driving for perception tasks. The performance of such fusion-based algorithms largely depends on the accuracy of sensor calibration, which is challenging due to the difficulty of identifying common features across different data modalities. Previously, many calibration methods involved specific targets and/or manual intervention, which has proven to be cumbersome and costly. Learning-based online calibration methods have been proposed, but their performance is barely satisfactory in most cases. These methods usually suffer from issues such as sparse feature maps, unreliable cross-modality association, inaccurate calibration parameter regression, etc. In this paper, to address these issues, we propose CalibFormer, an end-to-end network for automatic LiDAR-camera calibration. We aggregate multiple layers of camera and LiDAR image features to achieve high-resolution representations. A multi-head correlation module is utilized to identify correlations between features more accurately. Lastly, we employ transformer architectures to estimate accurate calibration parameters from the correlation information. Our method achieved a mean translation error of $0.8751 \mathrm{cm}$ and a mean rotation error of $0.0562 ^{\circ}$ on the KITTI dataset, surpassing existing state-of-the-art methods and demonstrating strong robustness, accuracy, and generalization capabilities.
Generalized Graph Prompt: Toward a Unification of Pre-Training and Downstream Tasks on Graphs
Nov 26, 2023Graph neural networks have emerged as a powerful tool for graph representation learning, but their performance heavily relies on abundant task-specific supervision. To reduce labeling requirement, the "pre-train, prompt" paradigms have become increasingly common. However, existing study of prompting on graphs is limited, lacking a universal treatment to appeal to different downstream tasks. In this paper, we propose GraphPrompt, a novel pre-training and prompting framework on graphs. GraphPrompt not only unifies pre-training and downstream tasks into a common task template but also employs a learnable prompt to assist a downstream task in locating the most relevant knowledge from the pre-trained model in a task-specific manner. To further enhance GraphPrompt in these two stages, we extend it into GraphPrompt+ with two major enhancements. First, we generalize several popular graph pre-training tasks beyond simple link prediction to broaden the compatibility with our task template. Second, we propose a more generalized prompt design that incorporates a series of prompt vectors within every layer of the pre-trained graph encoder, in order to capitalize on the hierarchical information across different layers beyond just the readout layer. Finally, we conduct extensive experiments on five public datasets to evaluate and analyze GraphPrompt and GraphPrompt+.
HumanRecon: Neural Reconstruction of Dynamic Human Using Geometric Cues and Physical Priors
Nov 26, 2023Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup. Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{https://github.com/PRIS-CV/HumanRecon}{https://github.com/PRIS-CV/HumanRecon}.
Fishnets: Information-Optimal, Scalable Aggregation for Sets and Graphs
Oct 05, 2023Set-based learning is an essential component of modern deep learning and network science. Graph Neural Networks (GNNs) and their edge-free counterparts Deepsets have proven remarkably useful on ragged and topologically challenging datasets. The key to learning informative embeddings for set members is a specified aggregation function, usually a sum, max, or mean. We propose Fishnets, an aggregation strategy for learning information-optimal embeddings for sets of data for both Bayesian inference and graph aggregation. We demonstrate that i) Fishnets neural summaries can be scaled optimally to an arbitrary number of data objects, ii) Fishnets aggregations are robust to changes in data distribution, unlike standard deepsets, iii) Fishnets saturate Bayesian information content and extend to regimes where MCMC techniques fail and iv) Fishnets can be used as a drop-in aggregation scheme within GNNs. We show that by adopting a Fishnets aggregation scheme for message passing, GNNs can achieve state-of-the-art performance versus architecture size on ogbn-protein data over existing benchmarks with a fraction of learnable parameters and faster training time.
