 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Networked Multiagent Safe Reinforcement Learning for Low-carbon Demand Management in Distribution Network
Nov 27, 2023
This paper proposes a multiagent based bi-level operation framework for the low-carbon demand management in distribution networks considering the carbon emission allowance on the demand side. In the upper level, the aggregate load agents optimize the control signals for various types of loads to maximize the profits; in the lower level, the distribution network operator makes optimal dispatching decisions to minimize the operational costs and calculates the distribution locational marginal price and carbon intensity. The distributed flexible load agent has only incomplete information of the distribution network and cooperates with other agents using networked communication. Finally, the problem is formulated into a networked multi-agent constrained Markov decision process, which is solved using a safe reinforcement learning algorithm called consensus multi-agent constrained policy optimization considering the carbon emission allowance for each agent. Case studies with the IEEE 33-bus and 123-bus distribution network systems demonstrate the effectiveness of the proposed approach, in terms of satisfying the carbon emission constraint on demand side, ensuring the safe operation of the distribution network and preserving privacy of both sides.
Characterizing Video Question Answering with Sparsified Inputs
Nov 27, 2023In Video Question Answering, videos are often processed as a full-length sequence of frames to ensure minimal loss of information. Recent works have demonstrated evidence that sparse video inputs are sufficient to maintain high performance. However, they usually discuss the case of single frame selection. In our work, we extend the setting to multiple number of inputs and other modalities. We characterize the task with different input sparsity and provide a tool for doing that. Specifically, we use a Gumbel-based learnable selection module to adaptively select the best inputs for the final task. In this way, we experiment over public VideoQA benchmarks and provide analysis on how sparsified inputs affect the performance. From our experiments, we have observed only 5.2%-5.8% loss of performance with only 10% of video lengths, which corresponds to 2-4 frames selected from each video. Meanwhile, we also observed the complimentary behaviour between visual and textual inputs, even under highly sparsified settings, suggesting the potential of improving data efficiency for video-and-language tasks.
How Many Unicorns Are in This Image? A Safety Evaluation Benchmark for Vision LLMs
Nov 27, 2023This work focuses on the potential of Vision LLMs (VLLMs) in visual reasoning. Different from prior studies, we shift our focus from evaluating standard performance to introducing a comprehensive safety evaluation suite, covering both out-of-distribution (OOD) generalization and adversarial robustness. For the OOD evaluation, we present two novel VQA datasets, each with one variant, designed to test model performance under challenging conditions. In exploring adversarial robustness, we propose a straightforward attack strategy for misleading VLLMs to produce visual-unrelated responses. Moreover, we assess the efficacy of two jailbreaking strategies, targeting either the vision or language component of VLLMs. Our evaluation of 21 diverse models, ranging from open-source VLLMs to GPT-4V, yields interesting observations: 1) Current VLLMs struggle with OOD texts but not images, unless the visual information is limited; and 2) These VLLMs can be easily misled by deceiving vision encoders only, and their vision-language training often compromise safety protocols. We release this safety evaluation suite at https://github.com/UCSC-VLAA/vllm-safety-benchmark.
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
Nov 28, 2023Geographic location is essential for modeling tasks in fields ranging from ecology to epidemiology to the Earth system sciences. However, extracting relevant and meaningful characteristics of a location can be challenging, often entailing expensive data fusion or data distillation from global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP), a global, general-purpose geographic location encoder that learns an implicit representation of locations from openly available satellite imagery. Trained location encoders provide vector embeddings summarizing the characteristics of any given location for convenient usage in diverse downstream tasks. We show that SatCLIP embeddings, pretrained on globally sampled multi-spectral Sentinel-2 satellite data, can be used in various predictive tasks that depend on location information but not necessarily satellite imagery, including temperature prediction, animal recognition in imagery, and population density estimation. Across tasks, SatCLIP embeddings consistently outperform embeddings from existing pretrained location encoders, ranging from models trained on natural images to models trained on semantic context. SatCLIP embeddings also help to improve geographic generalization. This demonstrates the potential of general-purpose location encoders and opens the door to learning meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Nov 28, 2023In the realm of large multi-modal models (LMMs), efficient modality alignment is crucial yet often constrained by the scarcity of high-quality image-text data. To address this bottleneck, we introduce the ShareGPT4V dataset, a pioneering large-scale resource featuring 1.2 million highly descriptive captions, which surpasses existing datasets in diversity and information content, covering world knowledge, object properties, spatial relationships, and aesthetic evaluations. Specifically, ShareGPT4V originates from a curated 100K high-quality captions collected from advanced GPT4-Vision and has been expanded to 1.2M with a superb caption model trained on this subset. ShareGPT4V first demonstrates its effectiveness for the Supervised Fine-Tuning (SFT) phase, by substituting an equivalent quantity of detailed captions in existing SFT datasets with a subset of our high-quality captions, significantly enhancing the LMMs like LLaVA-7B, LLaVA-1.5-13B, and Qwen-VL-Chat-7B on the MME and MMBench benchmarks, with respective gains of 222.8/22.0/22.3 and 2.7/1.3/1.5. We further incorporate ShareGPT4V data into both the pre-training and SFT phases, obtaining ShareGPT4V-7B, a superior LMM based on a simple architecture that has remarkable performance across a majority of the multi-modal benchmarks. This project is available at https://ShareGPT4V.github.io to serve as a pivotal resource for advancing the LMMs community.
