 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evaluating LLMs on Document-Based QA: Exact Answer Selection and Numerical Extraction using Cogtale dataset
Nov 18, 2023
Document-based Question-Answering (QA) tasks are crucial for precise information retrieval. While some existing work focus on evaluating large language model's performance on retrieving and answering questions from documents, assessing the LLMs' performance on QA types that require exact answer selection from predefined options and numerical extraction is yet to be fully assessed. In this paper, we specifically focus on this underexplored context and conduct empirical analysis of LLMs (GPT-4 and GPT 3.5) on question types, including single-choice, yes-no, multiple-choice, and number extraction questions from documents. We use the Cogtale dataset for evaluation, which provide human expert-tagged responses, offering a robust benchmark for precision and factual grounding. We found that LLMs, particularly GPT-4, can precisely answer many single-choice and yes-no questions given relevant context, demonstrating their efficacy in information retrieval tasks. However, their performance diminishes when confronted with multiple-choice and number extraction formats, lowering the overall performance of the model on this task, indicating that these models may not be reliable for the task. This limits the applications of LLMs on applications demanding precise information extraction from documents, such as meta-analysis tasks. However, these findings hinge on the assumption that the retrievers furnish pertinent context necessary for accurate responses, emphasizing the need for further research on the efficacy of retriever mechanisms in enhancing question-answering performance. Our work offers a framework for ongoing dataset evaluation, ensuring that LLM applications for information retrieval and document analysis continue to meet evolving standards.
FinMe: A Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design
Nov 23, 2023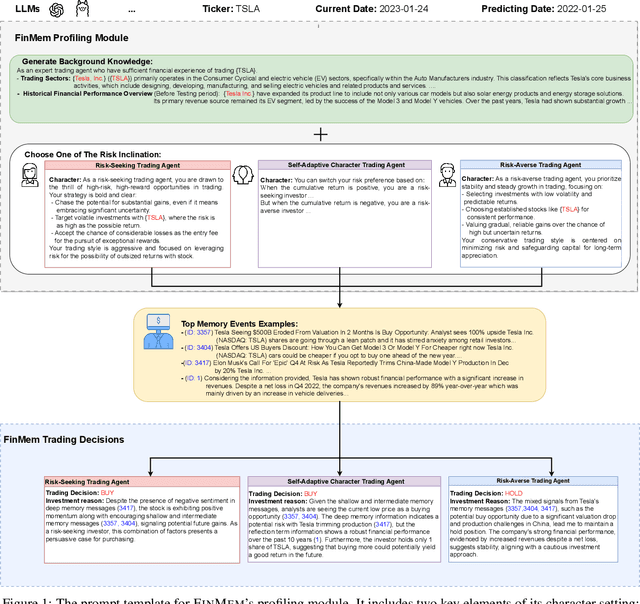
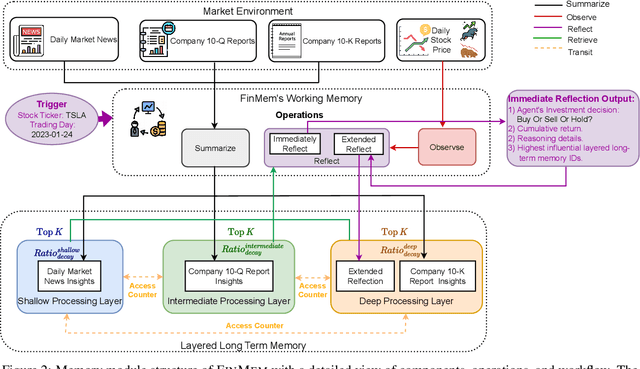
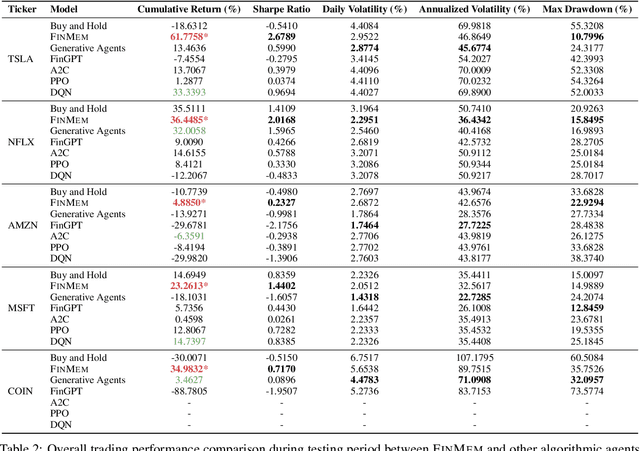

Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMe}, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, to outline the agent's characteristics; Memory, with layered processing, to aid the agent in assimilating realistic hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMe}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMe} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks and funds. We then fine-tuned the agent's perceptual spans to achieve a significant trading performance. Collectively, \textsc{FinMe} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
Fine-grained Appearance Transfer with Diffusion Models
Nov 27, 2023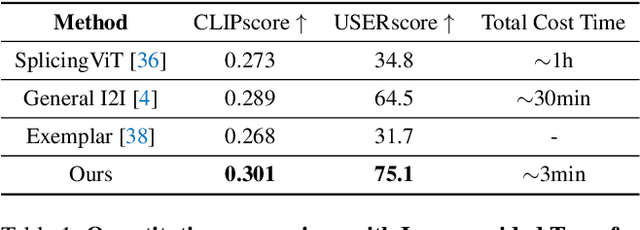

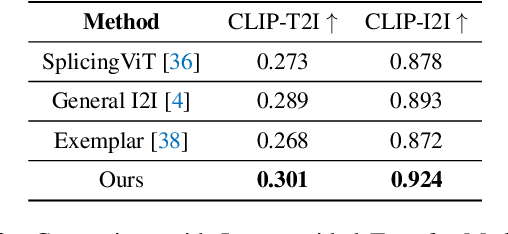
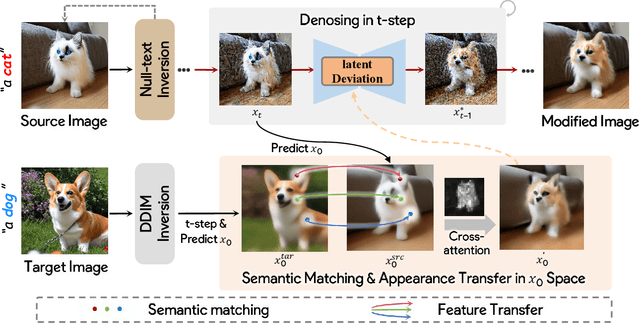