Question Answering in Natural Language: the Special Case of Temporal Expressions
Nov 23, 2023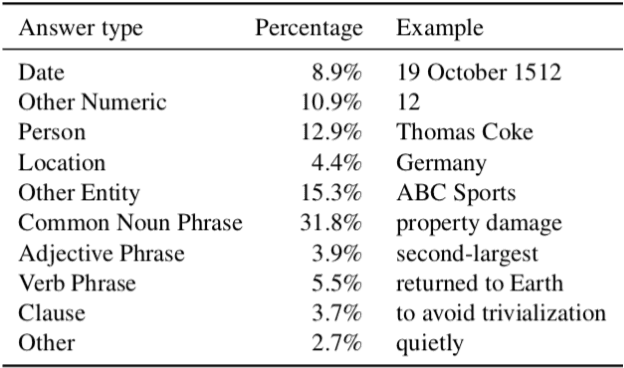
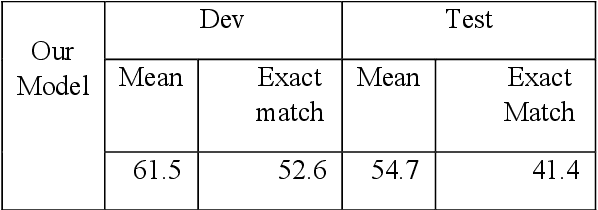
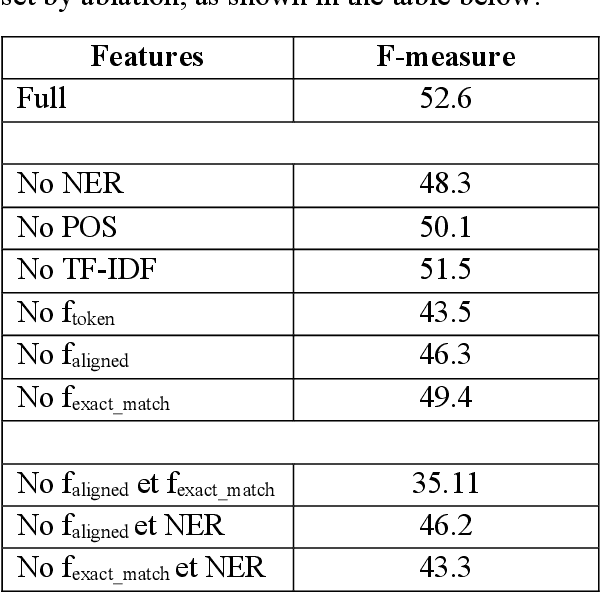
Although general question answering has been well explored in recent years, temporal question answering is a task which has not received as much focus. Our work aims to leverage a popular approach used for general question answering, answer extraction, in order to find answers to temporal questions within a paragraph. To train our model, we propose a new dataset, inspired by SQuAD, specifically tailored to provide rich temporal information. We chose to adapt the corpus WikiWars, which contains several documents on history's greatest conflicts. Our evaluation shows that a deep learning model trained to perform pattern matching, often used in general question answering, can be adapted to temporal question answering, if we accept to ask questions whose answers must be directly present within a text.
A New Approach to Intuitionistic Fuzzy Decision Making Based on Projection Technology and Cosine Similarity Measure
Nov 20, 2023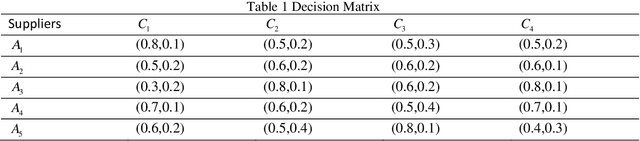
For a multi-attribute decision making (MADM) problem, the information of alternatives under different attributes is given in the form of intuitionistic fuzzy number(IFN). Intuitionistic fuzzy set (IFS) plays an important role in dealing with un-certain and incomplete information. The similarity measure of intuitionistic fuzzy sets (IFSs) has always been a research hotspot. A new similarity measure of IFSs based on the projection technology and cosine similarity measure, which con-siders the direction and length of IFSs at the same time, is first proposed in this paper. The objective of the presented pa-per is to develop a MADM method and medical diagnosis method under IFS using the projection technology and cosine similarity measure. Some examples are used to illustrate the comparison results of the proposed algorithm and some exist-ing methods. The comparison result shows that the proposed algorithm is effective and can identify the optimal scheme accurately. In medical diagnosis area, it can be used to quickly diagnose disease. The proposed method enriches the exist-ing similarity measure methods and it can be applied to not only IFSs, but also other interval-valued intuitionistic fuzzy sets(IVIFSs) as well.