 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TeG-DG: Textually Guided Domain Generalization for Face Anti-Spoofing
Nov 30, 2023
Enhancing the domain generalization performance of Face Anti-Spoofing (FAS) techniques has emerged as a research focus. Existing methods are dedicated to extracting domain-invariant features from various training domains. Despite the promising performance, the extracted features inevitably contain residual style feature bias (e.g., illumination, capture device), resulting in inferior generalization performance. In this paper, we propose an alternative and effective solution, the Textually Guided Domain Generalization (TeG-DG) framework, which can effectively leverage text information for cross-domain alignment. Our core insight is that text, as a more abstract and universal form of expression, can capture the commonalities and essential characteristics across various attacks, bridging the gap between different image domains. Contrary to existing vision-language models, the proposed framework is elaborately designed to enhance the domain generalization ability of the FAS task. Concretely, we first design a Hierarchical Attention Fusion (HAF) module to enable adaptive aggregation of visual features at different levels; Then, a Textual-Enhanced Visual Discriminator (TEVD) is proposed for not only better alignment between the two modalities but also to regularize the classifier with unbiased text features. TeG-DG significantly outperforms previous approaches, especially in situations with extremely limited source domain data (~14% and ~12% improvements on HTER and AUC respectively), showcasing impressive few-shot performance.
Spacewalk-18: A Benchmark for Multimodal and Long-form Procedural Video Understanding in Novel Domains
Nov 30, 2023Learning from videos is an emerging research area that enables robots to acquire skills from human demonstrations, such as procedural videos. To do this, video-language models must be able to obtain structured understandings, such as the temporal segmentation of a demonstration into sequences of actions and skills, and to generalize the understandings to novel domains. In pursuit of this goal, we introduce Spacewalk-18, a benchmark containing two tasks: (1) step recognition and (2) intra-video retrieval over a dataset of temporally segmented and labeled tasks in International Space Station spacewalk recordings. In tandem, the two tasks quantify a model's ability to make use of: (1) out-of-domain visual information; (2) a high temporal context window; and (3) multimodal (text + video) domains. This departs from existing benchmarks for procedural video understanding, which typically deal with short context lengths and can be solved with a single modality. Spacewalk-18, with its inherent multimodal and long-form complexity, exposes the high difficulty of task recognition and segmentation. We find that state-of-the-art methods perform poorly on our benchmark, demonstrating that the goal of generalizable procedural video understanding models is far out and underscoring the need to develop new approaches to these tasks. Data, model, and code will be publicly released.
Multilevel Saliency-Guided Self-Supervised Learning for Image Anomaly Detection
Nov 30, 2023
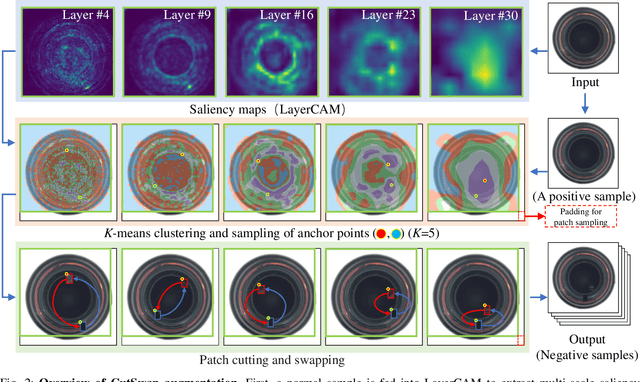
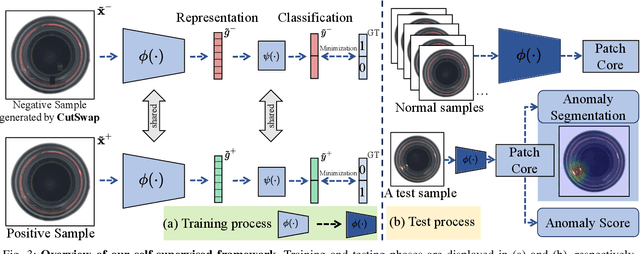
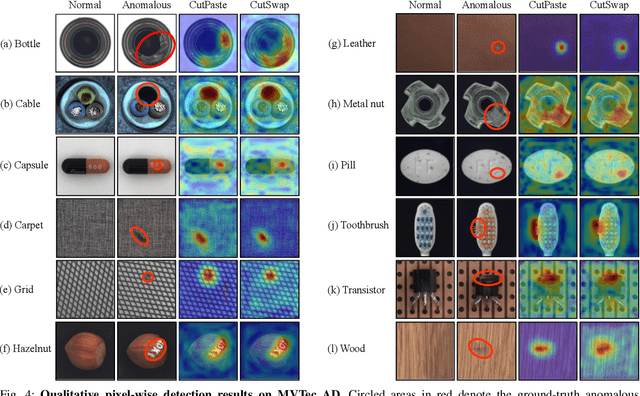