Image-to-image translation (I2I), and particularly its subfield of appearance transfer, which seeks to alter the visual appearance between images while maintaining structural coherence, presents formidable challenges. Despite significant advancements brought by diffusion models, achieving fine-grained transfer remains complex, particularly in terms of retaining detailed structural elements and ensuring information fidelity. This paper proposes an innovative framework designed to surmount these challenges by integrating various aspects of semantic matching, appearance transfer, and latent deviation. A pivotal aspect of our approach is the strategic use of the predicted $x_0$ space by diffusion models within the latent space of diffusion processes. This is identified as a crucial element for the precise and natural transfer of fine-grained details. Our framework exploits this space to accomplish semantic alignment between source and target images, facilitating mask-wise appearance transfer for improved feature acquisition. A significant advancement of our method is the seamless integration of these features into the latent space, enabling more nuanced latent deviations without necessitating extensive model retraining or fine-tuning. The effectiveness of our approach is demonstrated through extensive experiments, which showcase its ability to adeptly handle fine-grained appearance transfers across a wide range of categories and domains. We provide our code at https://github.com/babahui/Fine-grained-Appearance-Transfer
Optimization of Image Processing Algorithms for Character Recognition in Cultural Typewritten Documents
Nov 27, 2023Linked Data is used in various fields as a new way of structuring and connecting data. Cultural heritage institutions have been using linked data to improve archival descriptions and facilitate the discovery of information. Most archival records have digital representations of physical artifacts in the form of scanned images that are non-machine-readable. Optical Character Recognition (OCR) recognizes text in images and translates it into machine-encoded text. This paper evaluates the impact of image processing methods and parameter tuning in OCR applied to typewritten cultural heritage documents. The approach uses a multi-objective problem formulation to minimize Levenshtein edit distance and maximize the number of words correctly identified with a non-dominated sorting genetic algorithm (NSGA-II) to tune the methods' parameters. Evaluation results show that parameterization by digital representation typology benefits the performance of image pre-processing algorithms in OCR. Furthermore, our findings suggest that employing image pre-processing algorithms in OCR might be more suitable for typologies where the text recognition task without pre-processing does not produce good results. In particular, Adaptive Thresholding, Bilateral Filter, and Opening are the best-performing algorithms for the theatre plays' covers, letters, and overall dataset, respectively, and should be applied before OCR to improve its performance.
