 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hy-Tracker: A Novel Framework for Enhancing Efficiency and Accuracy of Object Tracking in Hyperspectral Videos
Nov 30, 2023
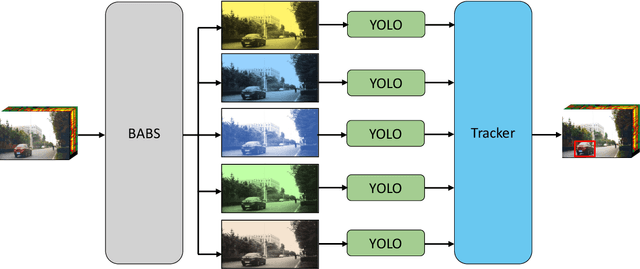
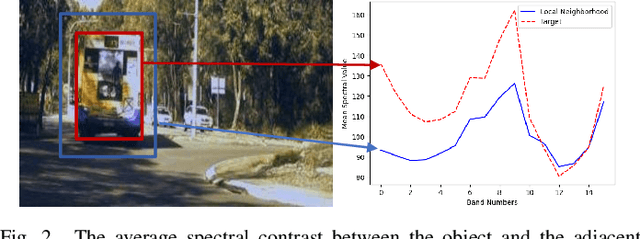
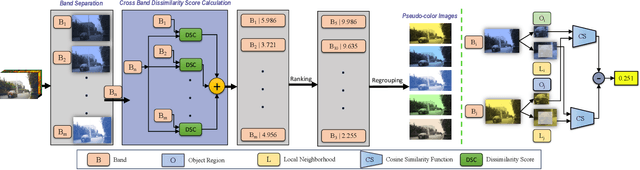
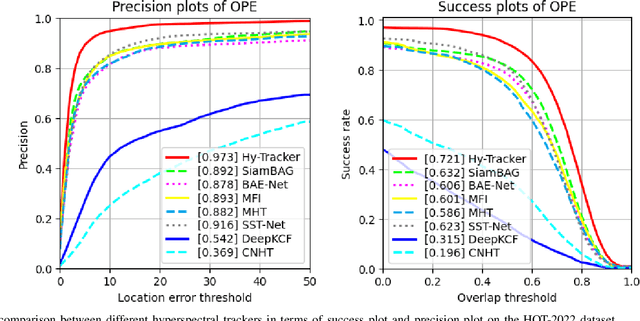
Hyperspectral object tracking has recently emerged as a topic of great interest in the remote sensing community. The hyperspectral image, with its many bands, provides a rich source of material information of an object that can be effectively used for object tracking. While most hyperspectral trackers are based on detection-based techniques, no one has yet attempted to employ YOLO for detecting and tracking the object. This is due to the presence of multiple spectral bands, the scarcity of annotated hyperspectral videos, and YOLO's performance limitation in managing occlusions, and distinguishing object in cluttered backgrounds. Therefore, in this paper, we propose a novel framework called Hy-Tracker, which aims to bridge the gap between hyperspectral data and state-of-the-art object detection methods to leverage the strengths of YOLOv7 for object tracking in hyperspectral videos. Hy-Tracker not only introduces YOLOv7 but also innovatively incorporates a refined tracking module on top of YOLOv7. The tracker refines the initial detections produced by YOLOv7, leading to improved object-tracking performance. Furthermore, we incorporate Kalman-Filter into the tracker, which addresses the challenges posed by scale variation and occlusion. The experimental results on hyperspectral benchmark datasets demonstrate the effectiveness of Hy-Tracker in accurately tracking objects across frames.
LEAP: LLM-Generation of Egocentric Action Programs
Nov 29, 2023We introduce LEAP (illustrated in Figure 1), a novel method for generating video-grounded action programs through use of a Large Language Model (LLM). These action programs represent the motoric, perceptual, and structural aspects of action, and consist of sub-actions, pre- and post-conditions, and control flows. LEAP's action programs are centered on egocentric video and employ recent developments in LLMs both as a source for program knowledge and as an aggregator and assessor of multimodal video information. We apply LEAP over a majority (87\%) of the training set of the EPIC Kitchens dataset, and release the resulting action programs as a publicly available dataset here (https://drive.google.com/drive/folders/1Cpkw_TI1IIxXdzor0pOXG3rWJWuKU5Ex?usp=drive_link). We employ LEAP as a secondary source of supervision, using its action programs in a loss term applied to action recognition and anticipation networks. We demonstrate sizable improvements in performance in both tasks due to training with the LEAP dataset. Our method achieves 1st place on the EPIC Kitchens Action Recognition leaderboard as of November 17 among the networks restricted to RGB-input (see Supplementary Materials).
