 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Benchmarking Large Language Model Volatility
Nov 26, 2023
The impact of non-deterministic outputs from Large Language Models (LLMs) is not well examined for financial text understanding tasks. Through a compelling case study on investing in the US equity market via news sentiment analysis, we uncover substantial variability in sentence-level sentiment classification results, underscoring the innate volatility of LLM outputs. These uncertainties cascade downstream, leading to more significant variations in portfolio construction and return. While tweaking the temperature parameter in the language model decoder presents a potential remedy, it comes at the expense of stifled creativity. Similarly, while ensembling multiple outputs mitigates the effect of volatile outputs, it demands a notable computational investment. This work furnishes practitioners with invaluable insights for adeptly navigating uncertainty in the integration of LLMs into financial decision-making, particularly in scenarios dictated by non-deterministic information.
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
Nov 28, 2023Lifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is https://lingtengqiu.github.io/RichDreamer/.
RankingGPT: Empowering Large Language Models in Text Ranking with Progressive Enhancement
Nov 28, 2023Text ranking is a critical task in various information retrieval applications, and the recent success of Large Language Models (LLMs) in natural language processing has sparked interest in their application to text ranking. These methods primarily involve combining query and candidate documents and leveraging prompt learning to determine query-document relevance using the LLM's output probabilities for specific tokens or by directly generating a ranked list of candidate documents. Although these approaches have demonstrated promise, a noteworthy disparity arises between the training objective of LLMs, which typically centers around next token prediction, and the objective of evaluating query-document relevance. To address this gap and fully leverage LLM potential in text ranking tasks, we propose a progressive multi-stage training strategy. Firstly, we introduce a large-scale weakly supervised dataset of relevance texts to enable the LLMs to acquire the ability to predict relevant tokens without altering their original training objective. Subsequently, we incorporate supervised training to further enhance LLM ranking capability. Our experimental results on multiple benchmarks demonstrate the superior performance of our proposed method compared to previous competitive approaches, both in in-domain and out-of-domain scenarios.
Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular, Stereo, and RGB-D Cameras
Nov 28, 2023The integration of neural rendering and the SLAM system recently showed promising results in joint localization and photorealistic view reconstruction. However, existing methods, fully relying on implicit representations, are so resource-hungry that they cannot run on portable devices, which deviates from the original intention of SLAM. In this paper, we present Photo-SLAM, a novel SLAM framework with a hyper primitives map. Specifically, we simultaneously exploit explicit geometric features for localization and learn implicit photometric features to represent the texture information of the observed environment. In addition to actively densifying hyper primitives based on geometric features, we further introduce a Gaussian-Pyramid-based training method to progressively learn multi-level features, enhancing photorealistic mapping performance. The extensive experiments with monocular, stereo, and RGB-D datasets prove that our proposed system Photo-SLAM significantly outperforms current state-of-the-art SLAM systems for online photorealistic mapping, e.g., PSNR is 30% higher and rendering speed is hundreds of times faster in the Replica dataset. Moreover, the Photo-SLAM can run at real-time speed using an embedded platform such as Jetson AGX Orin, showing the potential of robotics applications.
A Distribution-Based Threshold for Determining Sentence Similarity
Nov 28, 2023We hereby present a solution to a semantic textual similarity (STS) problem in which it is necessary to match two sentences containing, as the only distinguishing factor, highly specific information (such as names, addresses, identification codes), and from which we need to derive a definition for when they are similar and when they are not. The solution revolves around the use of a neural network, based on the siamese architecture, to create the distributions of the distances between similar and dissimilar pairs of sentences. The goal of these distributions is to find a discriminating factor, that we call "threshold", which represents a well-defined quantity that can be used to distinguish vector distances of similar pairs from vector distances of dissimilar pairs in new predictions and later analyses. In addition, we developed a way to score the predictions by combining attributes from both the distributions' features and the way the distance function works. Finally, we generalize the results showing that they can be transferred to a wider range of domains by applying the system discussed to a well-known and widely used benchmark dataset for STS problems.