Edge AI for Internet of Energy: Challenges and Perspectives
Nov 28, 2023The digital landscape of the Internet of Energy (IoE) is on the brink of a revolutionary transformation with the integration of edge Artificial Intelligence (AI). This comprehensive review elucidates the promise and potential that edge AI holds for reshaping the IoE ecosystem. Commencing with a meticulously curated research methodology, the article delves into the myriad of edge AI techniques specifically tailored for IoE. The myriad benefits, spanning from reduced latency and real-time analytics to the pivotal aspects of information security, scalability, and cost-efficiency, underscore the indispensability of edge AI in modern IoE frameworks. As the narrative progresses, readers are acquainted with pragmatic applications and techniques, highlighting on-device computation, secure private inference methods, and the avant-garde paradigms of AI training on the edge. A critical analysis follows, offering a deep dive into the present challenges including security concerns, computational hurdles, and standardization issues. However, as the horizon of technology ever expands, the review culminates in a forward-looking perspective, envisaging the future symbiosis of 5G networks, federated edge AI, deep reinforcement learning, and more, painting a vibrant panorama of what the future beholds. For anyone vested in the domains of IoE and AI, this review offers both a foundation and a visionary lens, bridging the present realities with future possibilities.
Cross-level Attention with Overlapped Windows for Camouflaged Object Detection
Nov 28, 2023Camouflaged objects adaptively fit their color and texture with the environment, which makes them indistinguishable from the surroundings. Current methods revealed that high-level semantic features can highlight the differences between camouflaged objects and the backgrounds. Consequently, they integrate high-level semantic features with low-level detailed features for accurate camouflaged object detection (COD). Unlike previous designs for multi-level feature fusion, we state that enhancing low-level features is more impending for COD. In this paper, we propose an overlapped window cross-level attention (OWinCA) to achieve the low-level feature enhancement guided by the highest-level features. By sliding an aligned window pair on both the highest- and low-level feature maps, the high-level semantics are explicitly integrated into the low-level details via cross-level attention. Additionally, it employs an overlapped window partition strategy to alleviate the incoherence among windows, which prevents the loss of global information. These adoptions enable the proposed OWinCA to enhance low-level features by promoting the separability of camouflaged objects. The associated proposed OWinCANet fuses these enhanced multi-level features by simple convolution operation to achieve the final COD. Experiments conducted on three large-scale COD datasets demonstrate that our OWinCANet significantly surpasses the current state-of-the-art COD methods.
Clean Label Disentangling for Medical Image Segmentation with Noisy Labels
Nov 28, 2023Current methods focusing on medical image segmentation suffer from incorrect annotations, which is known as the noisy label issue. Most medical image segmentation with noisy labels methods utilize either noise transition matrix, noise-robust loss functions or pseudo-labeling methods, while none of the current research focuses on clean label disentanglement. We argue that the main reason is that the severe class-imbalanced issue will lead to the inaccuracy of the selected ``clean'' labels, thus influencing the robustness of the model against the noises. In this work, we come up with a simple but efficient class-balanced sampling strategy to tackle the class-imbalanced problem, which enables our newly proposed clean label disentangling framework to successfully select clean labels from the given label sets and encourages the model to learn from the correct annotations. However, such a method will filter out too many annotations which may also contain useful information. Therefore, we further extend our clean label disentangling framework to a new noisy feature-aided clean label disentangling framework, which takes the full annotations into utilization to learn more semantics. Extensive experiments have validated the effectiveness of our methods, where our methods achieve new state-of-the-art performance. Our code is available at https://github.com/xiaoyao3302/2BDenoise.
