 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BEND: Benchmarking DNA Language Models on biologically meaningful tasks
Nov 25, 2023
The genome sequence contains the blueprint for governing cellular processes. While the availability of genomes has vastly increased over the last decades, experimental annotation of the various functional, non-coding and regulatory elements encoded in the DNA sequence remains both expensive and challenging. This has sparked interest in unsupervised language modeling of genomic DNA, a paradigm that has seen great success for protein sequence data. Although various DNA language models have been proposed, evaluation tasks often differ between individual works, and might not fully recapitulate the fundamental challenges of genome annotation, including the length, scale and sparsity of the data. In this study, we introduce BEND, a Benchmark for DNA language models, featuring a collection of realistic and biologically meaningful downstream tasks defined on the human genome. We find that embeddings from current DNA LMs can approach performance of expert methods on some tasks, but only capture limited information about long-range features. BEND is available at https://github.com/frederikkemarin/BEND.
OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving
Nov 27, 2023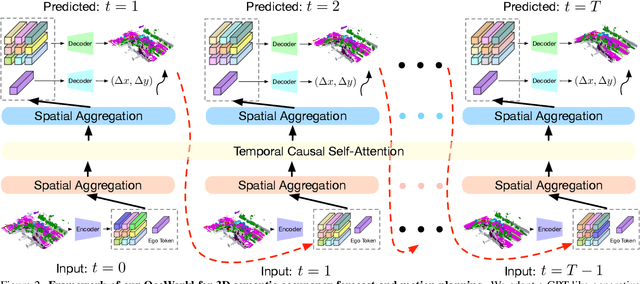
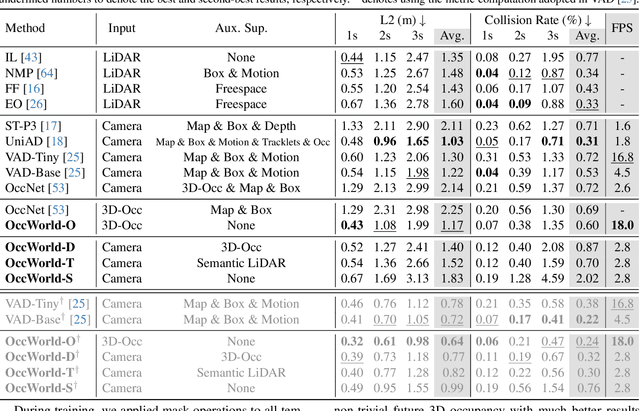
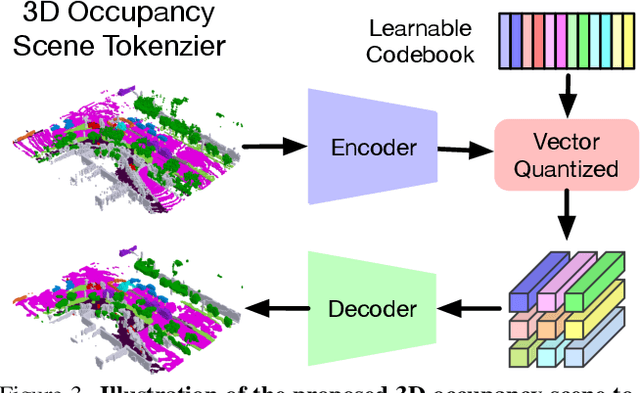
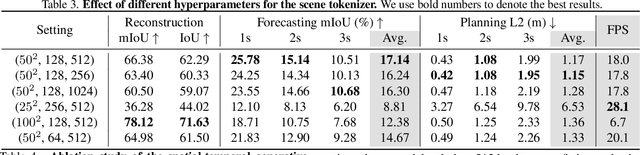
Understanding how the 3D scene evolves is vital for making decisions in autonomous driving. Most existing methods achieve this by predicting the movements of object boxes, which cannot capture more fine-grained scene information. In this paper, we explore a new framework of learning a world model, OccWorld, in the 3D Occupancy space to simultaneously predict the movement of the ego car and the evolution of the surrounding scenes. We propose to learn a world model based on 3D occupancy rather than 3D bounding boxes and segmentation maps for three reasons: 1) expressiveness. 3D occupancy can describe the more fine-grained 3D structure of the scene; 2) efficiency. 3D occupancy is more economical to obtain (e.g., from sparse LiDAR points). 3) versatility. 3D occupancy can adapt to both vision and LiDAR. To facilitate the modeling of the world evolution, we learn a reconstruction-based scene tokenizer on the 3D occupancy to obtain discrete scene tokens to describe the surrounding scenes. We then adopt a GPT-like spatial-temporal generative transformer to generate subsequent scene and ego tokens to decode the future occupancy and ego trajectory. Extensive experiments on the widely used nuScenes benchmark demonstrate the ability of OccWorld to effectively model the evolution of the driving scenes. OccWorld also produces competitive planning results without using instance and map supervision. Code: https://github.com/wzzheng/OccWorld.