* 25 pages, 4 figures
Source-Free Domain Adaptation with Frozen Multimodal Foundation Model
Nov 27, 2023Source-Free Domain Adaptation (SFDA) aims to adapt a source model for a target domain, with only access to unlabeled target training data and the source model pre-trained on a supervised source domain. Relying on pseudo labeling and/or auxiliary supervision, conventional methods are inevitably error-prone. To mitigate this limitation, in this work we for the first time explore the potentials of off-the-shelf vision-language (ViL) multimodal models (e.g.,CLIP) with rich whilst heterogeneous knowledge. We find that directly applying the ViL model to the target domain in a zero-shot fashion is unsatisfactory, as it is not specialized for this particular task but largely generic. To make it task specific, we propose a novel Distilling multimodal Foundation model(DIFO)approach. Specifically, DIFO alternates between two steps during adaptation: (i) Customizing the ViL model by maximizing the mutual information with the target model in a prompt learning manner, (ii) Distilling the knowledge of this customized ViL model to the target model. For more fine-grained and reliable distillation, we further introduce two effective regularization terms, namely most-likely category encouragement and predictive consistency. Extensive experiments show that DIFO significantly outperforms the state-of-the-art alternatives. Our source code will be released.
Leveraging Out-of-Domain Data for Domain-Specific Prompt Tuning in Multi-Modal Fake News Detection
Nov 27, 2023The spread of fake news using out-of-context images has become widespread and is a challenging task in this era of information overload. Since annotating huge amounts of such data requires significant time of domain experts, it is imperative to develop methods which can work in limited annotated data scenarios. In this work, we explore whether out-of-domain data can help to improve out-of-context misinformation detection (termed here as multi-modal fake news detection) of a desired domain, eg. politics, healthcare, etc. Towards this goal, we propose a novel framework termed DPOD (Domain-specific Prompt-tuning using Out-of-Domain data). First, to compute generalizable features, we modify the Vision-Language Model, CLIP to extract features that helps to align the representations of the images and corresponding text captions of both the in-domain and out-of-domain data in a label-aware manner. Further, we propose a domain-specific prompt learning technique which leverages the training samples of all the available domains based on the the extent they can be useful to the desired domain. Extensive experiments on a large-scale benchmark dataset, namely NewsClippings demonstrate that the proposed framework achieves state of-the-art performance, significantly surpassing the existing approaches for this challenging task.
