 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text Attribute Control via Closed-Loop Disentanglement
Dec 01, 2023
Changing an attribute of a text without changing the content usually requires to first disentangle the text into irrelevant attributes and content representations. After that, in the inference phase, the representation of one attribute is tuned to a different value, expecting that the corresponding attribute of the text can also be changed accordingly. The usual way of disentanglement is to add some constraints on the latent space of an encoder-decoder architecture, including adversarial-based constraints and mutual-information-based constraints. However, the previous semi-supervised processes of attribute change are usually not enough to guarantee the success of attribute change and content preservation. In this paper, we propose a novel approach to achieve a robust control of attributes while enhancing content preservation. In this approach, we use a semi-supervised contrastive learning method to encourage the disentanglement of attributes in latent spaces. Differently from previous works, we re-disentangle the reconstructed sentence and compare the re-disentangled latent space with the original latent space, which makes a closed-loop disentanglement process. This also helps content preservation. In addition, the contrastive learning method is also able to replace the role of minimizing mutual information and adversarial training in the disentanglement process, which alleviates the computation cost. We conducted experiments on three text datasets, including the Yelp Service review dataset, the Amazon Product review dataset, and the GoEmotions dataset. The experimental results show the effectiveness of our model.
Feedback RoI Features Improve Aerial Object Detection
Nov 28, 2023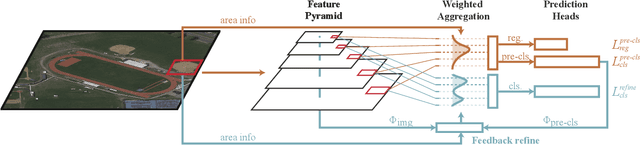
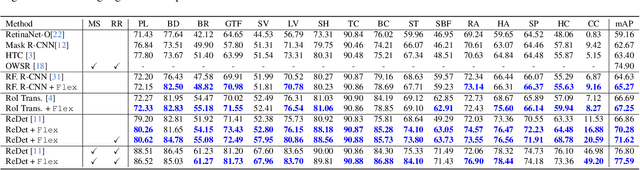
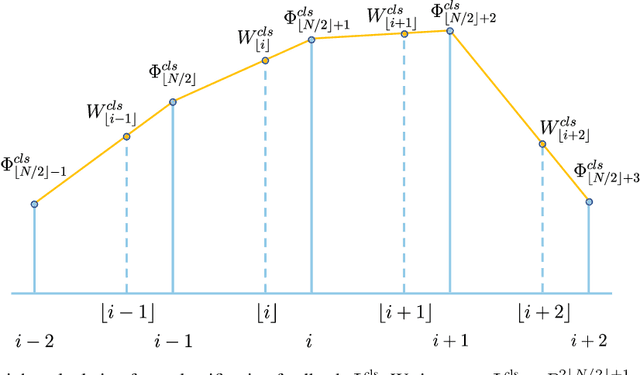
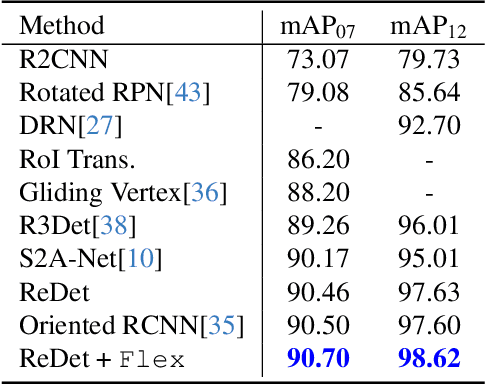
Neuroscience studies have shown that the human visual system utilizes high-level feedback information to guide lower-level perception, enabling adaptation to signals of different characteristics. In light of this, we propose Feedback multi-Level feature Extractor (Flex) to incorporate a similar mechanism for object detection. Flex refines feature selection based on image-wise and instance-level feedback information in response to image quality variation and classification uncertainty. Experimental results show that Flex offers consistent improvement to a range of existing SOTA methods on the challenging aerial object detection datasets including DOTA-v1.0, DOTA-v1.5, and HRSC2016. Although the design originates in aerial image detection, further experiments on MS COCO also reveal our module's efficacy in general detection models. Quantitative and qualitative analyses indicate that the improvements are closely related to image qualities, which match our motivation.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Nov 29, 2023We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
BIOCLIP: A Vision Foundation Model for the Tree of Life
Nov 30, 2023

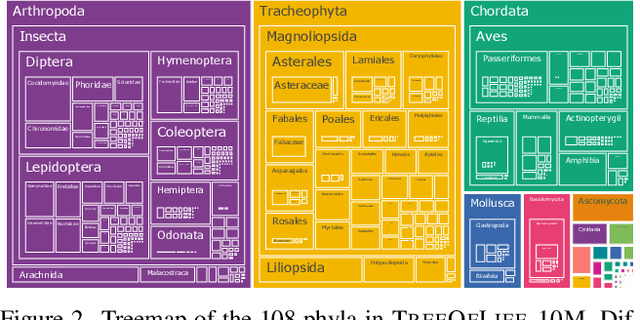

Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks, and find that BioCLIP consistently and substantially outperforms existing baselines (by 17% to 20% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. Our code, models and data will be made available at https://github.com/Imageomics/bioclip.