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Nov 27, 2023Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
Hierarchical ML Codebook Design for Extreme MIMO Beam Management
Nov 24, 2023Beam management is a strategy to unify beamforming and channel state information (CSI) acquisition with large antenna arrays in 5G. Codebooks serve multiple uses in beam management including beamforming reference signals, CSI reporting, and analog beam training. In this paper, we propose and evaluate a machine learning-refined codebook design process for extremely large multiple-input multiple-output (X-MIMO) systems. We propose a neural network and beam selection strategy to design the initial access and refinement codebooks using end-to-end learning from beamspace representations. The algorithm, called Extreme-Beam Management (X-BM), can significantly improve the performance of extremely large arrays as envisioned for 6G and capture realistic wireless and physical layer aspects. Our results show an 8dB improvement in initial access and overall effective spectral efficiency improvements compared to traditional codebook methods.
Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation
Nov 26, 2023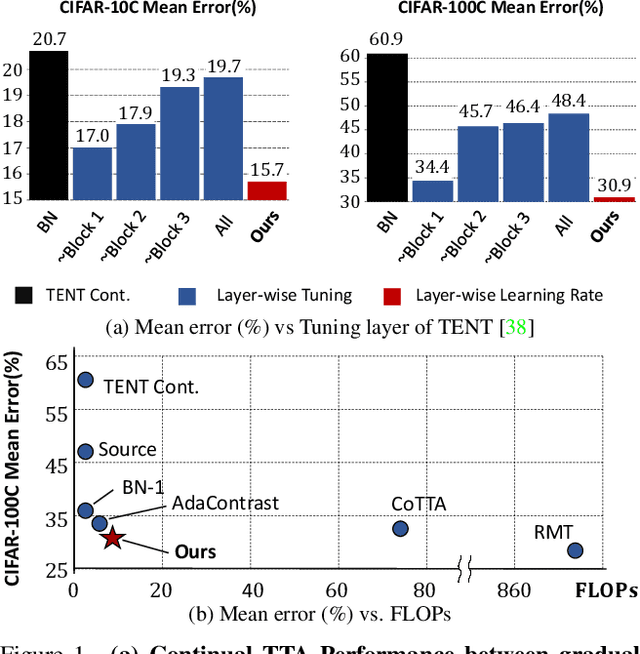

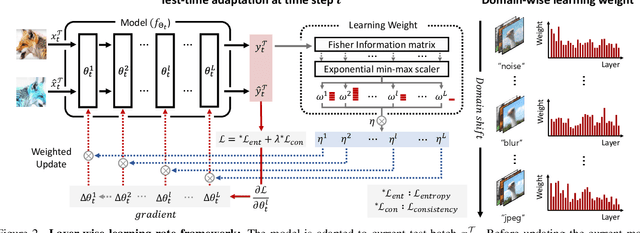
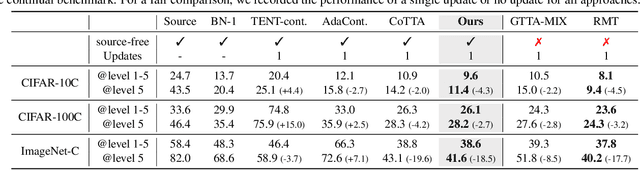
Given the inevitability of domain shifts during inference in real-world applications, test-time adaptation (TTA) is essential for model adaptation after deployment. However, the real-world scenario of continuously changing target distributions presents challenges including catastrophic forgetting and error accumulation. Existing TTA methods for non-stationary domain shifts, while effective, incur excessive computational load, making them impractical for on-device settings. In this paper, we introduce a layer-wise auto-weighting algorithm for continual and gradual TTA that autonomously identifies layers for preservation or concentrated adaptation. By leveraging the Fisher Information Matrix (FIM), we first design the learning weight to selectively focus on layers associated with log-likelihood changes while preserving unrelated ones. Then, we further propose an exponential min-max scaler to make certain layers nearly frozen while mitigating outliers. This minimizes forgetting and error accumulation, leading to efficient adaptation to non-stationary target distribution. Experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C show our method outperforms conventional continual and gradual TTA approaches while significantly reducing computational load, highlighting the importance of FIM-based learning weight in adapting to continuously or gradually shifting target domains.