Spatially Covariant Image Registration with Text Prompts
Nov 27, 2023
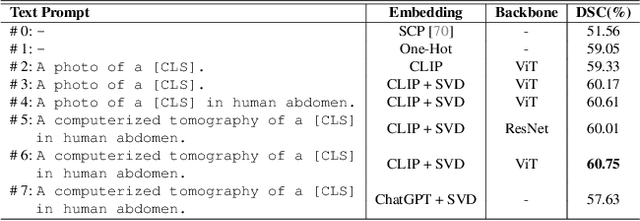
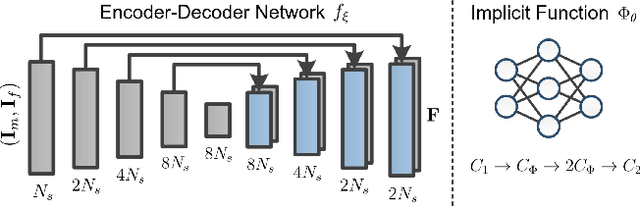
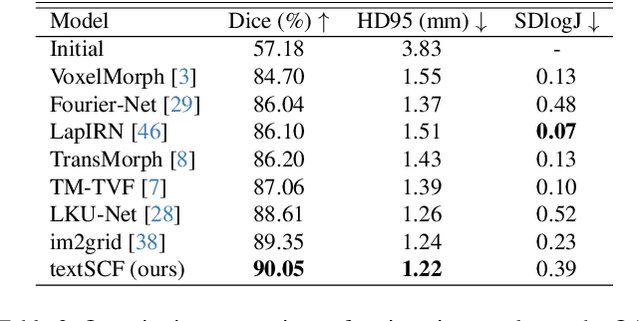
Medical images are often characterized by their structured anatomical representations and spatially inhomogeneous contrasts. Leveraging anatomical priors in neural networks can greatly enhance their utility in resource-constrained clinical settings. Prior research has harnessed such information for image segmentation, yet progress in deformable image registration has been modest. Our work introduces textSCF, a novel method that integrates spatially covariant filters and textual anatomical prompts encoded by visual-language models, to fill this gap. This approach optimizes an implicit function that correlates text embeddings of anatomical regions to filter weights, relaxing the typical translation-invariance constraint of convolutional operations. TextSCF not only boosts computational efficiency but can also retain or improve registration accuracy. By capturing the contextual interplay between anatomical regions, it offers impressive inter-regional transferability and the ability to preserve structural discontinuities during registration. TextSCF's performance has been rigorously tested on inter-subject brain MRI and abdominal CT registration tasks, outperforming existing state-of-the-art models in the MICCAI Learn2Reg 2021 challenge and leading the leaderboard. In abdominal registrations, textSCF's larger model variant improved the Dice score by 11.3% over the second-best model, while its smaller variant maintained similar accuracy but with an 89.13% reduction in network parameters and a 98.34\% decrease in computational operations.
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
Can Vision-Language Models Think from a First-Person Perspective?
Nov 27, 2023Vision-language models (VLMs) have recently shown promising results in traditional downstream tasks. Evaluation studies have emerged to assess their abilities, with the majority focusing on the third-person perspective, and only a few addressing specific tasks from the first-person perspective. However, the capability of VLMs to "think" from a first-person perspective, a crucial attribute for advancing autonomous agents and robotics, remains largely unexplored. To bridge this research gap, we introduce EgoThink, a novel visual question-answering benchmark that encompasses six core capabilities with twelve detailed dimensions. The benchmark is constructed using selected clips from egocentric videos, with manually annotated question-answer pairs containing first-person information. To comprehensively assess VLMs, we evaluate eighteen popular VLMs on EgoThink. Moreover, given the open-ended format of the answers, we use GPT-4 as the automatic judge to compute single-answer grading. Experimental results indicate that although GPT-4V leads in numerous dimensions, all evaluated VLMs still possess considerable potential for improvement in first-person perspective tasks. Meanwhile, enlarging the number of trainable parameters has the most significant impact on model performance on EgoThink. In conclusion, EgoThink serves as a valuable addition to existing evaluation benchmarks for VLMs, providing an indispensable resource for future research in the realm of embodied artificial intelligence and robotics.
UFDA: Universal Federated Domain Adaptation with Practical Assumptions
Nov 27, 2023Conventional Federated Domain Adaptation (FDA) approaches usually demand an abundance of assumptions, such as label set consistency, which makes them significantly less feasible for real-world situations and introduces security hazards. In this work, we propose a more practical scenario named Universal Federated Domain Adaptation (UFDA). It only requires the black-box model and the label set information of each source domain, while the label sets of different source domains could be inconsistent and the target-domain label set is totally blind. This relaxes the assumptions made by FDA, which are often challenging to meet in real-world cases and diminish model security. To address the UFDA scenario, we propose a corresponding framework called Hot-Learning with Contrastive Label Disambiguation (HCLD), which tackles UFDA's domain shifts and category gaps problem by using one-hot outputs from the black-box models of various source domains. Moreover, to better distinguish the shared and unknown classes, we further present a cluster-level strategy named Mutual-Voting Decision (MVD) to extract robust consensus knowledge across peer classes from both source and target domains. The extensive experiments on three benchmarks demonstrate that our HCLD achieves comparable performance for our UFDA scenario with much fewer assumptions, compared to the previous methodologies with many additional assumptions.