Anomaly detection (AD) is a fundamental task in computer vision. It aims to identify incorrect image data patterns which deviate from the normal ones. Conventional methods generally address AD by preparing augmented negative samples to enforce self-supervised learning. However, these techniques typically do not consider semantics during augmentation, leading to the generation of unrealistic or invalid negative samples. Consequently, the feature extraction network can be hindered from embedding critical features. In this study, inspired by visual attention learning approaches, we propose CutSwap, which leverages saliency guidance to incorporate semantic cues for augmentation. Specifically, we first employ LayerCAM to extract multilevel image features as saliency maps and then perform clustering to obtain multiple centroids. To fully exploit saliency guidance, on each map, we select a pixel pair from the cluster with the highest centroid saliency to form a patch pair. Such a patch pair includes highly similar context information with dense semantic correlations. The resulting negative sample is created by swapping the locations of the patch pair. Compared to prior augmentation methods, CutSwap generates more subtle yet realistic negative samples to facilitate quality feature learning. Extensive experimental and ablative evaluations demonstrate that our method achieves state-of-the-art AD performance on two mainstream AD benchmark datasets.
Benchmarking Robustness of Text-Image Composed Retrieval
Nov 30, 2023Text-image composed retrieval aims to retrieve the target image through the composed query, which is specified in the form of an image plus some text that describes desired modifications to the input image. It has recently attracted attention due to its ability to leverage both information-rich images and concise language to precisely express the requirements for target images. However, the robustness of these approaches against real-world corruptions or further text understanding has never been studied. In this paper, we perform the first robustness study and establish three new diversified benchmarks for systematic analysis of text-image composed retrieval against natural corruptions in both vision and text and further probe textural understanding. For natural corruption analysis, we introduce two new large-scale benchmark datasets, CIRR-C and FashionIQ-C for testing in open domain and fashion domain respectively, both of which apply 15 visual corruptions and 7 textural corruptions. For textural understanding analysis, we introduce a new diagnostic dataset CIRR-D by expanding the original raw data with synthetic data, which contains modified text to better probe textual understanding ability including numerical variation, attribute variation, object removal, background variation, and fine-grained evaluation. The code and benchmark datasets are available at https://github.com/SunTongtongtong/Benchmark-Robustness-Text-Image-Compose-Retrieval.
AV-RIR: Audio-Visual Room Impulse Response Estimation
Nov 30, 2023Accurate estimation of Room Impulse Response (RIR), which captures an environment's acoustic properties, is important for speech processing and AR/VR applications. We propose AV-RIR, a novel multi-modal multi-task learning approach to accurately estimate the RIR from a given reverberant speech signal and the visual cues of its corresponding environment. AV-RIR builds on a novel neural codec-based architecture that effectively captures environment geometry and materials properties and solves speech dereverberation as an auxiliary task by using multi-task learning. We also propose Geo-Mat features that augment material information into visual cues and CRIP that improves late reverberation components in the estimated RIR via image-to-RIR retrieval by 86%. Empirical results show that AV-RIR quantitatively outperforms previous audio-only and visual-only approaches by achieving 36% - 63% improvement across various acoustic metrics in RIR estimation. Additionally, it also achieves higher preference scores in human evaluation. As an auxiliary benefit, dereverbed speech from AV-RIR shows competitive performance with the state-of-the-art in various spoken language processing tasks and outperforms reverberation time error score in the real-world AVSpeech dataset. Qualitative examples of both synthesized reverberant speech and enhanced speech can be found at https://www.youtube.com/watch?v=tTsKhviukAE.