I-MedSAM: Implicit Medical Image Segmentation with Segment Anything
Nov 28, 2023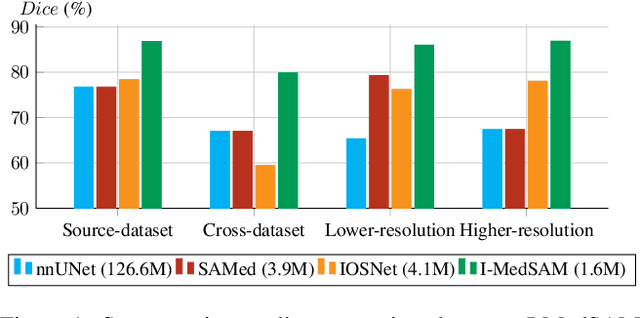
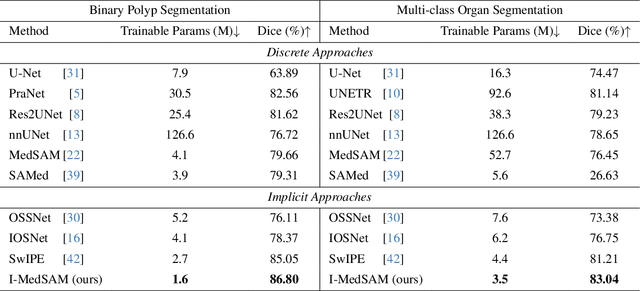
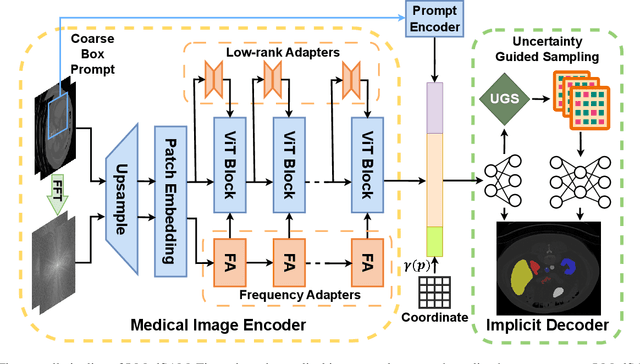
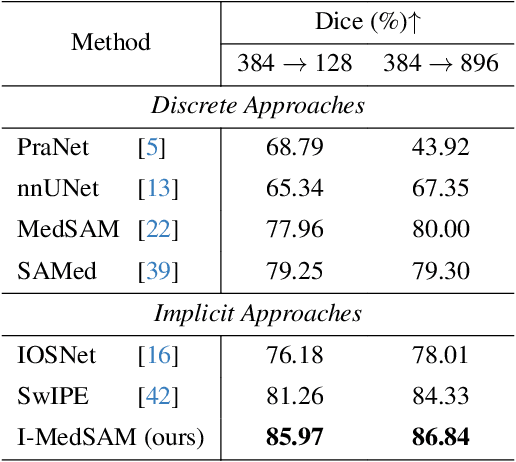
With the development of Deep Neural Networks (DNNs), many efforts have been made to handle medical image segmentation. Traditional methods such as nnUNet train specific segmentation models on the individual datasets. Plenty of recent methods have been proposed to adapt the foundational Segment Anything Model (SAM) to medical image segmentation. However, they still focus on discrete representations to generate pixel-wise predictions, which are spatially inflexible and scale poorly to higher resolution. In contrast, implicit methods learn continuous representations for segmentation, which is crucial for medical image segmentation. In this paper, we propose I-MedSAM, which leverages the benefits of both continuous representations and SAM, to obtain better cross-domain ability and accurate boundary delineation. Since medical image segmentation needs to predict detailed segmentation boundaries, we designed a novel adapter to enhance the SAM features with high-frequency information during Parameter Efficient Fine Tuning (PEFT). To convert the SAM features and coordinates into continuous segmentation output, we utilize Implicit Neural Representation (INR) to learn an implicit segmentation decoder. We also propose an uncertainty-guided sampling strategy for efficient learning of INR. Extensive evaluations on 2D medical image segmentation tasks have shown that our proposed method with only 1.6M trainable parameters outperforms existing methods including discrete and continuous methods. The code will be released.
Improving Image Captioning via Predicting Structured Concepts
Nov 28, 2023Having the difficulty of solving the semantic gap between images and texts for the image captioning task, conventional studies in this area paid some attention to treating semantic concepts as a bridge between the two modalities and improved captioning performance accordingly. Although promising results on concept prediction were obtained, the aforementioned studies normally ignore the relationship among concepts, which relies on not only objects in the image, but also word dependencies in the text, so that offers a considerable potential for improving the process of generating good descriptions. In this paper, we propose a structured concept predictor (SCP) to predict concepts and their structures, then we integrate them into captioning, so as to enhance the contribution of visual signals in this task via concepts and further use their relations to distinguish cross-modal semantics for better description generation. Particularly, we design weighted graph convolutional networks (W-GCN) to depict concept relations driven by word dependencies, and then learns differentiated contributions from these concepts for following decoding process. Therefore, our approach captures potential relations among concepts and discriminatively learns different concepts, so that effectively facilitates image captioning with inherited information across modalities. Extensive experiments and their results demonstrate the effectiveness of our approach as well as each proposed module in this work.