Back to 3D: Few-Shot 3D Keypoint Detection with Back-Projected 2D Features
Nov 29, 2023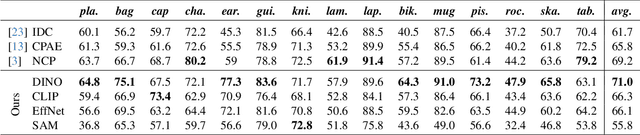
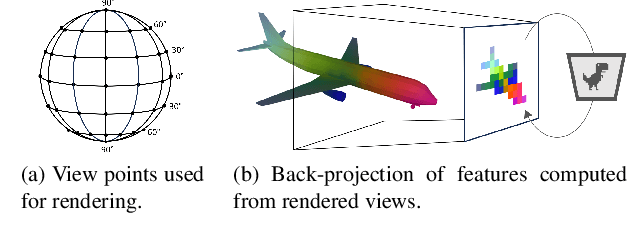

With the immense growth of dataset sizes and computing resources in recent years, so-called foundation models have become popular in NLP and vision tasks. In this work, we propose to explore foundation models for the task of keypoint detection on 3D shapes. A unique characteristic of keypoint detection is that it requires semantic and geometric awareness while demanding high localization accuracy. To address this problem, we propose, first, to back-project features from large pre-trained 2D vision models onto 3D shapes and employ them for this task. We show that we obtain robust 3D features that contain rich semantic information and analyze multiple candidate features stemming from different 2D foundation models. Second, we employ a keypoint candidate optimization module which aims to match the average observed distribution of keypoints on the shape and is guided by the back-projected features. The resulting approach achieves a new state of the art for few-shot keypoint detection on the KeyPointNet dataset, almost doubling the performance of the previous best methods.
Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning
Nov 29, 2023In this study, we are interested in imbuing robots with the capability of physically-grounded task planning. Recent advancements have shown that large language models (LLMs) possess extensive knowledge useful in robotic tasks, especially in reasoning and planning. However, LLMs are constrained by their lack of world grounding and dependence on external affordance models to perceive environmental information, which cannot jointly reason with LLMs. We argue that a task planner should be an inherently grounded, unified multimodal system. To this end, we introduce Robotic Vision-Language Planning (ViLa), a novel approach for long-horizon robotic planning that leverages vision-language models (VLMs) to generate a sequence of actionable steps. ViLa directly integrates perceptual data into its reasoning and planning process, enabling a profound understanding of commonsense knowledge in the visual world, including spatial layouts and object attributes. It also supports flexible multimodal goal specification and naturally incorporates visual feedback. Our extensive evaluation, conducted in both real-robot and simulated environments, demonstrates ViLa's superiority over existing LLM-based planners, highlighting its effectiveness in a wide array of open-world manipulation tasks.
Propagate & Distill: Towards Effective Graph Learners Using Propagation-Embracing MLPs
Nov 29, 2023Recent studies attempted to utilize multilayer perceptrons (MLPs) to solve semisupervised node classification on graphs, by training a student MLP by knowledge distillation from a teacher graph neural network (GNN). While previous studies have focused mostly on training the student MLP by matching the output probability distributions between the teacher and student models during distillation, it has not been systematically studied how to inject the structural information in an explicit and interpretable manner. Inspired by GNNs that separate feature transformation $T$ and propagation $\Pi$, we re-frame the distillation process as making the student MLP learn both $T$ and $\Pi$. Although this can be achieved by applying the inverse propagation $\Pi^{-1}$ before distillation from the teacher, it still comes with a high computational cost from large matrix multiplications during training. To solve this problem, we propose Propagate & Distill (P&D), which propagates the output of the teacher before distillation, which can be interpreted as an approximate process of the inverse propagation. We demonstrate that P&D can readily improve the performance of the student MLP.
