 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023
Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
AI-Generated Images Introduce Invisible Relevance Bias to Text-Image Retrieval
Nov 27, 2023With the advancement of generation models, AI-generated content (AIGC) is becoming more realistic, flooding the Internet. A recent study suggests that this phenomenon has elevated the issue of source bias in text retrieval for web searches. Specifically, neural retrieval models tend to rank generated texts higher than human-written texts. In this paper, we extend the study of this bias to cross-modal retrieval. Firstly, we successfully construct a suitable benchmark to explore the existence of the bias. Subsequent extensive experiments on this benchmark reveal that AI-generated images introduce an invisible relevance bias to text-image retrieval models. Specifically, our experiments show that text-image retrieval models tend to rank the AI-generated images higher than the real images, even though the AI-generated images do not exhibit more visually relevant features to the query than real images. This invisible relevance bias is prevalent across retrieval models with varying training data and architectures. Furthermore, our subsequent exploration reveals that the inclusion of AI-generated images in the training data of the retrieval models exacerbates the invisible relevance bias. The above phenomenon triggers a vicious cycle, which makes the invisible relevance bias become more and more serious. To elucidate the potential causes of invisible relevance and address the aforementioned issues, we introduce an effective training method aimed at alleviating the invisible relevance bias. Subsequently, we apply our proposed debiasing method to retroactively identify the causes of invisible relevance, revealing that the AI-generated images induce the image encoder to embed additional information into their representation. This information exhibits a certain consistency across generated images with different semantics and can make the retriever estimate a higher relevance score.
NeISF: Neural Incident Stokes Field for Geometry and Material Estimation
Nov 29, 2023Multi-view inverse rendering is the problem of estimating the scene parameters such as shapes, materials, or illuminations from a sequence of images captured under different viewpoints. Many approaches, however, assume single light bounce and thus fail to recover challenging scenarios like inter-reflections. On the other hand, simply extending those methods to consider multi-bounced light requires more assumptions to alleviate the ambiguity. To address this problem, we propose Neural Incident Stokes Fields (NeISF), a multi-view inverse rendering framework that reduces ambiguities using polarization cues. The primary motivation for using polarization cues is that it is the accumulation of multi-bounced light, providing rich information about geometry and material. Based on this knowledge, the proposed incident Stokes field efficiently models the accumulated polarization effect with the aid of an original physically-based differentiable polarimetric renderer. Lastly, experimental results show that our method outperforms the existing works in synthetic and real scenarios.
VITATECS: A Diagnostic Dataset for Temporal Concept Understanding of Video-Language Models
Nov 29, 2023The ability to perceive how objects change over time is a crucial ingredient in human intelligence. However, current benchmarks cannot faithfully reflect the temporal understanding abilities of video-language models (VidLMs) due to the existence of static visual shortcuts. To remedy this issue, we present VITATECS, a diagnostic VIdeo-Text dAtaset for the evaluation of TEmporal Concept underStanding. Specifically, we first introduce a fine-grained taxonomy of temporal concepts in natural language in order to diagnose the capability of VidLMs to comprehend different temporal aspects. Furthermore, to disentangle the correlation between static and temporal information, we generate counterfactual video descriptions that differ from the original one only in the specified temporal aspect. We employ a semi-automatic data collection framework using large language models and human-in-the-loop annotation to obtain high-quality counterfactual descriptions efficiently. Evaluation of representative video-language understanding models confirms their deficiency in temporal understanding, revealing the need for greater emphasis on the temporal elements in video-language research.