IAG: Induction-Augmented Generation Framework for Answering Reasoning Questions
Nov 30, 2023Retrieval-Augmented Generation (RAG), by incorporating external knowledge with parametric memory of language models, has become the state-of-the-art architecture for open-domain QA tasks. However, common knowledge bases are inherently constrained by limited coverage and noisy information, making retrieval-based approaches inadequate to answer implicit reasoning questions. In this paper, we propose an Induction-Augmented Generation (IAG) framework that utilizes inductive knowledge along with the retrieved documents for implicit reasoning. We leverage large language models (LLMs) for deriving such knowledge via a novel prompting method based on inductive reasoning patterns. On top of this, we implement two versions of IAG named IAG-GPT and IAG-Student, respectively. IAG-GPT directly utilizes the knowledge generated by GPT-3 for answer prediction, while IAG-Student gets rid of dependencies on GPT service at inference time by incorporating a student inductor model. The inductor is firstly trained via knowledge distillation and further optimized by back-propagating the generator feedback via differentiable beam scores. Experimental results show that IAG outperforms RAG baselines as well as ChatGPT on two Open-Domain QA tasks. Notably, our best models have won the first place in the official leaderboards of CSQA2.0 (since Nov 1, 2022) and StrategyQA (since Jan 8, 2023).
Hy-Tracker: A Novel Framework for Enhancing Efficiency and Accuracy of Object Tracking in Hyperspectral Videos
Nov 30, 2023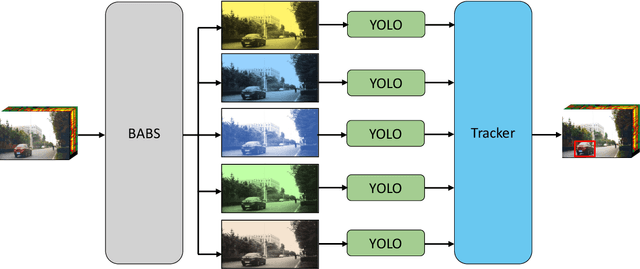
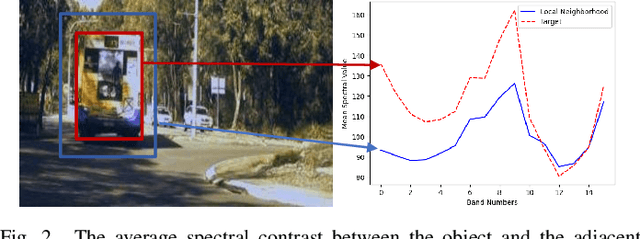
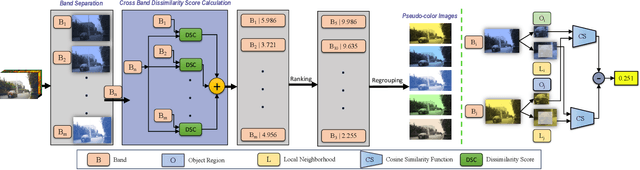
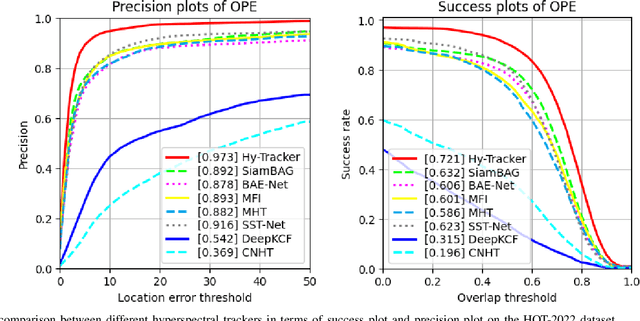
Hyperspectral object tracking has recently emerged as a topic of great interest in the remote sensing community. The hyperspectral image, with its many bands, provides a rich source of material information of an object that can be effectively used for object tracking. While most hyperspectral trackers are based on detection-based techniques, no one has yet attempted to employ YOLO for detecting and tracking the object. This is due to the presence of multiple spectral bands, the scarcity of annotated hyperspectral videos, and YOLO's performance limitation in managing occlusions, and distinguishing object in cluttered backgrounds. Therefore, in this paper, we propose a novel framework called Hy-Tracker, which aims to bridge the gap between hyperspectral data and state-of-the-art object detection methods to leverage the strengths of YOLOv7 for object tracking in hyperspectral videos. Hy-Tracker not only introduces YOLOv7 but also innovatively incorporates a refined tracking module on top of YOLOv7. The tracker refines the initial detections produced by YOLOv7, leading to improved object-tracking performance. Furthermore, we incorporate Kalman-Filter into the tracker, which addresses the challenges posed by scale variation and occlusion. The experimental results on hyperspectral benchmark datasets demonstrate the effectiveness of Hy-Tracker in accurately tracking objects across frames.