Low-Complexity Joint Beamforming for RIS-Assisted MU-MISO Systems Based on Model-Driven Deep Learning
Nov 26, 2023Reconfigurable intelligent surfaces (RIS) can improve signal propagation environments by adjusting the phase of the incident signal. However, optimizing the phase shifts jointly with the beamforming vector at the access point is challenging due to the non-convex objective function and constraints. In this study, we propose an algorithm based on weighted minimum mean square error optimization and power iteration to maximize the weighted sum rate (WSR) of a RIS-assisted downlink multi-user multiple-input single-output system. To further improve performance, a model-driven deep learning (DL) approach is designed, where trainable variables and graph neural networks are introduced to accelerate the convergence of the proposed algorithm. We also extend the proposed method to include beamforming with imperfect channel state information and derive a two-timescale stochastic optimization algorithm. Simulation results show that the proposed algorithm outperforms state-of-the-art algorithms in terms of complexity and WSR. Specifically, the model-driven DL approach has a runtime that is approximately 3% of the state-of-the-art algorithm to achieve the same performance. Additionally, the proposed algorithm with 2-bit phase shifters outperforms the compared algorithm with continuous phase shift.
Students' interest in knowledge acquisition in Artificial Intelligence
Nov 26, 2023Some students' expectations and points of view related to the Artificial Intelligence course are explored and analyzed in this study. We anonymous collected answers from 58 undergraduate students out of 200 enrolled in the Computer Science specialization. The answers were analysed and interpreted using thematic analysis to find out their interests and attractive and unattractive aspects related to the Artificial Intelligence study topic. We concluded that students are interested in Artificial Intelligence due to its trendiness, applicability, their passion and interest in the subject, the potential for future growth, and high salaries. However, the students' expectations were mainly related to achieving medium knowledge in the Artificial Intelligence field, and men seem to be more interested in acquiring high-level skills than women. The most common part that wasn't enjoyed by the students was the mathematical aspect used in Artificial Intelligence. Some of them (a small group) were also aware of the Artificial Intelligence potential which could be used in an unethical manner for negative purposes. Our study also provides a short comparison to the Databases course, in which students were not that passionate or interested in achieving medium knowledge, their interest was related to DB usage and basic information.
See and Think: Embodied Agent in Virtual Environment
Nov 26, 2023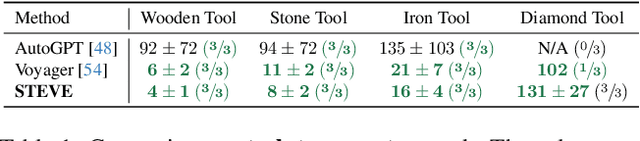
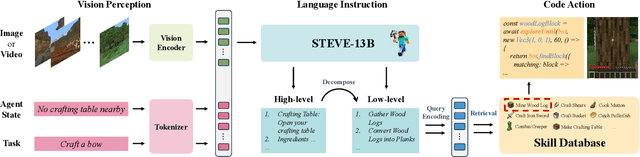
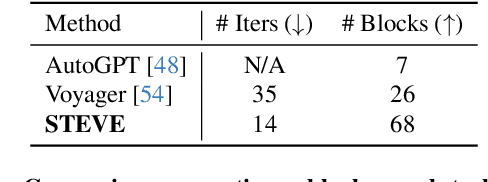
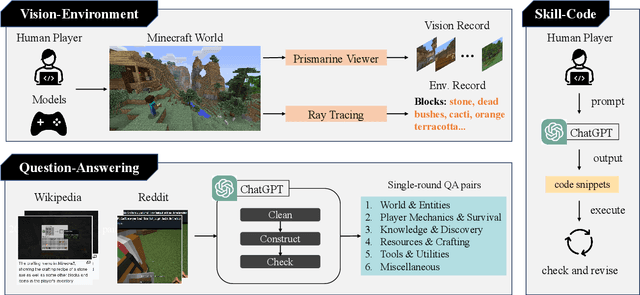
Large language models (LLMs) have achieved impressive progress on several open-world tasks. Recently, using LLMs to build embodied agents has been a hotspot. In this paper, we propose STEVE, a comprehensive and visionary embodied agent in the Minecraft virtual environment. STEVE consists of three key components: vision perception, language instruction, and code action. Vision perception involves the interpretation of visual information in the environment, which is then integrated into the LLMs component with agent state and task instruction. Language instruction is responsible for iterative reasoning and decomposing complex tasks into manageable guidelines. Code action generates executable skill actions based on retrieval in skill database, enabling the agent to interact effectively within the Minecraft environment. We also collect STEVE-21K dataset, which includes 600$+$ vision-environment pairs, 20K knowledge question-answering pairs, and 200$+$ skill-code pairs. We conduct continuous block search, knowledge question and answering, and tech tree mastery to evaluate the performance. Extensive experiments show that STEVE achieves at most $1.5 \times$ faster unlocking key tech trees and $2.5 \times$ quicker in block search tasks compared to previous state-of-the-art methods.