CLiF-VQA: Enhancing Video Quality Assessment by Incorporating High-Level Semantic Information related to Human Feelings
Nov 13, 2023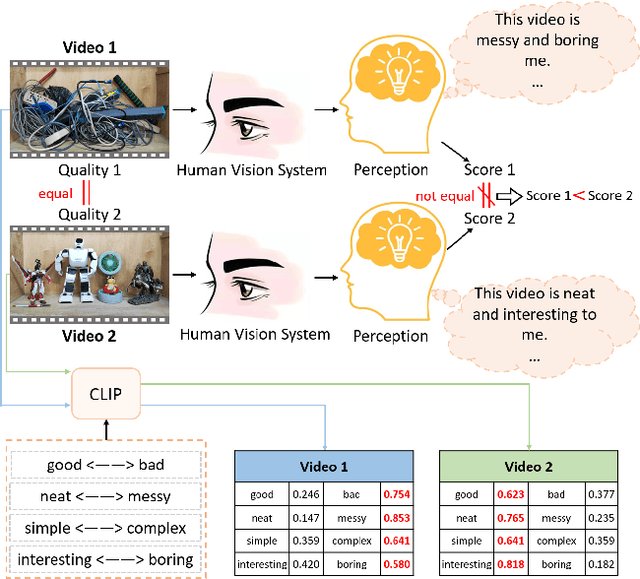
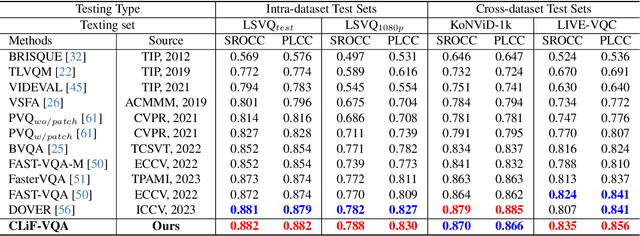
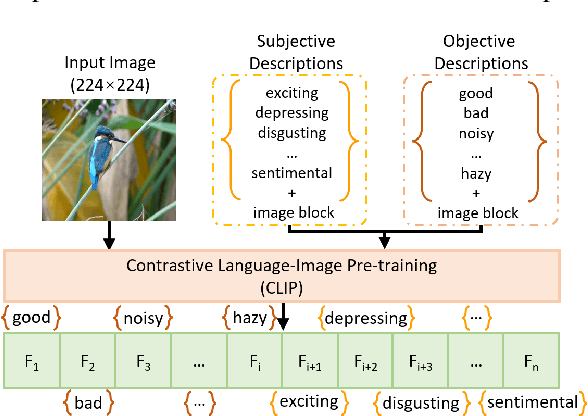
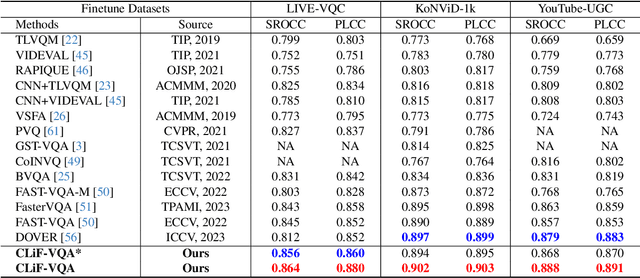
Video Quality Assessment (VQA) aims to simulate the process of perceiving video quality by the human visual system (HVS). The judgments made by HVS are always influenced by human subjective feelings. However, most of the current VQA research focuses on capturing various distortions in the spatial and temporal domains of videos, while ignoring the impact of human feelings. In this paper, we propose CLiF-VQA, which considers both features related to human feelings and spatial features of videos. In order to effectively extract features related to human feelings from videos, we explore the consistency between CLIP and human feelings in video perception for the first time. Specifically, we design multiple objective and subjective descriptions closely related to human feelings as prompts. Further we propose a novel CLIP-based semantic feature extractor (SFE) which extracts features related to human feelings by sliding over multiple regions of the video frame. In addition, we further capture the low-level-aware features of the video through a spatial feature extraction module. The two different features are then aggregated thereby obtaining the quality score of the video. Extensive experiments show that the proposed CLiF-VQA exhibits excellent performance on several VQA datasets.