Zero-shot Retrieval: Augmenting Pre-trained Models with Search Engines
Nov 29, 2023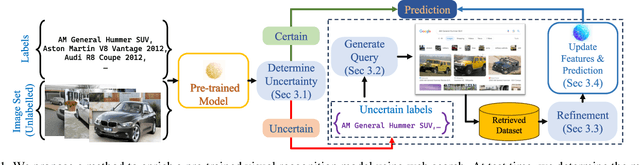
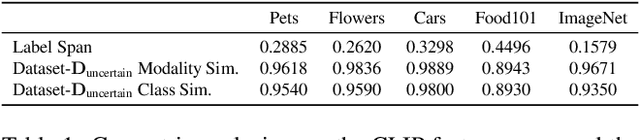
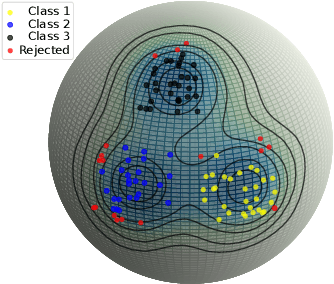
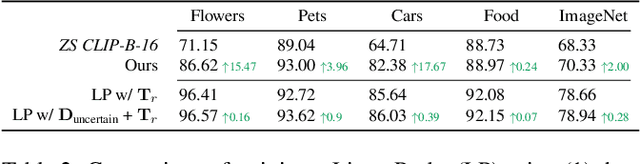
Large pre-trained models can dramatically reduce the amount of task-specific data required to solve a problem, but they often fail to capture domain-specific nuances out of the box. The Web likely contains the information necessary to excel on any specific application, but identifying the right data a priori is challenging. This paper shows how to leverage recent advances in NLP and multi-modal learning to augment a pre-trained model with search engine retrieval. We propose to retrieve useful data from the Web at test time based on test cases that the model is uncertain about. Different from existing retrieval-augmented approaches, we then update the model to address this underlying uncertainty. We demonstrate substantial improvements in zero-shot performance, e.g. a remarkable increase of 15 percentage points in accuracy on the Stanford Cars and Flowers datasets. We also present extensive experiments that explore the impact of noisy retrieval and different learning strategies.
Q-Seg: Quantum Annealing-based Unsupervised Image Segmentation
Nov 30, 2023In this study, we present Q-Seg, a novel unsupervised image segmentation method based on quantum annealing, tailored for existing quantum hardware. We formulate the pixel-wise segmentation problem, which assimilates spectral and spatial information of the image, as a graph-cut optimization task. Our method efficiently leverages the interconnected qubit topology of the D-Wave Advantage device, offering superior scalability over existing quantum approaches and outperforming state-of-the-art classical methods. Our empirical evaluations on synthetic datasets reveal that Q-Seg offers better runtime performance against the classical optimizer Gurobi. Furthermore, we evaluate our method on segmentation of Earth Observation images, an area of application where the amount of labeled data is usually very limited. In this case, Q-Seg demonstrates near-optimal results in flood mapping detection with respect to classical supervised state-of-the-art machine learning methods. Also, Q-Seg provides enhanced segmentation for forest coverage compared to existing annotated masks. Thus, Q-Seg emerges as a viable alternative for real-world applications using available quantum hardware, particularly in scenarios where the lack of labeled data and computational runtime are critical.
Brainformer: Modeling MRI Brain Functions to Machine Vision
Nov 30, 2023"Perception is reality". Human perception plays a vital role in forming beliefs and understanding reality. Exploring how the human brain works in the visual system facilitates bridging the gap between human visual perception and computer vision models. However, neuroscientists study the brain via Neuroimaging, i.e., Functional Magnetic Resonance Imaging (fMRI), to discover the brain's functions. These approaches face interpretation challenges where fMRI data can be complex and require expertise. Therefore, neuroscientists make inferences about cognitive processes based on patterns of brain activities, which can lead to potential misinterpretation or limited functional understanding. In this work, we first present a simple yet effective Brainformer approach, a novel Transformer-based framework, to analyze the patterns of fMRI in the human perception system from the machine learning perspective. Secondly, we introduce a novel mechanism incorporating fMRI, which represents the human brain activities, as the supervision for the machine vision model. This work also introduces a novel perspective on transferring knowledge from human perception to neural networks. Through our experiments, we demonstrated that by leveraging fMRI information, the machine vision model can achieve potential results compared to the current State-of-the-art methods in various image recognition tasks.
