 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Physics-guided Shape-from-Template: Monocular Video Perception through Neural Surrogate Models
Nov 21, 2023
3D reconstruction of dynamic scenes is a long-standing problem in computer graphics and increasingly difficult the less information is available. Shape-from-Template (SfT) methods aim to reconstruct a template-based geometry from RGB images or video sequences, often leveraging just a single monocular camera without depth information, such as regular smartphone recordings. Unfortunately, existing reconstruction methods are either unphysical and noisy or slow in optimization. To solve this problem, we propose a novel SfT reconstruction algorithm for cloth using a pre-trained neural surrogate model that is fast to evaluate, stable, and produces smooth reconstructions due to a regularizing physics simulation. Differentiable rendering of the simulated mesh enables pixel-wise comparisons between the reconstruction and a target video sequence that can be used for a gradient-based optimization procedure to extract not only shape information but also physical parameters such as stretching, shearing, or bending stiffness of the cloth. This allows to retain a precise, stable, and smooth reconstructed geometry while reducing the runtime by a factor of 400-500 compared to $\phi$-SfT, a state-of-the-art physics-based SfT approach.
Dynamical phase transition in quantum neural networks with large depth
Nov 29, 2023Understanding the training dynamics of quantum neural networks is a fundamental task in quantum information science with wide impact in physics, chemistry and machine learning. In this work, we show that the late-time training dynamics of quantum neural networks can be described by the generalized Lotka-Volterra equations, which lead to a dynamical phase transition. When the targeted value of cost function crosses the minimum achievable value from above to below, the dynamics evolve from a frozen-kernel phase to a frozen-error phase, showing a duality between the quantum neural tangent kernel and the total error. In both phases, the convergence towards the fixed point is exponential, while at the critical point becomes polynomial. Via mapping the Hessian of the training dynamics to a Hamiltonian in the imaginary time, we reveal the nature of the phase transition to be second-order with the exponent $\nu=1$, where scale invariance and closing gap are observed at critical point. We also provide a non-perturbative analytical theory to explain the phase transition via a restricted Haar ensemble at late time, when the output state approaches the steady state. The theory findings are verified experimentally on IBM quantum devices.
Mixed-Precision Quantization for Federated Learning on Resource-Constrained Heterogeneous Devices
Nov 29, 2023While federated learning (FL) systems often utilize quantization to battle communication and computational bottlenecks, they have heretofore been limited to deploying fixed-precision quantization schemes. Meanwhile, the concept of mixed-precision quantization (MPQ), where different layers of a deep learning model are assigned varying bit-width, remains unexplored in the FL settings. We present a novel FL algorithm, FedMPQ, which introduces mixed-precision quantization to resource-heterogeneous FL systems. Specifically, local models, quantized so as to satisfy bit-width constraint, are trained by optimizing an objective function that includes a regularization term which promotes reduction of precision in some of the layers without significant performance degradation. The server collects local model updates, de-quantizes them into full-precision models, and then aggregates them into a global model. To initialize the next round of local training, the server relies on the information learned in the previous training round to customize bit-width assignments of the models delivered to different clients. In extensive benchmarking experiments on several model architectures and different datasets in both iid and non-iid settings, FedMPQ outperformed the baseline FL schemes that utilize fixed-precision quantization while incurring only a minor computational overhead on the participating devices.
HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional Inpainting
Nov 29, 2023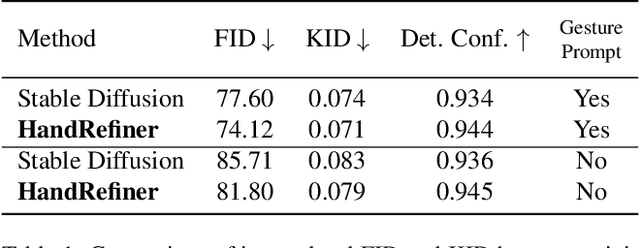
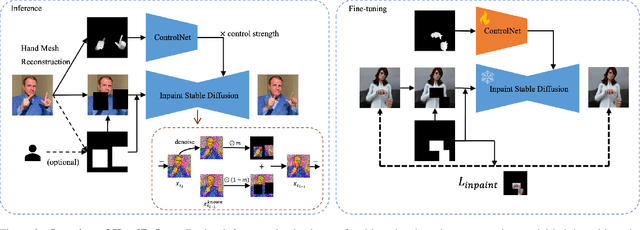


Diffusion models have achieved remarkable success in generating realistic images but suffer from generating accurate human hands, such as incorrect finger counts or irregular shapes. This difficulty arises from the complex task of learning the physical structure and pose of hands from training images, which involves extensive deformations and occlusions. For correct hand generation, our paper introduces a lightweight post-processing solution called $\textbf{HandRefiner}$. HandRefiner employs a conditional inpainting approach to rectify malformed hands while leaving other parts of the image untouched. We leverage the hand mesh reconstruction model that consistently adheres to the correct number of fingers and hand shape, while also being capable of fitting the desired hand pose in the generated image. Given a generated failed image due to malformed hands, we utilize ControlNet modules to re-inject such correct hand information. Additionally, we uncover a phase transition phenomenon within ControlNet as we vary the control strength. It enables us to take advantage of more readily available synthetic data without suffering from the domain gap between realistic and synthetic hands. Experiments demonstrate that HandRefiner can significantly improve the generation quality quantitatively and qualitatively. The code is available at https://github.com/wenquanlu/HandRefiner .
PEAN: A Diffusion-based Prior-Enhanced Attention Network for Scene Text Image Super-Resolution
Nov 29, 2023Scene text image super-resolution (STISR) aims at simultaneously increasing the resolution and readability of low-resolution scene text images, thus boosting the performance of the downstream recognition task. Two factors in scene text images, semantic information and visual structure, affect the recognition performance significantly. To mitigate the effects from these factors, this paper proposes a Prior-Enhanced Attention Network (PEAN). Specifically, a diffusion-based module is developed to enhance the text prior, hence offering better guidance for the SR network to generate SR images with higher semantic accuracy. Meanwhile, the proposed PEAN leverages an attention-based modulation module to understand scene text images by neatly perceiving the local and global dependence of images, despite the shape of the text. A multi-task learning paradigm is employed to optimize the network, enabling the model to generate legible SR images. As a result, PEAN establishes new SOTA results on the TextZoom benchmark. Experiments are also conducted to analyze the importance of the enhanced text prior as a means of improving the performance of the SR network. Code will be made available at https://github.com/jdfxzzy/PEAN.
LGFCTR: Local and Global Feature Convolutional Transformer for Image Matching
Nov 29, 2023Image matching that finding robust and accurate correspondences across images is a challenging task under extreme conditions. Capturing local and global features simultaneously is an important way to mitigate such an issue but recent transformer-based decoders were still stuck in the issues that CNN-based encoders only extract local features and the transformers lack locality. Inspired by the locality and implicit positional encoding of convolutions, a novel convolutional transformer is proposed to capture both local contexts and global structures more sufficiently for detector-free matching. Firstly, a universal FPN-like framework captures global structures in self-encoder as well as cross-decoder by transformers and compensates local contexts as well as implicit positional encoding by convolutions. Secondly, a novel convolutional transformer module explores multi-scale long range dependencies by a novel multi-scale attention and further aggregates local information inside dependencies for enhancing locality. Finally, a novel regression-based sub-pixel refinement module exploits the whole fine-grained window features for fine-level positional deviation regression. The proposed method achieves superior performances on a wide range of benchmarks. The code will be available on https://github.com/zwh0527/LGFCTR.