Joint Antenna Selection and Power Allocation in Massive MIMO Systems with Cell Division Technique for MRT and ZF Precoding Schemes
Nov 26, 2023One of the most important challenges in the fifth generation (5G) of telecommunication systems is the efficiency of energy and spectrum. Massive multiple-input multiple-output (MIMO) systems have been proposed by researchers to resolve existing challenges. In the proposed system model of this paper, there is a base station (BS) around which several users and an eavesdropper (EVA) are evenly distributed. The information transmitted between BS and users is disrupted by an EVA, which highlights the importance of secure transfer. This paper analyzes secure energy efficiency (EE) of a massive MIMO system, and its purpose is to maximize the secure EE of the system. Several scenarios are considered to evaluate achieving the desired goal. To maximize the secure EE, selecting optimal number of antennas and cell division methods are employed. Each of these two methods is applied in a system with the maximum ratio transmission (MRT) and the zero forcing (ZF) precodings, and then the problem is solved. Maximum transmission power and minimum secure rate for users insert limitations to the optimization problem. Channel state information (CSI) is generally imperfect for users in any method, while CSI of the EVA is considered perfect as the worst case. Four iterative algorithms are designed to provide numerical assessments. The first algorithm calculates the optimal power of users without utilizing existing methods, the second one is related to the cell division method, the third one is based on the strategy of selecting optimal number of antennas, and forth one is based on a hybrid strategy.
Context-aware Neural Machine Translation for English-Japanese Business Scene Dialogues
Nov 20, 2023Despite the remarkable advancements in machine translation, the current sentence-level paradigm faces challenges when dealing with highly-contextual languages like Japanese. In this paper, we explore how context-awareness can improve the performance of the current Neural Machine Translation (NMT) models for English-Japanese business dialogues translation, and what kind of context provides meaningful information to improve translation. As business dialogue involves complex discourse phenomena but offers scarce training resources, we adapted a pretrained mBART model, finetuning on multi-sentence dialogue data, which allows us to experiment with different contexts. We investigate the impact of larger context sizes and propose novel context tokens encoding extra-sentential information, such as speaker turn and scene type. We make use of Conditional Cross-Mutual Information (CXMI) to explore how much of the context the model uses and generalise CXMI to study the impact of the extra-sentential context. Overall, we find that models leverage both preceding sentences and extra-sentential context (with CXMI increasing with context size) and we provide a more focused analysis on honorifics translation. Regarding translation quality, increased source-side context paired with scene and speaker information improves the model performance compared to previous work and our context-agnostic baselines, measured in BLEU and COMET metrics.
* MT Summit 2023, research track, link to paper in proceedings: https://aclanthology.org/2023.mtsummit-research.23/
Creating Temporally Correlated High-Resolution Power Injection Profiles Using Physics-Aware GAN
Nov 22, 2023Traditional smart meter measurements lack the granularity needed for real-time decision-making. To address this practical problem, we create a generative adversarial networks (GAN) model that enforces temporal consistency on its high-resolution outputs via hard inequality constraints using a convex optimization layer. A unique feature of our GAN model is that it is trained solely on slow timescale aggregated power information obtained from historical smart meter data. The results demonstrate that the model can successfully create minutely interval temporally-correlated instantaneous power injection profiles from 15-minute average power consumption information. This innovative approach, emphasizing inter-neuron constraints, offers a promising avenue for improved high-speed state estimation in distribution systems and enhances the applicability of data-driven solutions for monitoring such systems.
Text2Tree: Aligning Text Representation to the Label Tree Hierarchy for Imbalanced Medical Classification
Nov 28, 2023Deep learning approaches exhibit promising performances on various text tasks. However, they are still struggling on medical text classification since samples are often extremely imbalanced and scarce. Different from existing mainstream approaches that focus on supplementary semantics with external medical information, this paper aims to rethink the data challenges in medical texts and present a novel framework-agnostic algorithm called Text2Tree that only utilizes internal label hierarchy in training deep learning models. We embed the ICD code tree structure of labels into cascade attention modules for learning hierarchy-aware label representations. Two new learning schemes, Similarity Surrogate Learning (SSL) and Dissimilarity Mixup Learning (DML), are devised to boost text classification by reusing and distinguishing samples of other labels following the label representation hierarchy, respectively. Experiments on authoritative public datasets and real-world medical records show that our approach stably achieves superior performances over classical and advanced imbalanced classification methods.