BiHRNet: A Binary high-resolution network for Human Pose Estimation
Nov 17, 2023Human Pose Estimation (HPE) plays a crucial role in computer vision applications. However, it is difficult to deploy state-of-the-art models on resouce-limited devices due to the high computational costs of the networks. In this work, a binary human pose estimator named BiHRNet(Binary HRNet) is proposed, whose weights and activations are expressed as $\pm$1. BiHRNet retains the keypoint extraction ability of HRNet, while using fewer computing resources by adapting binary neural network (BNN). In order to reduce the accuracy drop caused by network binarization, two categories of techniques are proposed in this work. For optimizing the training process for binary pose estimator, we propose a new loss function combining KL divergence loss with AWing loss, which makes the binary network obtain more comprehensive output distribution from its real-valued counterpart to reduce information loss caused by binarization. For designing more binarization-friendly structures, we propose a new information reconstruction bottleneck called IR Bottleneck to retain more information in the initial stage of the network. In addition, we also propose a multi-scale basic block called MS-Block for information retention. Our work has less computation cost with few precision drop. Experimental results demonstrate that BiHRNet achieves a PCKh of 87.9 on the MPII dataset, which outperforms all binary pose estimation networks. On the challenging of COCO dataset, the proposed method enables the binary neural network to achieve 70.8 mAP, which is better than most tested lightweight full-precision networks.
Mastering the Task of Open Information Extraction with Large Language Models and Consistent Reasoning Environment
Oct 16, 2023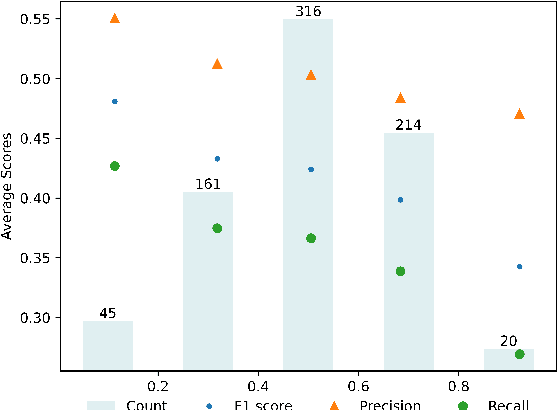
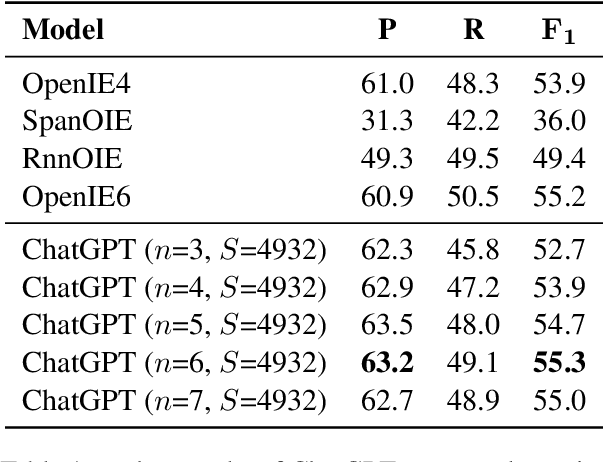
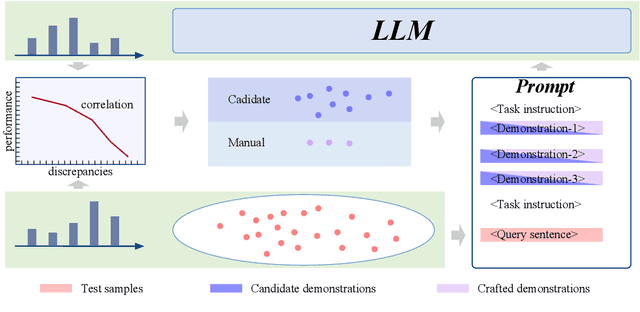

Open Information Extraction (OIE) aims to extract objective structured knowledge from natural texts, which has attracted growing attention to build dedicated models with human experience. As the large language models (LLMs) have exhibited remarkable in-context learning capabilities, a question arises as to whether the task of OIE can be effectively tackled with this paradigm? In this paper, we explore solving the OIE problem by constructing an appropriate reasoning environment for LLMs. Specifically, we first propose a method to effectively estimate the discrepancy of syntactic distribution between a LLM and test samples, which can serve as correlation evidence for preparing positive demonstrations. Upon the evidence, we introduce a simple yet effective mechanism to establish the reasoning environment for LLMs on specific tasks. Without bells and whistles, experimental results on the standard CaRB benchmark demonstrate that our $6$-shot approach outperforms state-of-the-art supervised method, achieving an $55.3$ $F_1$ score. Further experiments on TACRED and ACE05 show that our method can naturally generalize to other information extraction tasks, resulting in improvements of $5.7$ and $6.8$ $F_1$ scores, respectively.