 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023
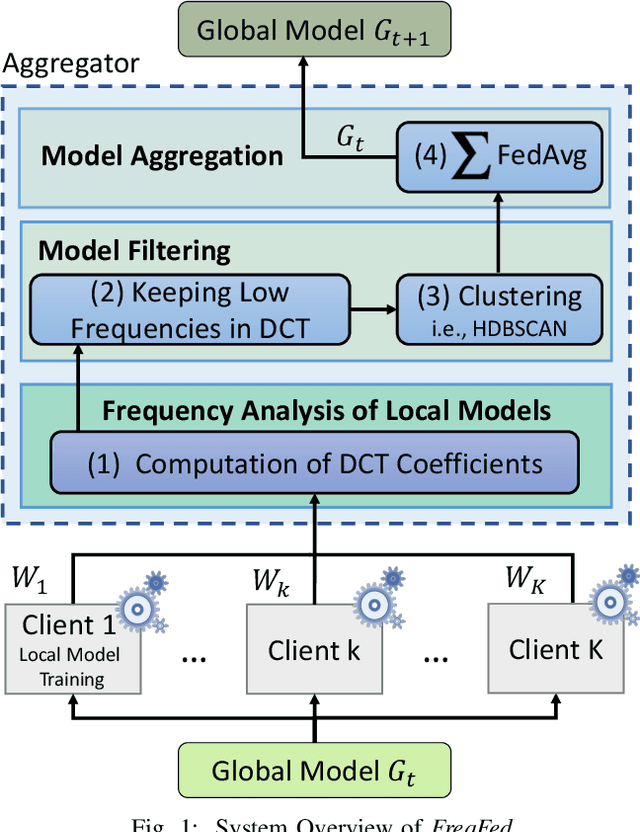
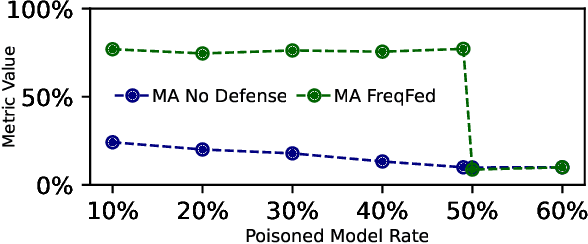

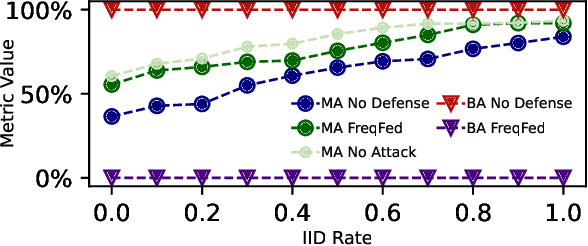
Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
Domain Invariant Representation Learning and Sleep Dynamics Modeling for Automatic Sleep Staging
Dec 07, 2023Sleep staging has become a critical task in diagnosing and treating sleep disorders to prevent sleep related diseases. With rapidly growing large scale public sleep databases and advances in machine learning, significant progress has been made toward automatic sleep staging. However, previous studies face some critical problems in sleep studies; the heterogeneity of subjects' physiological signals, the inability to extract meaningful information from unlabeled sleep signal data to improve predictive performances, the difficulty in modeling correlations between sleep stages, and the lack of an effective mechanism to quantify predictive uncertainty. In this study, we propose a neural network based automatic sleep staging model, named DREAM, to learn domain generalized representations from physiological signals and models sleep dynamics. DREAM learns sleep related and subject invariant representations from diverse subjects' sleep signal segments and models sleep dynamics by capturing interactions between sequential signal segments and between sleep stages. In the experiments, we demonstrate that DREAM outperforms the existing sleep staging methods on three datasets. The case study demonstrates that our model can learn the generalized decision function resulting in good prediction performances for the new subjects, especially in case there are differences between testing and training subjects. The usage of unlabeled data shows the benefit of leveraging unlabeled EEG data. Further, uncertainty quantification demonstrates that DREAM provides prediction uncertainty, making the model reliable and helping sleep experts in real world applications.