Reasoning with the Theory of Mind for Pragmatic Semantic Communication
Nov 30, 2023In this paper, a pragmatic semantic communication framework that enables effective goal-oriented information sharing between two-intelligent agents is proposed. In particular, semantics is defined as the causal state that encapsulates the fundamental causal relationships and dependencies among different features extracted from data. The proposed framework leverages the emerging concept in machine learning (ML) called theory of mind (ToM). It employs a dynamic two-level (wireless and semantic) feedback mechanism to continuously fine-tune neural network components at the transmitter. Thanks to the ToM, the transmitter mimics the actual mental state of the receiver's reasoning neural network operating semantic interpretation. Then, the estimated mental state at the receiver is dynamically updated thanks to the proposed dynamic two-level feedback mechanism. At the lower level, conventional channel quality metrics are used to optimize the channel encoding process based on the wireless communication channel's quality, ensuring an efficient mapping of semantic representations to a finite constellation. Additionally, a semantic feedback level is introduced, providing information on the receiver's perceived semantic effectiveness with minimal overhead. Numerical evaluations demonstrate the framework's ability to achieve efficient communication with a reduced amount of bits while maintaining the same semantics, outperforming conventional systems that do not exploit the ToM-based reasoning.
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Nov 30, 2023When watching a video, humans can naturally extract human actions from the surrounding scene context, even when action-scene combinations are unusual. However, unlike humans, video action recognition models often learn scene-biased action representations from the spurious correlation in training data, leading to poor performance in out-of-context scenarios. While scene-debiased models achieve improved performance in out-of-context scenarios, they often overlook valuable scene information in the data. Addressing this challenge, we propose Disentangled VIdeo representations of Action and Scene (DEVIAS), which aims to achieve holistic video understanding. Disentangled action and scene representations with our method could provide flexibility to adjust the emphasis on action or scene information depending on downstream task and dataset characteristics. Disentangled action and scene representations could be beneficial for both in-context and out-of-context video understanding. To this end, we employ slot attention to learn disentangled action and scene representations with a single model, along with auxiliary tasks that further guide slot attention. We validate the proposed method on both in-context datasets: UCF-101 and Kinetics-400, and out-of-context datasets: SCUBA and HAT. Our proposed method shows favorable performance across different datasets compared to the baselines, demonstrating its effectiveness in diverse video understanding scenarios.
U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation
Nov 29, 2023In this paper, we introduce U-Net v2, a new robust and efficient U-Net variant for medical image segmentation. It aims to augment the infusion of semantic information into low-level features while simultaneously refining high-level features with finer details. For an input image, we begin by extracting multi-level features with a deep neural network encoder. Next, we enhance the feature map of each level by infusing semantic information from higher-level features and integrating finer details from lower-level features through Hadamard product. Our novel skip connections empower features of all the levels with enriched semantic characteristics and intricate details. The improved features are subsequently transmitted to the decoder for further processing and segmentation. Our method can be seamlessly integrated into any Encoder-Decoder network. We evaluate our method on several public medical image segmentation datasets for skin lesion segmentation and polyp segmentation, and the experimental results demonstrate the segmentation accuracy of our new method over state-of-the-art methods, while preserving memory and computational efficiency. Code is available at: https://github.com/yaoppeng/U-Net\_v2
Using Ornstein-Uhlenbeck Process to understand Denoising Diffusion Probabilistic Model and its Noise Schedules
Nov 29, 2023The aim of this short note is to show that Denoising Diffusion Probabilistic Model DDPM, a non-homogeneous discrete-time Markov process, can be represented by a time-homogeneous continuous-time Markov process observed at non-uniformly sampled discrete times. Surprisingly, this continuous-time Markov process is the well-known and well-studied Ornstein-Ohlenbeck (OU) process, which was developed in 1930's for studying Brownian particles in Harmonic potentials. We establish the formal equivalence between DDPM and the OU process using its analytical solution. We further demonstrate that the design problem of the noise scheduler for non-homogeneous DDPM is equivalent to designing observation times for the OU process. We present several heuristic designs for observation times based on principled quantities such as auto-variance and Fisher Information and connect them to ad hoc noise schedules for DDPM. Interestingly, we show that the Fisher-Information-motivated schedule corresponds exactly the cosine schedule, which was developed without any theoretical foundation but is the current state-of-the-art noise schedule.
Learning to Cooperate and Communicate Over Imperfect Channels
Nov 24, 2023Information exchange in multi-agent systems improves the cooperation among agents, especially in partially observable settings. In the real world, communication is often carried out over imperfect channels. This requires agents to handle uncertainty due to potential information loss. In this paper, we consider a cooperative multi-agent system where the agents act and exchange information in a decentralized manner using a limited and unreliable channel. To cope with such channel constraints, we propose a novel communication approach based on independent Q-learning. Our method allows agents to dynamically adapt how much information to share by sending messages of different sizes, depending on their local observations and the channel's properties. In addition to this message size selection, agents learn to encode and decode messages to improve their jointly trained policies. We show that our approach outperforms approaches without adaptive capabilities in a novel cooperative digit-prediction environment and discuss its limitations in the traffic junction environment.