Pseudo-Likelihood Inference
Nov 28, 2023Simulation-Based Inference (SBI) is a common name for an emerging family of approaches that infer the model parameters when the likelihood is intractable. Existing SBI methods either approximate the likelihood, such as Approximate Bayesian Computation (ABC) or directly model the posterior, such as Sequential Neural Posterior Estimation (SNPE). While ABC is efficient on low-dimensional problems, on higher-dimensional tasks, it is generally outperformed by SNPE, which leverages function approximation. In this paper, we propose Pseudo-Likelihood Inference (PLI), a new method that brings neural approximation into ABC, making it competitive on challenging Bayesian system identification tasks. By utilizing integral probability metrics, we introduce a smooth likelihood kernel with an adaptive bandwidth that is updated based on information-theoretic trust regions. Thanks to this formulation, our method (i) allows for optimizing neural posteriors via gradient descent, (ii) does not rely on summary statistics, and (iii) enables multiple observations as input. In comparison to SNPE, it leads to improved performance when more data is available. The effectiveness of PLI is evaluated on four classical SBI benchmark tasks and on a highly dynamic physical system, showing particular advantages on stochastic simulations and multi-modal posterior landscapes.
MotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation
Nov 28, 2023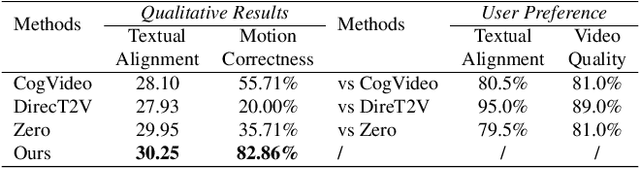
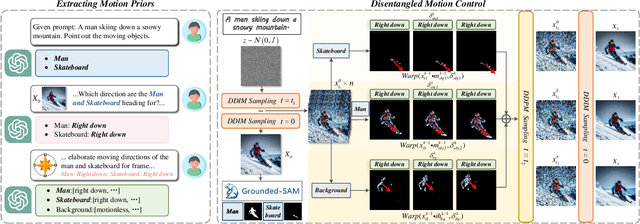
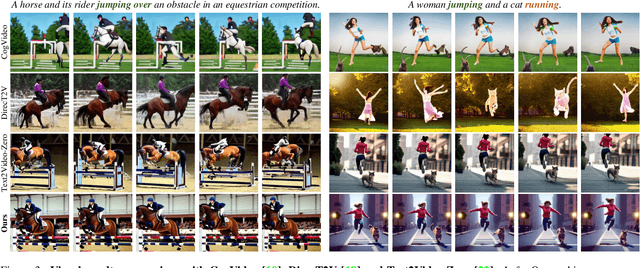

Zero-shot Text-to-Video synthesis generates videos based on prompts without any videos. Without motion information from videos, motion priors implied in prompts are vital guidance. For example, the prompt "airplane landing on the runway" indicates motion priors that the "airplane" moves downwards while the "runway" stays static. Whereas the motion priors are not fully exploited in previous approaches, thus leading to two nontrivial issues: 1) the motion variation pattern remains unaltered and prompt-agnostic for disregarding motion priors; 2) the motion control of different objects is inaccurate and entangled without considering the independent motion priors of different objects. To tackle the two issues, we propose a prompt-adaptive and disentangled motion control strategy coined as MotionZero, which derives motion priors from prompts of different objects by Large-Language-Models and accordingly applies motion control of different objects to corresponding regions in disentanglement. Furthermore, to facilitate videos with varying degrees of motion amplitude, we propose a Motion-Aware Attention scheme which adjusts attention among frames by motion amplitude. Extensive experiments demonstrate that our strategy could correctly control motion of different objects and support versatile applications including zero-shot video edit.
Visual Semantic Navigation with Real Robots
Nov 28, 2023Visual Semantic Navigation (VSN) is the ability of a robot to learn visual semantic information for navigating in unseen environments. These VSN models are typically tested in those virtual environments where they are trained, mainly using reinforcement learning based approaches. Therefore, we do not yet have an in-depth analysis of how these models would behave in the real world. In this work, we propose a new solution to integrate VSN models into real robots, so that we have true embodied agents. We also release a novel ROS-based framework for VSN, ROS4VSN, so that any VSN-model can be easily deployed in any ROS-compatible robot and tested in a real setting. Our experiments with two different robots, where we have embedded two state-of-the-art VSN agents, confirm that there is a noticeable performance difference of these VSN solutions when tested in real-world and simulation environments. We hope that this research will endeavor to provide a foundation for addressing this consequential issue, with the ultimate aim of advancing the performance and efficiency of embodied agents within authentic real-world scenarios. Code to reproduce all our experiments can be found at https://github.com/gramuah/ros4vsn.