Joint-Individual Fusion Structure with Fusion Attention Module for Multi-Modal Skin Cancer Classification
Dec 07, 2023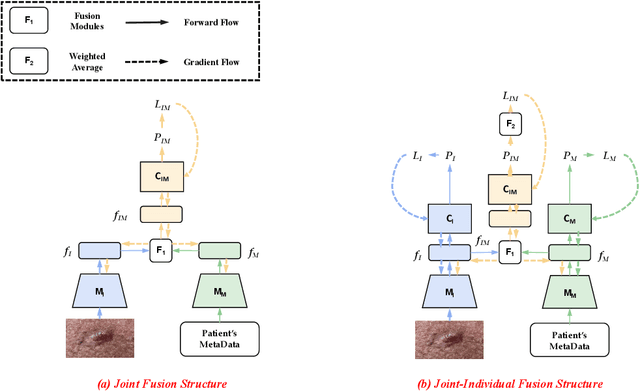
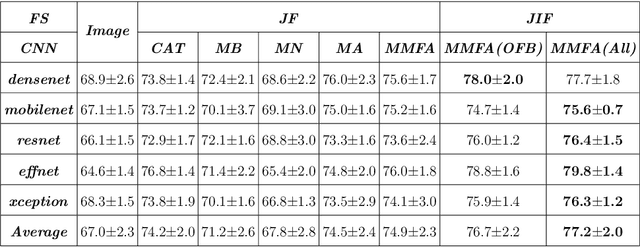
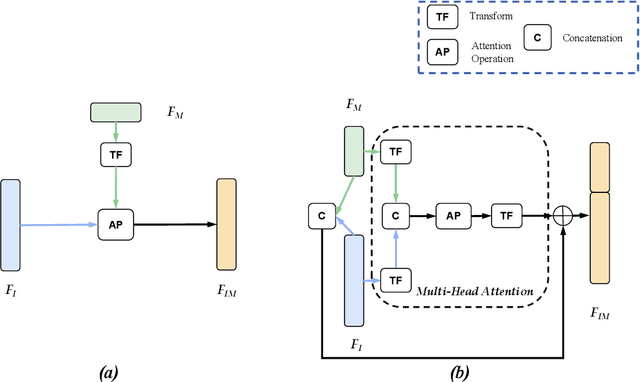
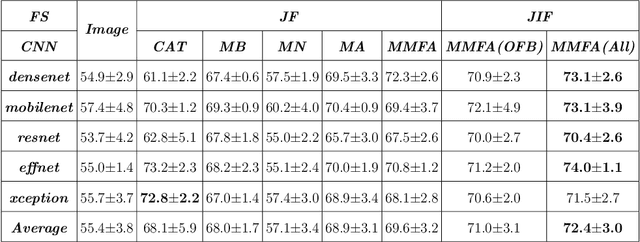
Most convolutional neural network (CNN) based methods for skin cancer classification obtain their results using only dermatological images. Although good classification results have been shown, more accurate results can be achieved by considering the patient's metadata, which is valuable clinical information for dermatologists. Current methods only use the simple joint fusion structure (FS) and fusion modules (FMs) for the multi-modal classification methods, there still is room to increase the accuracy by exploring more advanced FS and FM. Therefore, in this paper, we design a new fusion method that combines dermatological images (dermoscopy images or clinical images) and patient metadata for skin cancer classification from the perspectives of FS and FM. First, we propose a joint-individual fusion (JIF) structure that learns the shared features of multi-modality data and preserves specific features simultaneously. Second, we introduce a fusion attention (FA) module that enhances the most relevant image and metadata features based on both the self and mutual attention mechanism to support the decision-making pipeline. We compare the proposed JIF-MMFA method with other state-of-the-art fusion methods on three different public datasets. The results show that our JIF-MMFA method improves the classification results for all tested CNN backbones and performs better than the other fusion methods on the three public datasets, demonstrating our method's effectiveness and robustness
Role of Uncertainty in Anticipatory Trajectory Prediction for a Ping-Pong Playing Robot
Dec 05, 2023Robotic interaction in fast-paced environments presents a substantial challenge, particularly in tasks requiring the prediction of dynamic, non-stationary objects for timely and accurate responses. An example of such a task is ping-pong, where the physical limitations of a robot may prevent it from reaching its goal in the time it takes the ball to cross the table. The scene of a ping-pong match contains rich visual information of a player's movement that can allow future game state prediction, with varying degrees of uncertainty. To this aim, we present a visual modeling, prediction, and control system to inform a ping-pong playing robot utilizing visual model uncertainty to allow earlier motion of the robot throughout the game. We present demonstrations and metrics in simulation to show the benefit of incorporating model uncertainty, the limitations of current standard model uncertainty estimators, and the need for more verifiable model uncertainty estimation. Our code is publicly available.