DNS SLAM: Dense Neural Semantic-Informed SLAM
Nov 30, 2023

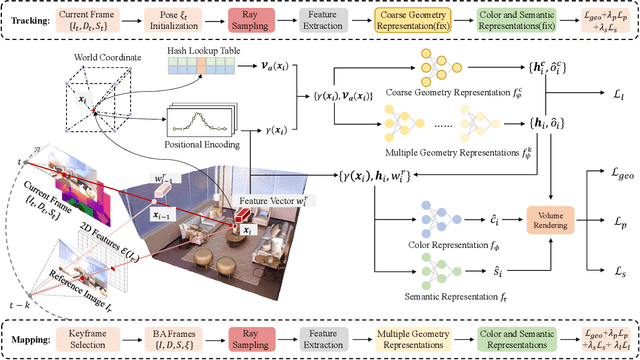
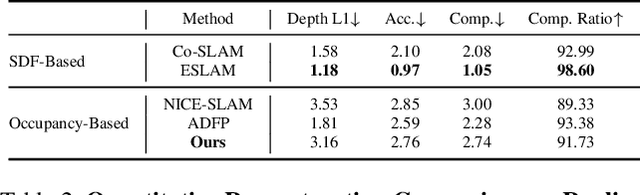
In recent years, coordinate-based neural implicit representations have shown promising results for the task of Simultaneous Localization and Mapping (SLAM). While achieving impressive performance on small synthetic scenes, these methods often suffer from oversmoothed reconstructions, especially for complex real-world scenes. In this work, we introduce DNS SLAM, a novel neural RGB-D semantic SLAM approach featuring a hybrid representation. Relying only on 2D semantic priors, we propose the first semantic neural SLAM method that trains class-wise scene representations while providing stable camera tracking at the same time. Our method integrates multi-view geometry constraints with image-based feature extraction to improve appearance details and to output color, density, and semantic class information, enabling many downstream applications. To further enable real-time tracking, we introduce a lightweight coarse scene representation which is trained in a self-supervised manner in latent space. Our experimental results achieve state-of-the-art performance on both synthetic data and real-world data tracking while maintaining a commendable operational speed on off-the-shelf hardware. Further, our method outputs class-wise decomposed reconstructions with better texture capturing appearance and geometric details.
Hubness Reduction Improves Sentence-BERT Semantic Spaces
Nov 30, 2023Semantic representations of text, i.e. representations of natural language which capture meaning by geometry, are essential for areas such as information retrieval and document grouping. High-dimensional trained dense vectors have received much attention in recent years as such representations. We investigate the structure of semantic spaces that arise from embeddings made with Sentence-BERT and find that the representations suffer from a well-known problem in high dimensions called hubness. Hubness results in asymmetric neighborhood relations, such that some texts (the hubs) are neighbours of many other texts while most texts (so-called anti-hubs), are neighbours of few or no other texts. We quantify the semantic quality of the embeddings using hubness scores and error rate of a neighbourhood based classifier. We find that when hubness is high, we can reduce error rate and hubness using hubness reduction methods. We identify a combination of two methods as resulting in the best reduction. For example, on one of the tested pretrained models, this combined method can reduce hubness by about 75% and error rate by about 9%. Thus, we argue that mitigating hubness in the embedding space provides better semantic representations of text.
MotionEditor: Editing Video Motion via Content-Aware Diffusion
Nov 30, 2023Existing diffusion-based video editing models have made gorgeous advances for editing attributes of a source video over time but struggle to manipulate the motion information while preserving the original protagonist's appearance and background. To address this, we propose MotionEditor, a diffusion model for video motion editing. MotionEditor incorporates a novel content-aware motion adapter into ControlNet to capture temporal motion correspondence. While ControlNet enables direct generation based on skeleton poses, it encounters challenges when modifying the source motion in the inverted noise due to contradictory signals between the noise (source) and the condition (reference). Our adapter complements ControlNet by involving source content to transfer adapted control signals seamlessly. Further, we build up a two-branch architecture (a reconstruction branch and an editing branch) with a high-fidelity attention injection mechanism facilitating branch interaction. This mechanism enables the editing branch to query the key and value from the reconstruction branch in a decoupled manner, making the editing branch retain the original background and protagonist appearance. We also propose a skeleton alignment algorithm to address the discrepancies in pose size and position. Experiments demonstrate the promising motion editing ability of MotionEditor, both qualitatively and quantitatively.