CADTalk: An Algorithm and Benchmark for Semantic Commenting of CAD Programs
Nov 30, 2023CAD programs are a popular way to compactly encode shapes as a sequence of operations that are easy to parametrically modify. However, without sufficient semantic comments and structure, such programs can be challenging to understand, let alone modify. We introduce the problem of semantic commenting CAD programs, wherein the goal is to segment the input program into code blocks corresponding to semantically meaningful shape parts and assign a semantic label to each block. We solve the problem by combining program parsing with visual-semantic analysis afforded by recent advances in foundational language and vision models. Specifically, by executing the input programs, we create shapes, which we use to generate conditional photorealistic images to make use of semantic annotators for such images. We then distill the information across the images and link back to the original programs to semantically comment on them. Additionally, we collected and annotated a benchmark dataset, CADTalk, consisting of 5,280 machine-made programs and 45 human-made programs with ground truth semantic comments to foster future research. We extensively evaluated our approach, compared to a GPT-based baseline approach, and an open-set shape segmentation baseline, i.e., PartSLIP, and reported an 83.24% accuracy on the new CADTalk dataset. Project page: https://enigma-li.github.io/CADTalk/.
Event-based Continuous Color Video Decompression from Single Frames
Nov 30, 2023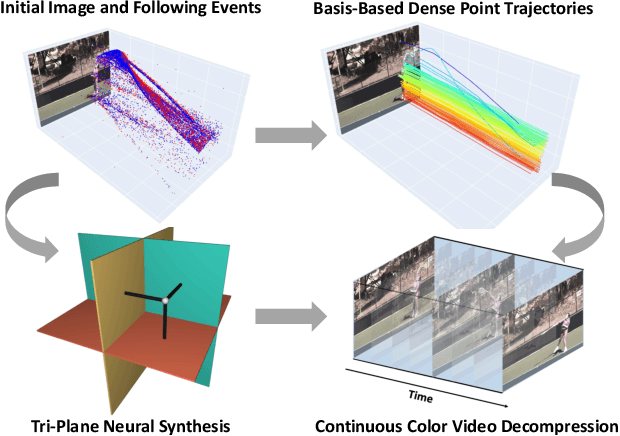
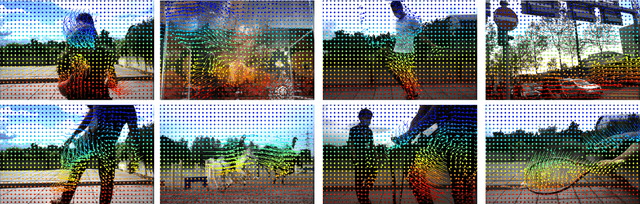
We present ContinuityCam, a novel approach to generate a continuous video from a single static RGB image, using an event camera. Conventional cameras struggle with high-speed motion capture due to bandwidth and dynamic range limitations. Event cameras are ideal sensors to solve this problem because they encode compressed change information at high temporal resolution. In this work, we propose a novel task called event-based continuous color video decompression, pairing single static color frames and events to reconstruct temporally continuous videos. Our approach combines continuous long-range motion modeling with a feature-plane-based synthesis neural integration model, enabling frame prediction at arbitrary times within the events. Our method does not rely on additional frames except for the initial image, increasing, thus, the robustness to sudden light changes, minimizing the prediction latency, and decreasing the bandwidth requirement. We introduce a novel single objective beamsplitter setup that acquires aligned images and events and a novel and challenging Event Extreme Decompression Dataset (E2D2) that tests the method in various lighting and motion profiles. We thoroughly evaluate our method through benchmarking reconstruction as well as various downstream tasks. Our approach significantly outperforms the event- and image- based baselines in the proposed task.