Progressive Learning with Visual Prompt Tuning for Variable-Rate Image Compression
Nov 28, 2023In this paper, we propose a progressive learning paradigm for transformer-based variable-rate image compression. Our approach covers a wide range of compression rates with the assistance of the Layer-adaptive Prompt Module (LPM). Inspired by visual prompt tuning, we use LPM to extract prompts for input images and hidden features at the encoder side and decoder side, respectively, which are fed as additional information into the Swin Transformer layer of a pre-trained transformer-based image compression model to affect the allocation of attention region and the bits, which in turn changes the target compression ratio of the model. To ensure the network is more lightweight, we involves the integration of prompt networks with less convolutional layers. Exhaustive experiments show that compared to methods based on multiple models, which are optimized separately for different target rates, the proposed method arrives at the same performance with 80% savings in parameter storage and 90% savings in datasets. Meanwhile, our model outperforms all current variable bitrate image methods in terms of rate-distortion performance and approaches the state-of-the-art fixed bitrate image compression methods trained from scratch.
Guideline Learning for In-context Information Extraction
Oct 08, 2023
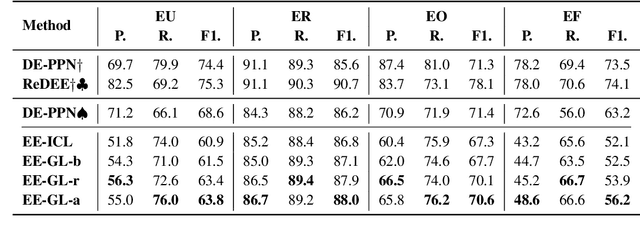
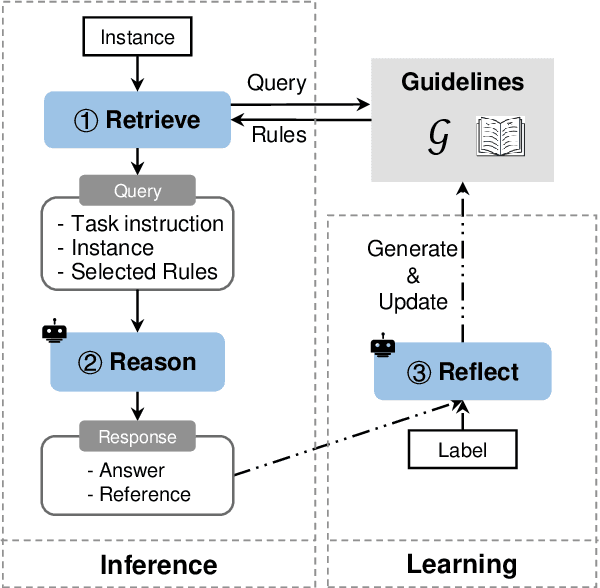
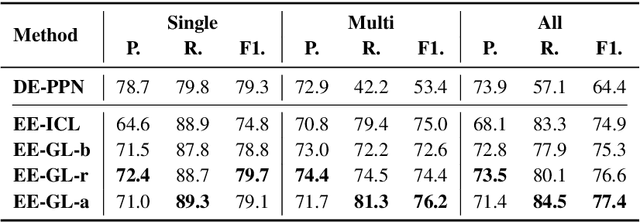
Large language models (LLMs) can perform a new task by merely conditioning on task instructions and a few input-output examples, without optimizing any parameters. This is called In-Context Learning (ICL). In-context Information Extraction has recently garnered attention in the research community. However, current experiment results are generally suboptimal. We attribute this primarily to the fact that the complex task settings and a variety of edge cases are hard to be fully expressed in the length-limited context. In this paper, we propose a Guideline Learning (GL) framework for In-context IE which learns to generate and follow guidelines. During the learning phrase, GL automatically synthesizes a set of guidelines from a few annotations, and during inference, helpful guidelines are retrieved for better ICL.