Towards the Inferrence of Structural Similarity of Combinatorial Landscapes
Dec 05, 2023One of the most common problem-solving heuristics is by analogy. For a given problem, a solver can be viewed as a strategic walk on its fitness landscape. Thus if a solver works for one problem instance, we expect it will also be effective for other instances whose fitness landscapes essentially share structural similarities with each other. However, due to the black-box nature of combinatorial optimization, it is far from trivial to infer such similarity in real-world scenarios. To bridge this gap, by using local optima network as a proxy of fitness landscapes, this paper proposed to leverage graph data mining techniques to conduct qualitative and quantitative analyses to explore the latent topological structural information embedded in those landscapes. By conducting large-scale empirical experiments on three classic combinatorial optimization problems, we gain concrete evidence to support the existence of structural similarity between landscapes of the same classes within neighboring dimensions. We also interrogated the relationship between landscapes of different problem classes.
Lenna: Language Enhanced Reasoning Detection Assistant
Dec 05, 2023With the fast-paced development of multimodal large language models (MLLMs), we can now converse with AI systems in natural languages to understand images. However, the reasoning power and world knowledge embedded in the large language models have been much less investigated and exploited for image perception tasks. In this paper, we propose Lenna, a language-enhanced reasoning detection assistant, which utilizes the robust multimodal feature representation of MLLMs, while preserving location information for detection. This is achieved by incorporating an additional <DET> token in the MLLM vocabulary that is free of explicit semantic context but serves as a prompt for the detector to identify the corresponding position. To evaluate the reasoning capability of Lenna, we construct a ReasonDet dataset to measure its performance on reasoning-based detection. Remarkably, Lenna demonstrates outstanding performance on ReasonDet and comes with significantly low training costs. It also incurs minimal transferring overhead when extended to other tasks. Our code and model will be available at https://git.io/Lenna.
DRAFT: Dense Retrieval Augmented Few-shot Topic classifier Framework
Dec 05, 2023With the growing volume of diverse information, the demand for classifying arbitrary topics has become increasingly critical. To address this challenge, we introduce DRAFT, a simple framework designed to train a classifier for few-shot topic classification. DRAFT uses a few examples of a specific topic as queries to construct Customized dataset with a dense retriever model. Multi-query retrieval (MQR) algorithm, which effectively handles multiple queries related to a specific topic, is applied to construct the Customized dataset. Subsequently, we fine-tune a classifier using the Customized dataset to identify the topic. To demonstrate the efficacy of our proposed approach, we conduct evaluations on both widely used classification benchmark datasets and manually constructed datasets with 291 diverse topics, which simulate diverse contents encountered in real-world applications. DRAFT shows competitive or superior performance compared to baselines that use in-context learning, such as GPT-3 175B and InstructGPT 175B, on few-shot topic classification tasks despite having 177 times fewer parameters, demonstrating its effectiveness.
A Comprehensive Study of Vision Transformers in Image Classification Tasks
Dec 05, 2023
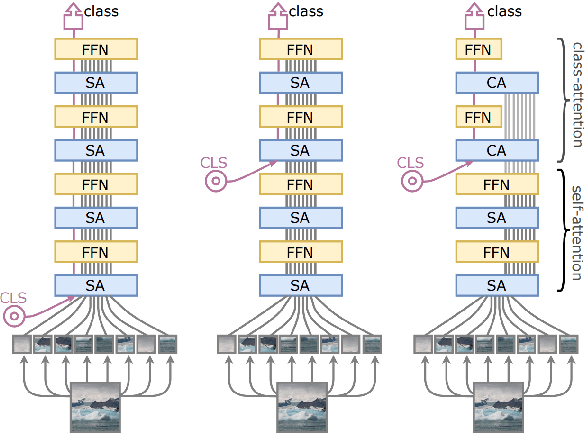
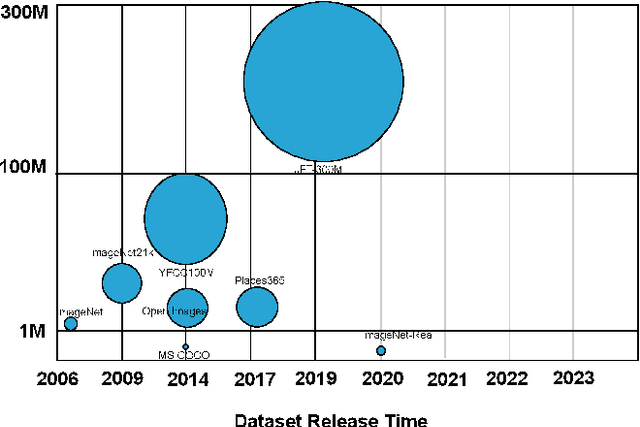
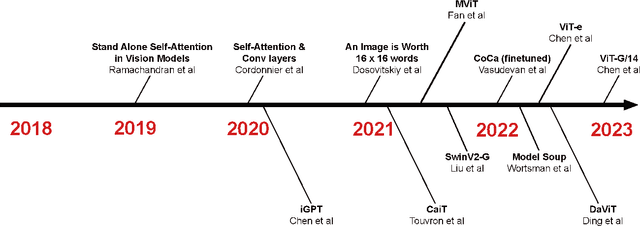
Image Classification is a fundamental task in the field of computer vision that frequently serves as a benchmark for gauging advancements in Computer Vision. Over the past few years, significant progress has been made in image classification due to the emergence of deep learning. However, challenges still exist, such as modeling fine-grained visual information, high computation costs, the parallelism of the model, and inconsistent evaluation protocols across datasets. In this paper, we conduct a comprehensive survey of existing papers on Vision Transformers for image classification. We first introduce the popular image classification datasets that influenced the design of models. Then, we present Vision Transformers models in chronological order, starting with early attempts at adapting attention mechanism to vision tasks followed by the adoption of vision transformers, as they have demonstrated success in capturing intricate patterns and long-range dependencies within images. Finally, we discuss open problems and shed light on opportunities for image classification to facilitate new research ideas.