Enhancing Ligand Pose Sampling for Molecular Docking
Nov 30, 2023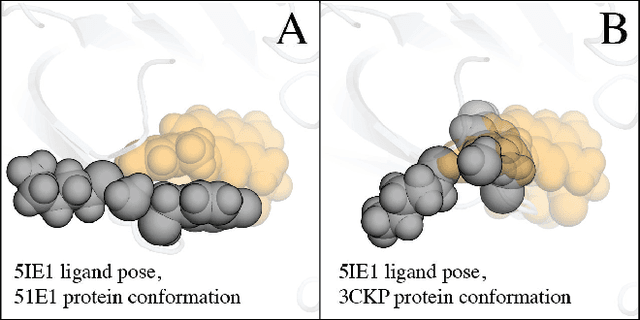
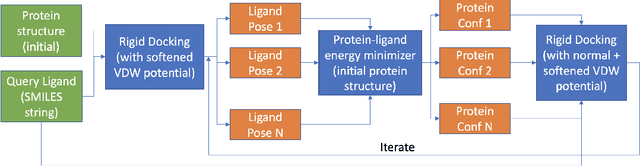
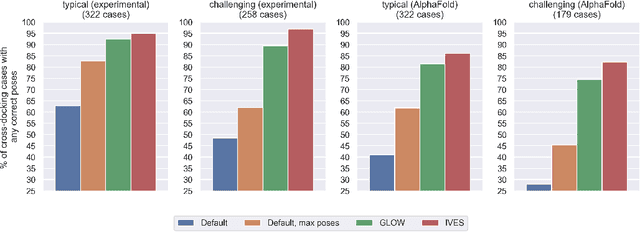
Deep learning promises to dramatically improve scoring functions for molecular docking, leading to substantial advances in binding pose prediction and virtual screening. To train scoring functions-and to perform molecular docking-one must generate a set of candidate ligand binding poses. Unfortunately, the sampling protocols currently used to generate candidate poses frequently fail to produce any poses close to the correct, experimentally determined pose, unless information about the correct pose is provided. This limits the accuracy of learned scoring functions and molecular docking. Here, we describe two improved protocols for pose sampling: GLOW (auGmented sampLing with sOftened vdW potential) and a novel technique named IVES (IteratiVe Ensemble Sampling). Our benchmarking results demonstrate the effectiveness of our methods in improving the likelihood of sampling accurate poses, especially for binding pockets whose shape changes substantially when different ligands bind. This improvement is observed across both experimentally determined and AlphaFold-generated protein structures. Additionally, we present datasets of candidate ligand poses generated using our methods for each of around 5,000 protein-ligand cross-docking pairs, for training and testing scoring functions. To benefit the research community, we provide these cross-docking datasets and an open-source Python implementation of GLOW and IVES at https://github.com/drorlab/GLOW_IVES .