GPT-who: An Information Density-based Machine-Generated Text Detector
Oct 09, 2023The Uniform Information Density principle posits that humans prefer to spread information evenly during language production. In this work, we examine if the UID principle can help capture differences between Large Language Models (LLMs) and human-generated text. We propose GPT-who, the first psycholinguistically-aware multi-class domain-agnostic statistical-based detector. This detector employs UID-based features to model the unique statistical signature of each LLM and human author for accurate authorship attribution. We evaluate our method using 4 large-scale benchmark datasets and find that GPT-who outperforms state-of-the-art detectors (both statistical- & non-statistical-based) such as GLTR, GPTZero, OpenAI detector, and ZeroGPT by over $20$% across domains. In addition to superior performance, it is computationally inexpensive and utilizes an interpretable representation of text articles. We present the largest analysis of the UID-based representations of human and machine-generated texts (over 400k articles) to demonstrate how authors distribute information differently, and in ways that enable their detection using an off-the-shelf LM without any fine-tuning. We find that GPT-who can distinguish texts generated by very sophisticated LLMs, even when the overlying text is indiscernible.
Sensitivity-Based Layer Insertion for Residual and Feedforward Neural Networks
Nov 27, 2023
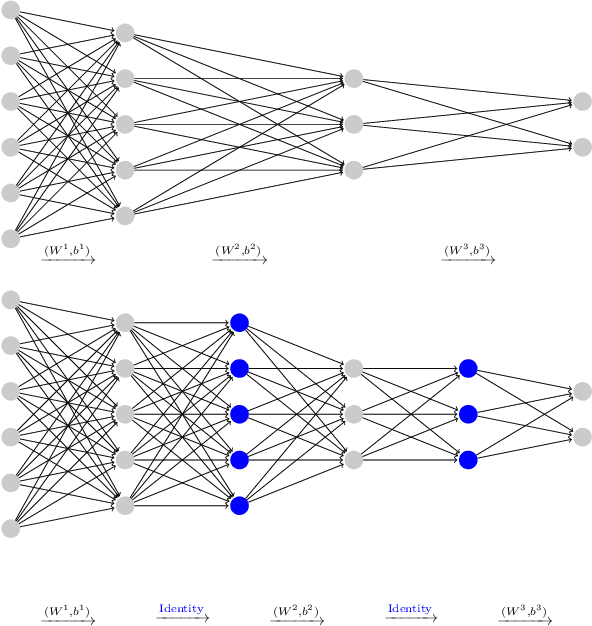

The training of neural networks requires tedious and often manual tuning of the network architecture. We propose a systematic method to insert new layers during the training process, which eliminates the need to choose a fixed network size before training. Our technique borrows techniques from constrained optimization and is based on first-order sensitivity information of the objective with respect to the virtual parameters that additional layers, if inserted, would offer. We consider fully connected feedforward networks with selected activation functions as well as residual neural networks. In numerical experiments, the proposed sensitivity-based layer insertion technique exhibits improved training decay, compared to not inserting the layer. Furthermore, the computational effort is reduced in comparison to inserting the layer from the beginning. The code is available at \url{https://github.com/LeonieKreis/layer_insertion_sensitivity_based}.
EucliDreamer: Fast and High-Quality Texturing for 3D Models with Stable Diffusion Depth
Nov 27, 2023This paper presents a novel method to generate textures for 3D models given text prompts and 3D meshes. Additional depth information is taken into account to perform the Score Distillation Sampling (SDS) process [28] with depth conditional Stable Diffusion [34]. We ran our model over the open-source dataset Objaverse [7] and conducted a user study to compare the results with those of various 3D texturing methods. We have shown that our model can generate more satisfactory results and produce various art styles for the same object. In addition, we achieved faster time when generating textures of comparable quality. We also conduct thorough ablation studies of how different factors may affect generation quality, including sampling steps, guidance scale, negative prompts, data augmentation, elevation range, and alternatives to SDS.
Generative AI and US Intellectual Property Law
Nov 27, 2023The rapidity with which generative AI has been adopted and advanced has raised legal and ethical questions related to the impact on artists rights, content production, data collection, privacy, accuracy of information, and intellectual property rights. Recent administrative and case law challenges have shown that generative AI software systems do not have independent intellectual property rights in the content that they generate. It remains to be seen whether human content creators can retain their intellectual property rights against generative AI software, its developers, operators, and owners for the misappropriation of the work of human creatives, given the metes and bounds of existing law. Early signs from various courts are mixed as to whether and to what degree the results generated by AI models meet the legal standards of infringement under existing law.