LLaFS: When Large-Language Models Meet Few-Shot Segmentation
Dec 05, 2023This paper proposes LLaFS, the first attempt to leverage large language models (LLMs) in few-shot segmentation. In contrast to the conventional few-shot segmentation methods that only rely on the limited and biased information from the annotated support images, LLaFS leverages the vast prior knowledge gained by LLM as an effective supplement and directly uses the LLM to segment images in a few-shot manner. To enable the text-based LLM to handle image-related tasks, we carefully design an input instruction that allows the LLM to produce segmentation results represented as polygons, and propose a region-attribute table to simulate the human visual mechanism and provide multi-modal guidance. We also synthesize pseudo samples and use curriculum learning for pretraining to augment data and achieve better optimization. LLaFS achieves state-of-the-art results on multiple datasets, showing the potential of using LLMs for few-shot computer vision tasks. Code will be available at https://github.com/lanyunzhu99/LLaFS.
Information-Theoretic Generalization Analysis for Topology-aware Heterogeneous Federated Edge Learning over Noisy Channels
Oct 25, 2023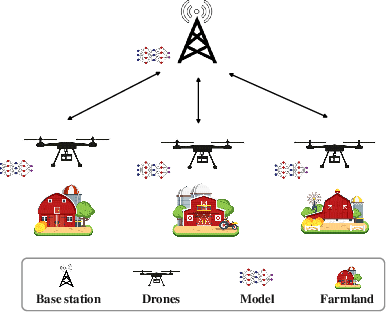
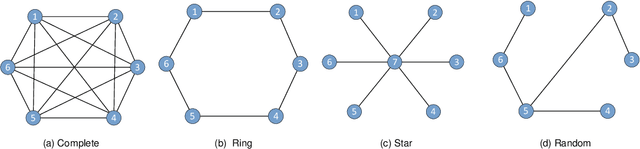
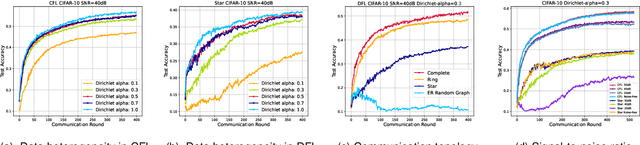
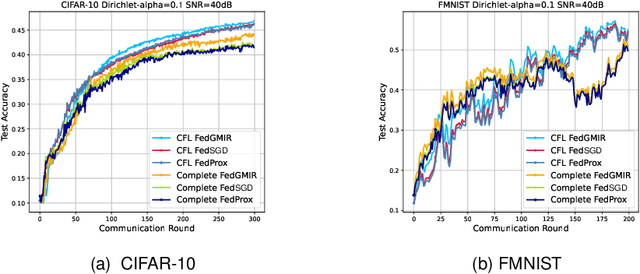
With the rapid growth of edge intelligence, the deployment of federated learning (FL) over wireless networks has garnered increasing attention, which is called Federated Edge Learning (FEEL). In FEEL, both mobile devices transmitting model parameters over noisy channels and collecting data in diverse environments pose challenges to the generalization of trained models. Moreover, devices can engage in decentralized FL via Device-to-Device communication while the communication topology of connected devices also impacts the generalization of models. Most recent theoretical studies overlook the incorporation of all these effects into FEEL when developing generalization analyses. In contrast, our work presents an information-theoretic generalization analysis for topology-aware FEEL in the presence of data heterogeneity and noisy channels. Additionally, we propose a novel regularization method called Federated Global Mutual Information Reduction (FedGMIR) to enhance the performance of models based on our analysis. Numerical results validate our theoretical findings and provide evidence for the effectiveness of the proposed method.